

Alibaba Cloud Elastic MapReduce (EMR) is a big data processing solution that runs on the Alibaba Cloud platform. EMR is built on Alibaba Cloud ECS instances and is based on open-source Apache Hadoop and Apache Spark. EMR allows you to use the Hadoop and Spark ecosystem components, such as Apache Hive, Apache Kafka, Flink, Druid, and TensorFlow, to analyze and process data. You can use EMR to process data stored on different Alibaba Cloud data storage service, such as Object Storage Service (OSS), Log Service (SLS), and Relational Database Service (RDS).
Benefits

-
Easy-to-use
You can quickly create clusters without the need to configure hardware and software. All maintenance operations are completed on its Web interface.

-
Cost-effectiveness
You can create clusters and dynamically scale in and out the number of compute nodes based on current computing needs.

-
Stability
EMR provides a deeply optimized cluster environment, automated background maintenance, and multiple online support channels.

-
Security
EMR supports Kerberos authentication and data encryption. You can use RAM users to refine the management of service permissions.
Features
Automated Cluster Deployment and Expansion
You can quickly deploy and expand clusters from a Web interface without the need to manage the hardware and software.
Cluster Creation
You can quickly deploy multiple types of clusters, such as Hadoop, Kafka, Druid, and ZooKeeper.
Cluster Expansion
You can quickly add any types of nodes to the existing clusters.
Scheduled Cluster Creation
You can execute plans to create clusters, execute jobs at the scheduled time, and release clusters after job execution.
Automatic Component Deployment
You can add, configure, and maintain components based on your needs.
Dynamic Expansion
You can scale in and out cluster compute resources at the specified time to reduce the total cost of ownership (TCO).
Workflow Scheduling
EMR offers simple job orchestration and scheduling.
Job Editing and Management
EMR supports graphical job editing and management for you to execute and orchestrate multiple types of jobs.
Workflow Scheduling
EMR supports job and dependency scheduling. You can orchestrate and schedule jobs as DAG-based workflows.
Dynamic Clusters
You can use EMR to start a temporary cluster to execute jobs at the scheduled time and stop the cluster after job execution.
Guaranteed Job Execution
When EMR fails to execute a job, it immediately sends an alarm. You can also set EMR to automatically re-execute the job.
Multiple Components
EMR provides multiple components.
Hadoop
A big data processing platform with petabytes of storage capacity and compute capability.
Spark
A memory-based new-generation distributed computing framework that supports offline and real-time computing, SQL syntax, and machine learning.
Hive
An offline data processing system based on Hadoop. Hive supports structured table management based on Hadoop Distributed File System (HDFS) and provides query syntax that is similar to SQL for data analysis and processing.
Kafka
A high-throughput and reliable distributed message publication and subscription system.
Storm
A real-time compute engine that supports real-time data processing within milliseconds.
ZooKeeper
A distributed and open-source coordination service that can ensure the consistency of distributed applications.
Hue
A management tool and Web interface.
Oozie
An open-source job scheduling tool.
Druid
An open-source real-time big data analysis software.
Flink
A distributed engine for batch processing and stream processing.
Complete Ecosystem Support
EMR is deeply integrated with Alibaba Cloud services.
Support for OSS
You can use Object Storage Service (OSS) as HDFS in most of the EMR components.
Support for SLS
EMR provides an SDK which allows you to input real-time data (RTD) from Log Service (SLS).
Support for Elasticsearch
Hadoop carries a built-in ES-Hadoop plug-in which supports all Elasticsearch operations.
Support for MaxCompute
EMR supports reading and writing Alibaba Cloud MaxCompute data.
Support for Alibaba Cloud Message Services
EMR supports reading and writing data from Alibaba Cloud message services, such as Message Queue and Message Service, and supports SDK integration.
