Alibaba Cloud は、幅広いクラウドストレージとデータベースサービスを提供します。 これらのサービスに保存されているデータの分析や検索をする場合、Data Integration を使用してデータを Elasticsearch にレプリケートしてから、データのクエリや分析をします。 Data Integration を使用すると、最小 5 分間隔でデータをレプリケートできます。
前提条件
オンプレミスデータの分析や検索をするには、次の手順に従います。
-
テーブルの作成と表示 、およびデータのインポートを行います。 Hadoop から MaxCompute へデータを移行してから、データを同期します。 この例では、以下のテーブルスキームとデータを使用します。
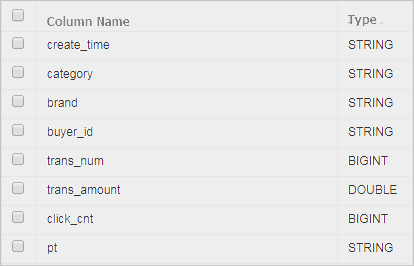
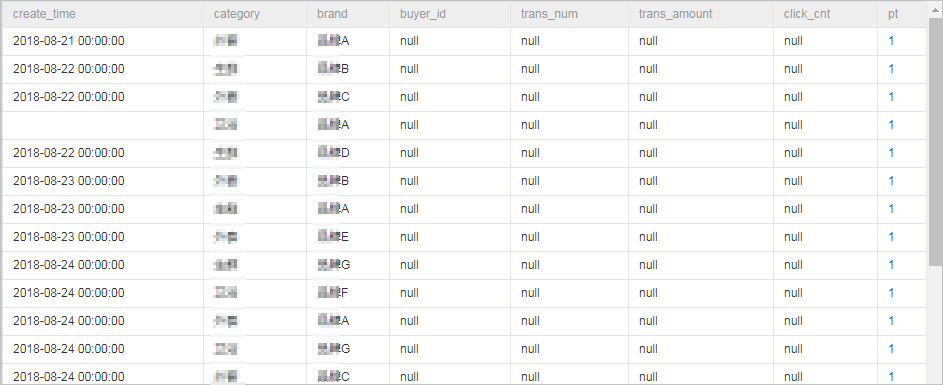
-
Data Integration でレプリケートされたデータを保存するための Elasticsearch インスタンスを作成します。
-
Elasticsearch と同じ VPC を共有する ECS インスタンスを購入します。 この ECS インスタンスでデータを取得し、Elasticsearch タスクを実行します (これらのタスクは、Data Integration によって送信されます)。
-
Data Integration を有効化し、タスクを実行可能なリソースとして ECS インスタンスを Data Integration に登録します。
-
データ同期スクリプトを設定し、定期的に実行します。


手順
- Elasticsearch インスタンスと ECS インスタンスの作成
-
IPv4 VPC の作成を行います。 この例では、VPC を中国 (杭州) リージョンに作成します。 インスタンス名は es_test_vpc、VSwitch 名は es_test_switch です。
-
Elasticsearch コンソールにログインし 、Elasticsearch インスタンスを作成します。注 前の手順で作成した VPC と同じリージョン、VPC、 VSwitch を選択するようにします。
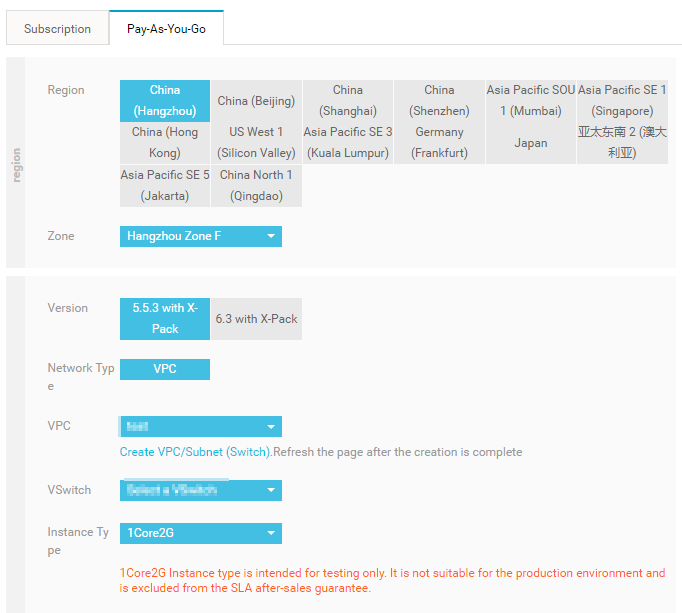
-
Elasticsearch インスタンスと同じ VPC にある ECS インスタンスを購入し、パブリック IP アドレスを割り当てるか、EIP を有効化します。 コストを節約するため、要件を満たす既存の ECS インスタンスを使用することを推奨します。