Scenarios




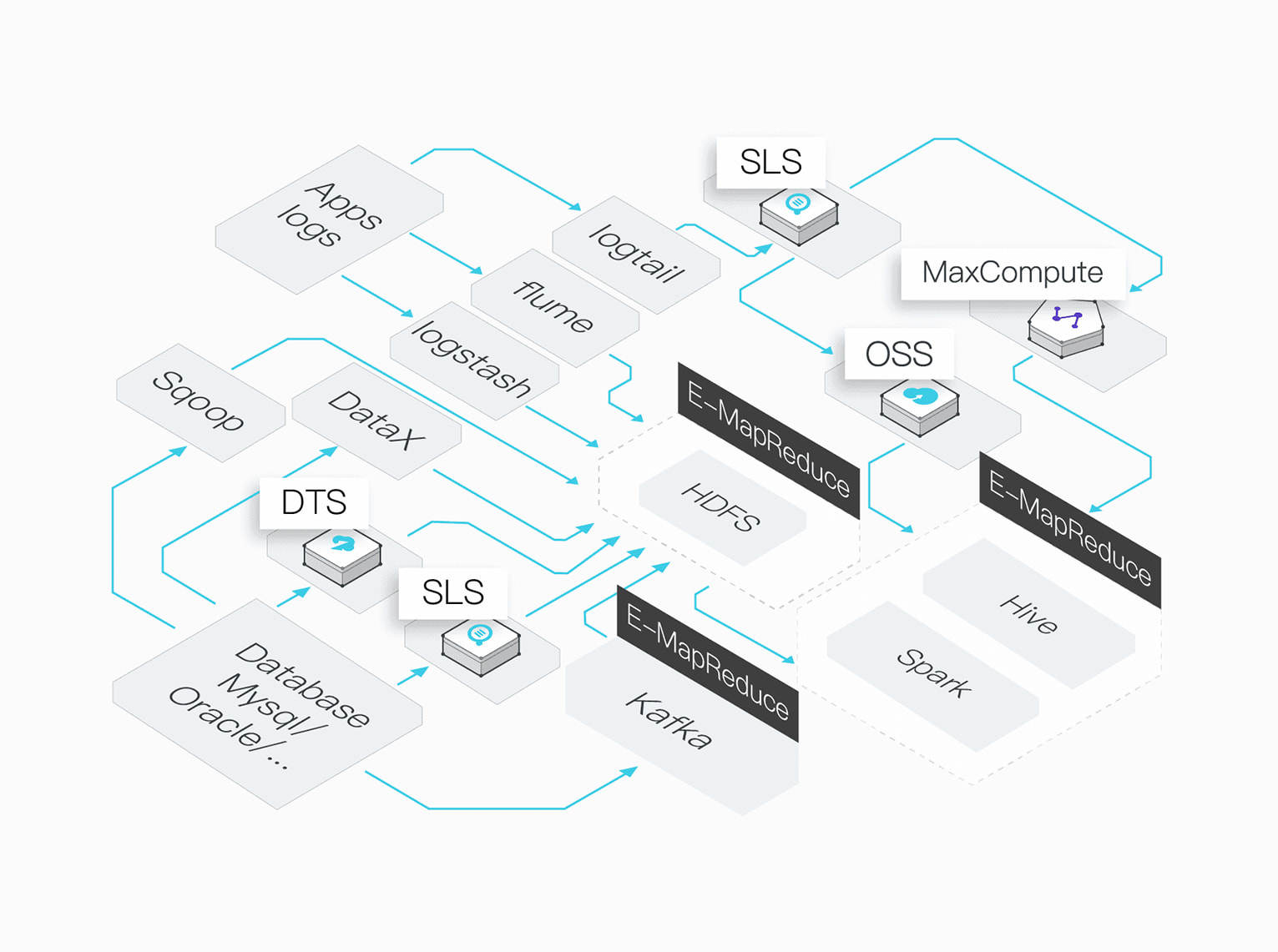
Data Integration
EMR offers multiple data integration methods.
You can integrate open-source, offline, real-time, and Alibaba Cloud-developed data integration tools into EMR.
Benefits
File Data
EMR supports the real-time collection of logs and other text.
Databases
EMR supports batch and real-time data analysis from databases.