この例では、杭州 (中国東部1) ゾーン F に ECS インスタンスを作成します。 [64-bit CentOS 7.4] と [パブリック IP の割り当て] を選択して、ネットワークを設定します (次図)。
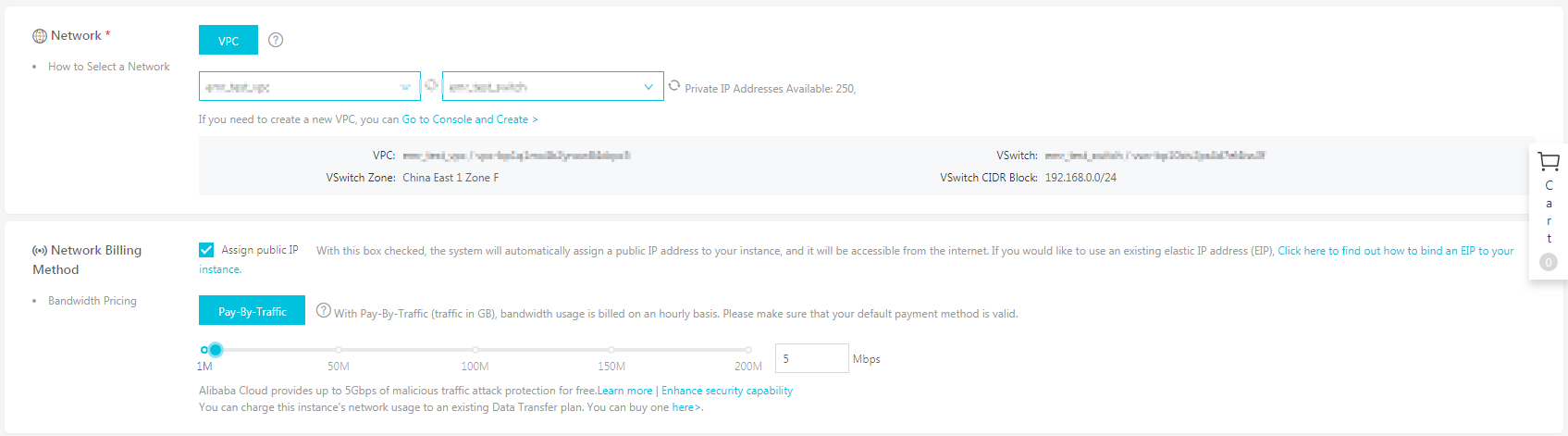 注
注- CentOS 6、CentOS 7、または Aliyun Linux を使用することを推奨します。
- ECS インスタンスで MaxCompute タスクまたはデータ同期タスクを実行する場合、ECS インスタンスの Python バージョンが 2.6 か 2.7 であることを確認する必要があります。 CentOS 5 をインストールすると、Python 2.4 もインストールされます。 他の CentOS バージョンの Python は 2.6 以降です。
- ECS インスタンスにパブリック IP アドレスが割り当てられていることを確認します。
-
- データ同期タスクの設定
-
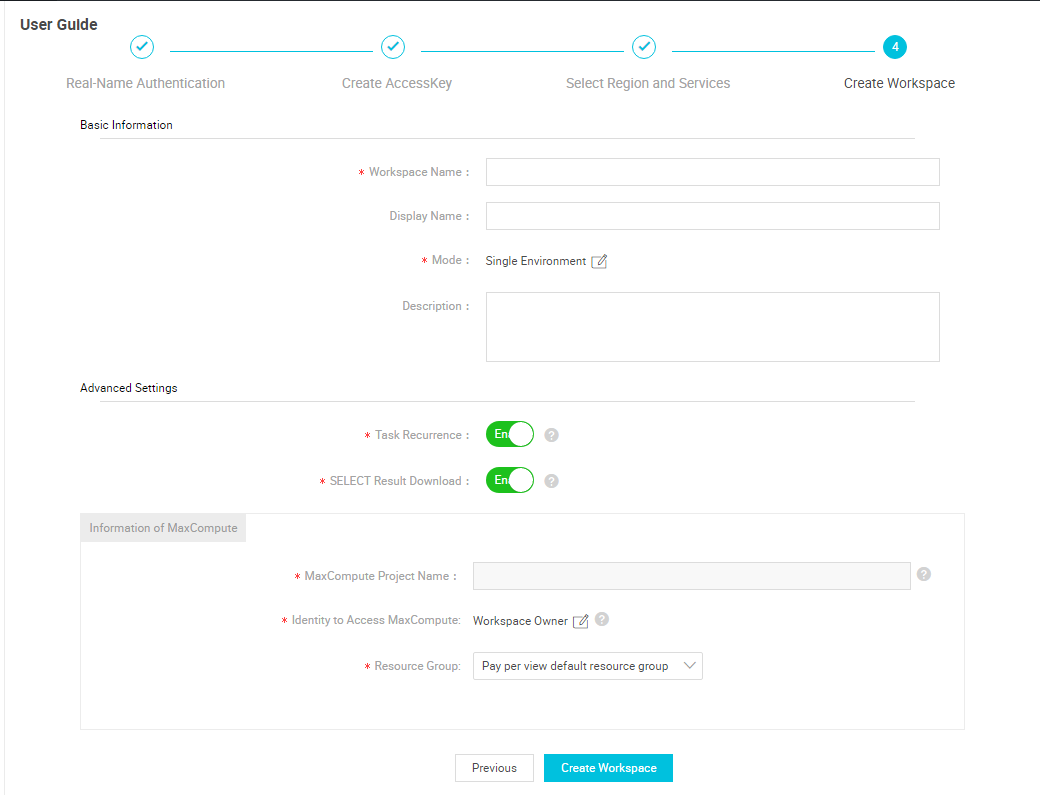
DataWorks コンソールにログインしてプロジェクトを作成します。 この例では、 bigdata_DOC という名前の DataWorks プロジェクトを使用します。