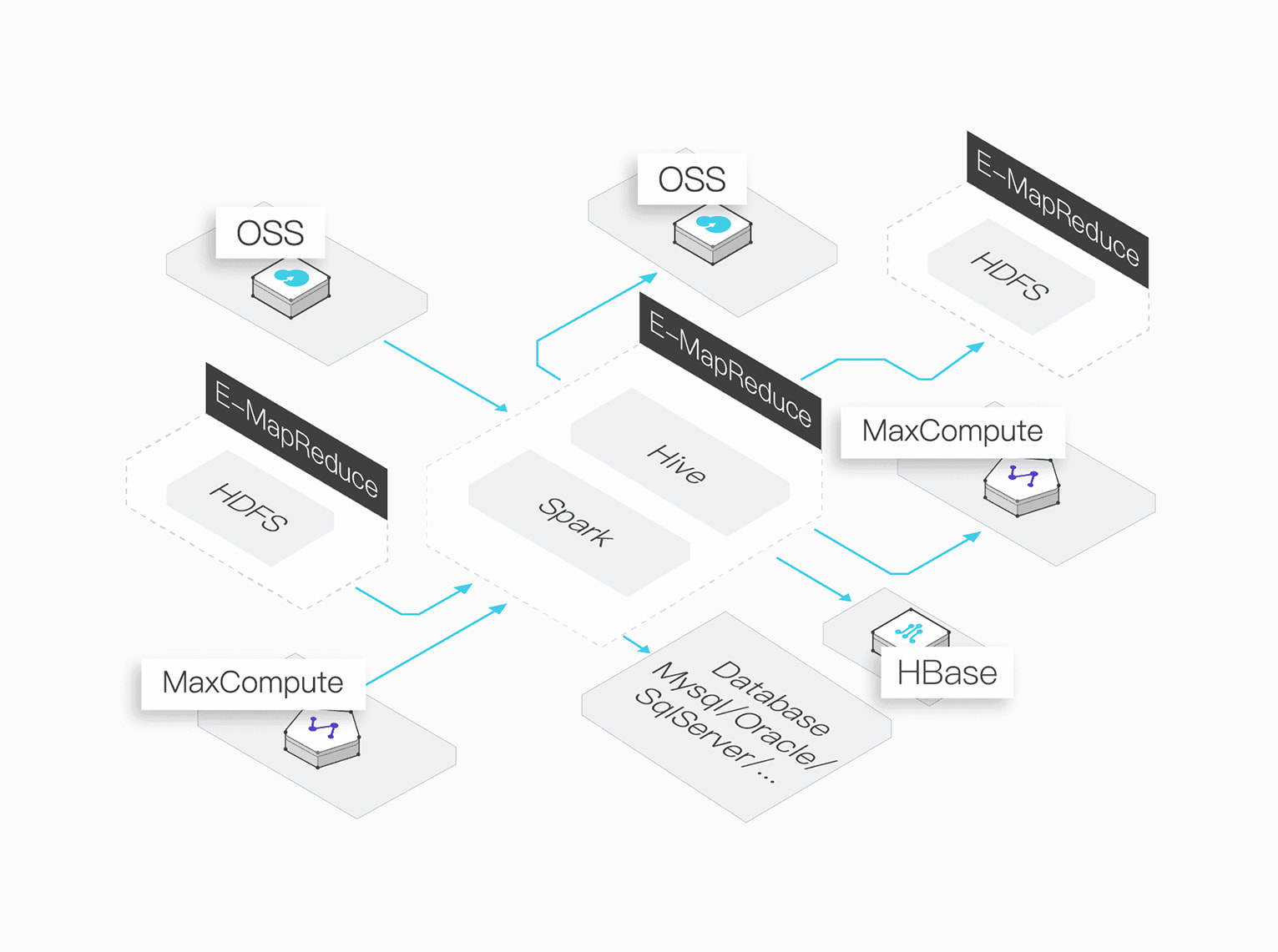
Offline Computing
Offline Processing Mode for Flexibility and Cost-effectiveness
EMR supports multiple compute engines, including Hive, Pig, Spark, SparkSQL, and Tez. It also allows you to access and use data stored on different storage services.
Benefits
Multiple Compute Engines
EMR supports multiple compute engines, including MR, Hive, Pig, Spark, and Tez.
Support for Multiple Data Sources
EMR supports reading data from data sources such as OSS, HDFS, MaxCompute, and Kafka.
Support for Multiple Data Targets
EMR allows you to write compute results to various software in multiple formats.