- Data Integration が既に有効化されている場合、次のページが表示されます。
- Data Integration が有効化されていない場合、次のページが表示されます。Data Integration を有効化するには、次の手順を実行します。 このサービスを有効化すると、料金が発生します。料金設定ルールに基づいて見積もることができます。
- Data Integration が既に有効化されている場合、次のページが表示されます。
-
DataWorks プロジェクトの下にある [Data Integration] をクリックします。
-
リソースグループを作成します。
-
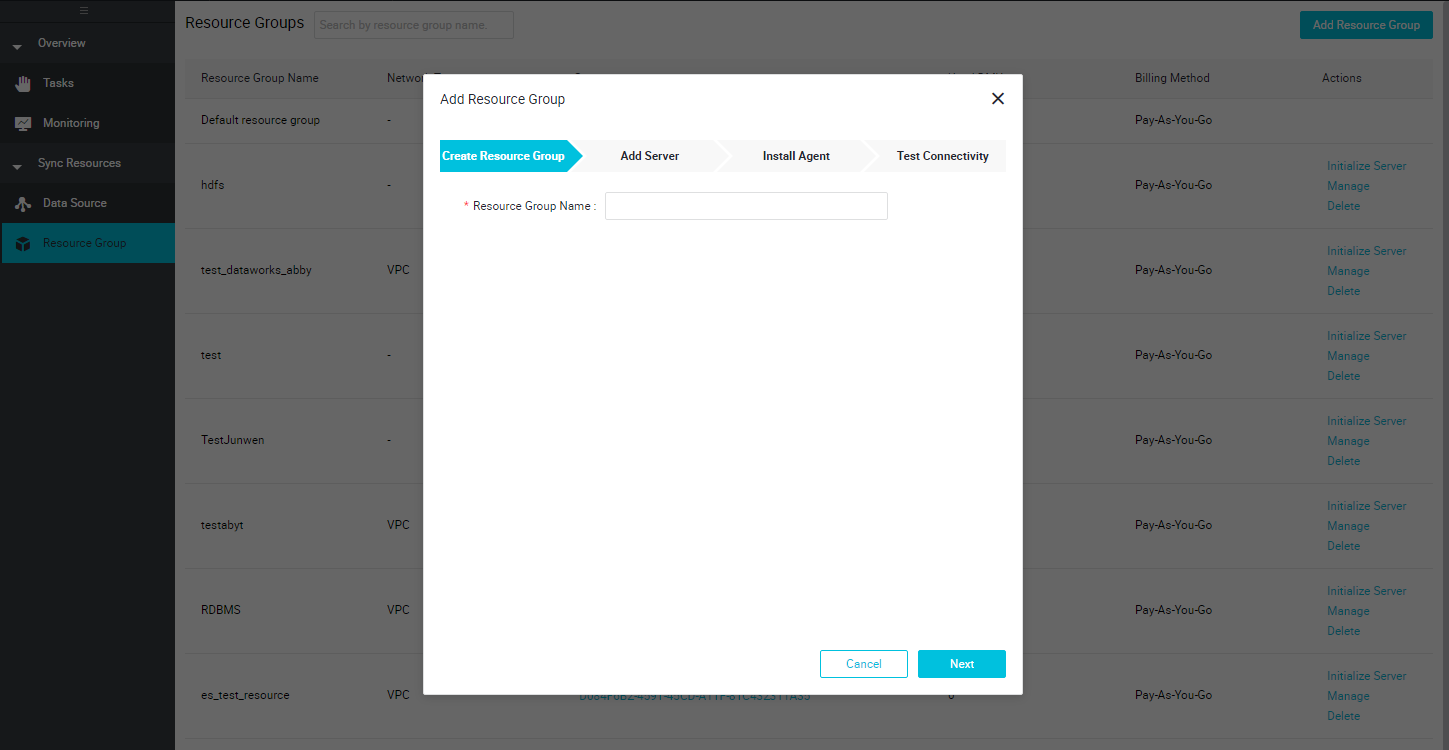
[Data Integration] ページの左側のナビゲーションウィンドウで、[Resource Group] を選択し、[Add Resource Group] をクリックします。
-
リソースグループを追加するには、次の手順に従います。
- リソースグループを作成します。リソースグループ名を入力します。 この例では、リソースグループに es_test_resource という名前を付けます。