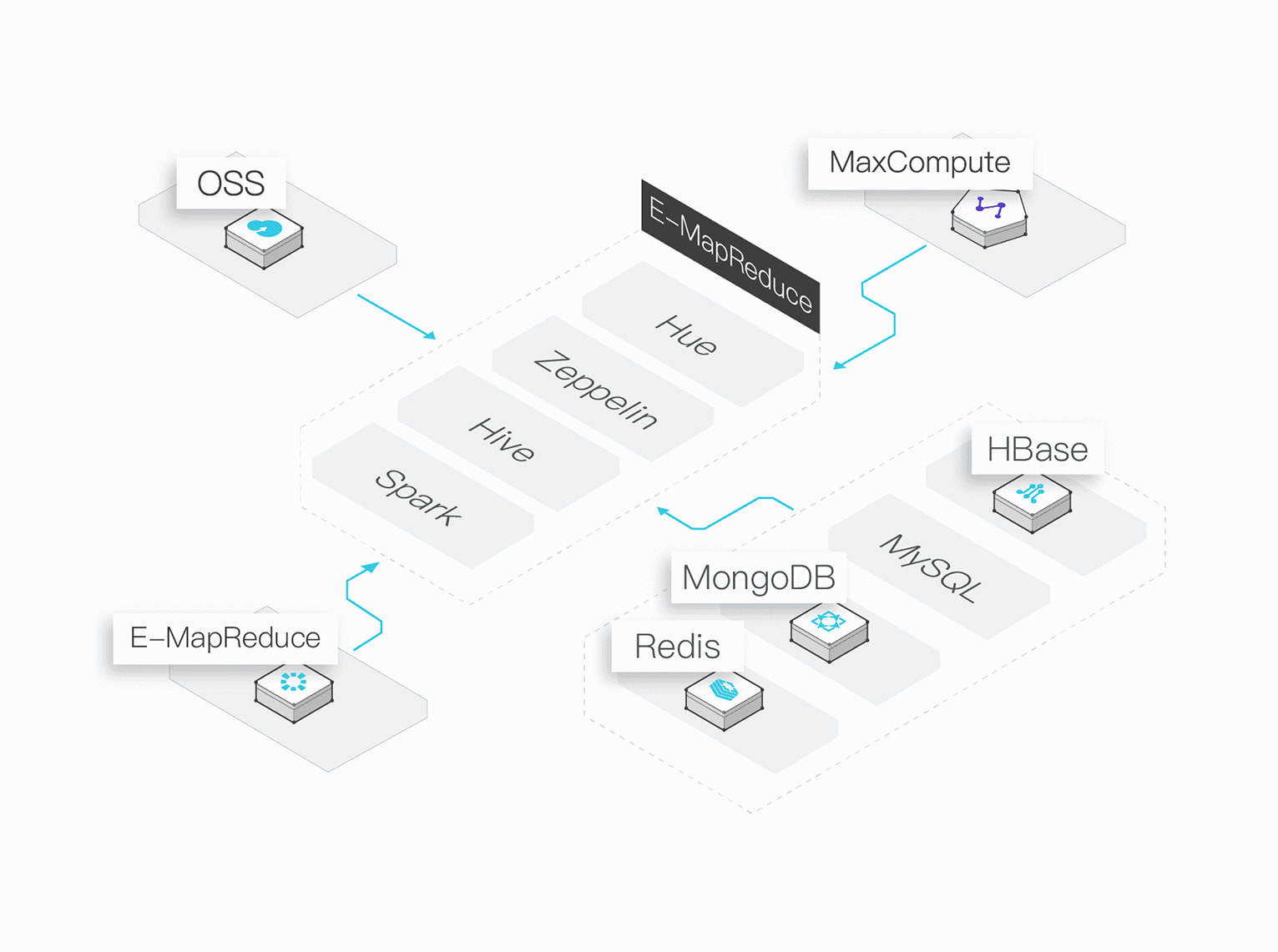
Ad Hoc Data Analysis
EMR supports flexible and fast data analysis
Based on the scalability of Alibaba Cloud, you can quickly create a Hadoop cluster to analyze data and release the cluster after the task is complete.
Benefits
Elastic Clusters
You can use EMR to quickly build a temporary Hadoop cluster to analyze data and release the cluster after the task is complete.
Elastic Compute Capability
You can customize the number of compute nodes in clusters based the compute task needs.