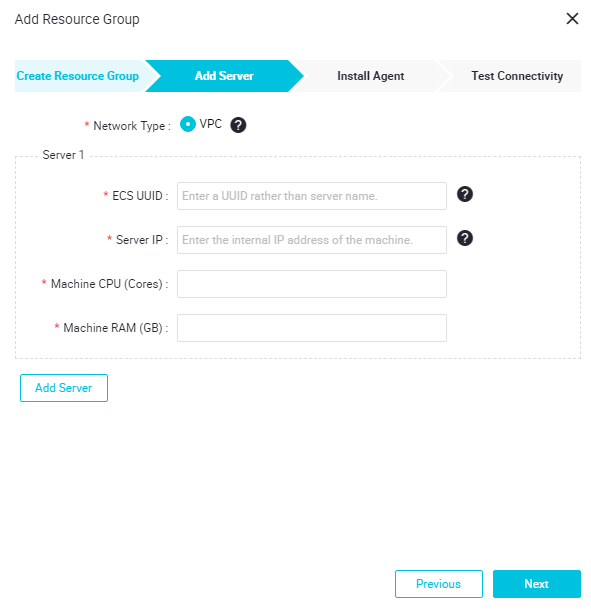
- サーバーを追加します。
-
ECS UUID:手順 3: インスタンスへの接続。 ECS インスタンスにログインし、
dmidecode | grep UUIDコマンドを実行して戻り値を取得します。
-
Machine IP/Machine CPU (Cores)/Memory Size (GB):ECS インスタンスのパブリック IP アドレス、CPU コア、メモリサイズを指定します。 ECS コンソーにログインし、ECS インスタンス名をクリックすると、[設定情報] に、情報が表示されます。
-
- エージェントをインストールします。次の手順に従って、エージェントのインストールを完了します。 この例では、VPC を使用します。 したがって、インスタンスのポート 8000 を開く必要はありません。
- 接続を確認します。接続が正常に確立されると、ステータスが [Available] に変わります。 ステータスが [Unavailable] の場合、ECS インスタンスにログインし、
tail -f /home/admin/alisatasknode/logs/heartbeat.logコマンドを実行して DataWorks と ECS インスタンス間のハートビートメッセージがタイムアウトしたかどうかを確認します。
- リソースグループを作成します。リソースグループ名を入力します。 この例では、リソースグループに es_test_resource という名前を付けます。
-
-
データソースを追加します。
-
[Data Integration] ページの左側のナビゲーションウィンドウで、[Data Source] を選択し、[Add Data Source] をクリックします。
-
ソースタイプとして [MaxCompute] を選択します。
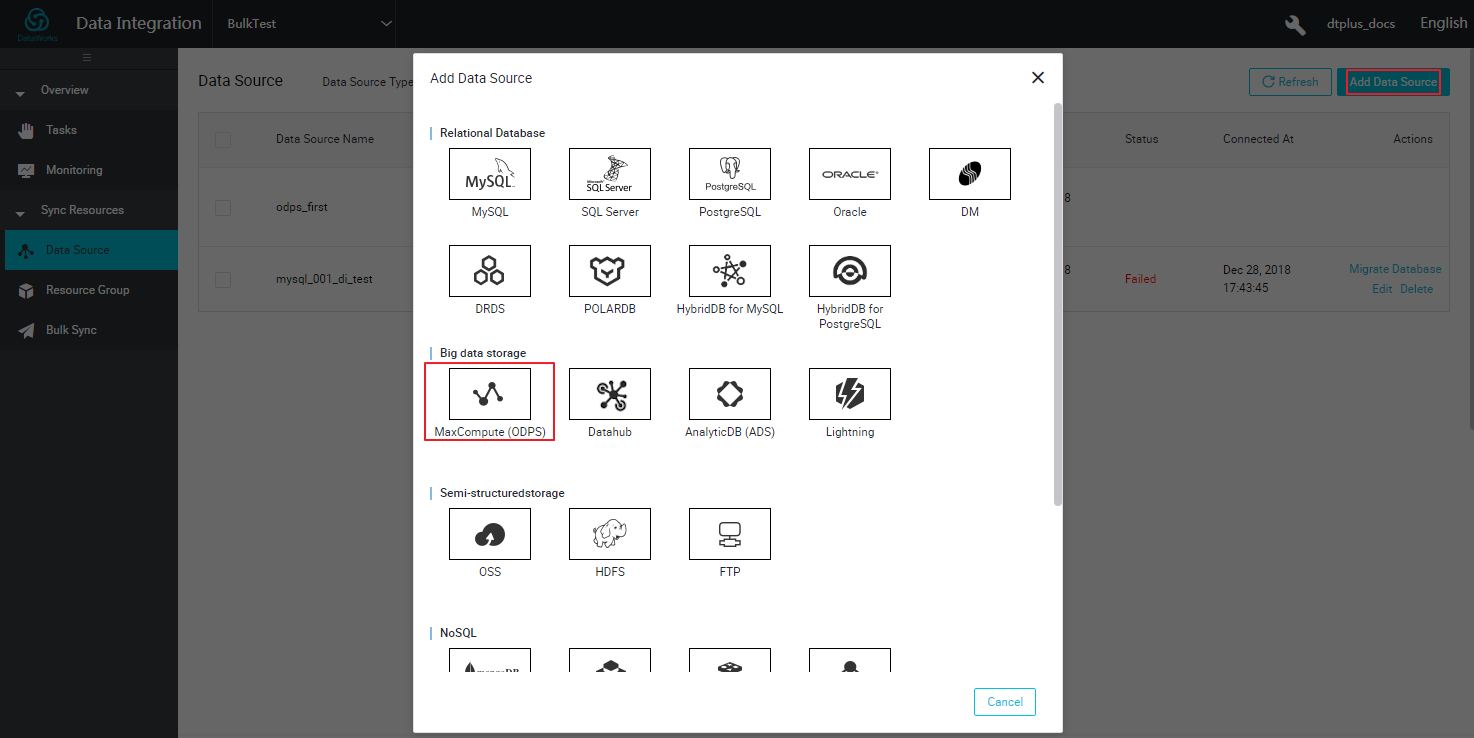
-
データソースに関する情報を入力します。 この例では、odps_es という名前のデータソースを作成します (次図)。
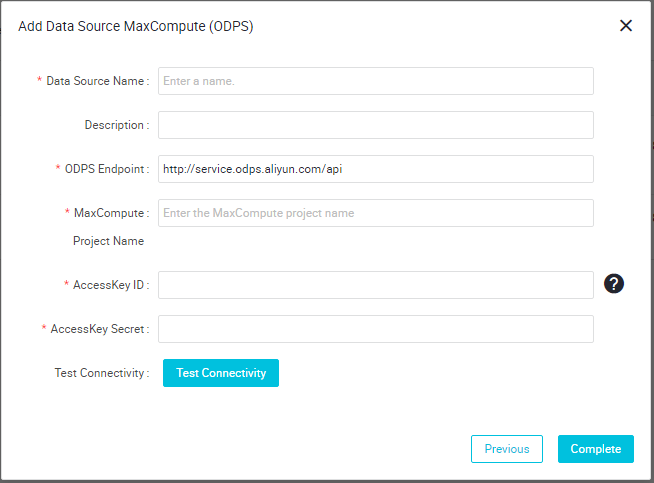
-
ODPS workspace name:DataWorks の [Data Analytics] ページの左上隅のアイコンの右側に、テーブルのワークスペース名が表示されます (次図) 。
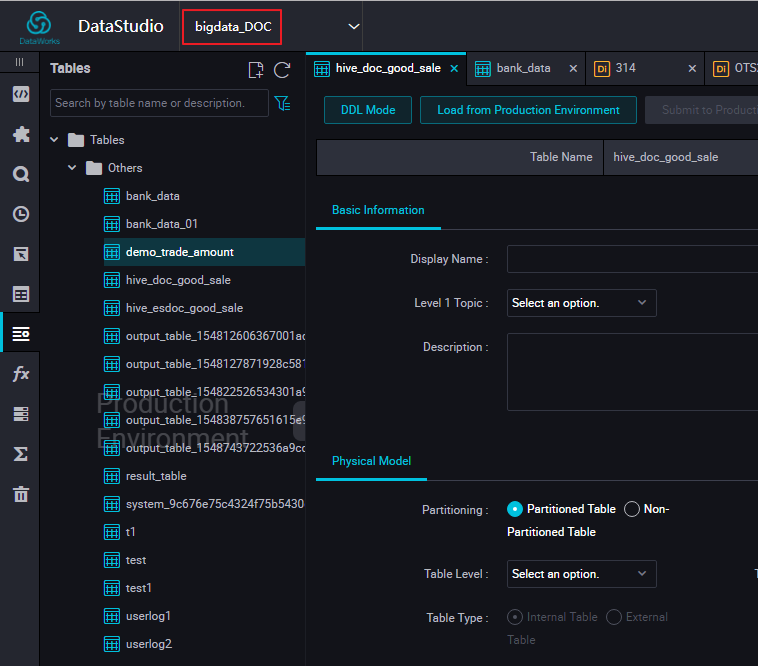
-