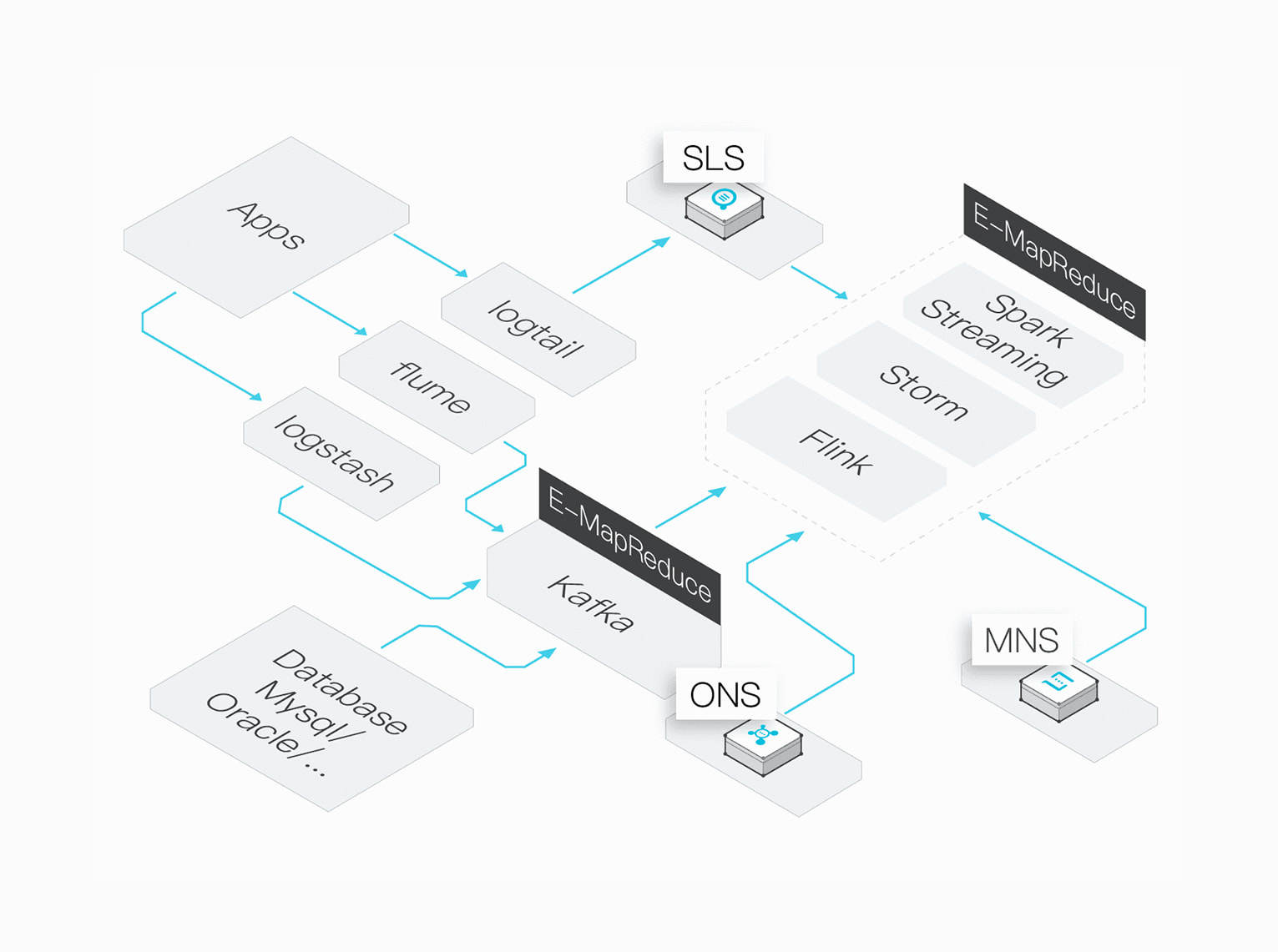
Stream Computing
EMR provides flexible, reliable, and stable real-time computing.
EMR supports multiple real-time data sources, all solutions in open-source communities, and Alibaba Cloud solutions.
Benefits
Support for Multiple Data Sources
You can read data from system logs and the binary log.
Multiple Compute Engines
EMR supports Spark Streaming, Storm, and Flink.
Upgraded Support For You
1 on 1 Presale Consultation, 24/7 Technical Support, Faster Response, and More Free Tickets.
1 on 1 Presale Consultation

24/7 Technical Support

6 Free Tickets per Quarter