AccessKeyId /AccessKeySecrete:ユーザー名の上にポインターを移動し、[User Info] を選択します (次図)。
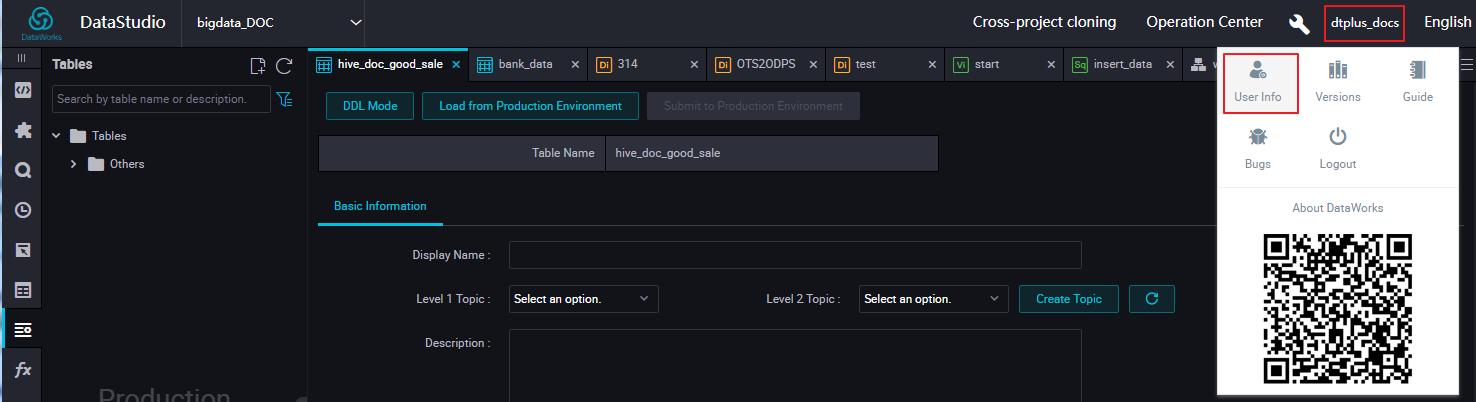 [Personal Account] ページでアバターの上にポインターを移動し、[accesskeys] をクリックします (次図)。
[Personal Account] ページでアバターの上にポインターを移動し、[accesskeys] をクリックします (次図)。
-
-
-
同期タスクを設定します。
- [Data Analytics] ページの左側のナビゲーションウィンドウで、[Data Analytics] アイコンをクリックし、[Business Flow] をクリックします。
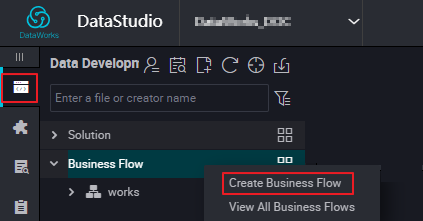
- ターゲットビジネスフローをクリックし、[Data Integration] を選択し、 を選択してから、同期ノード名を入力します。
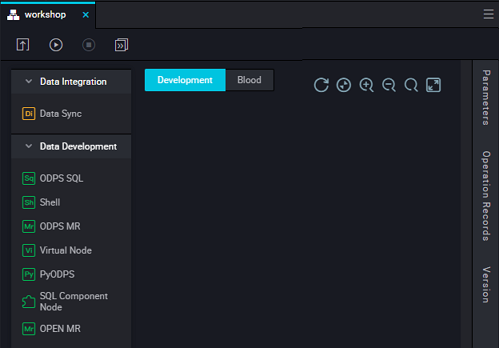
- 同期ノードが正常に作成されたら、新しい同期ノードページの上部にある [Switch to Script Mode] アイコンをクリックし、[Confirm] を選択します。

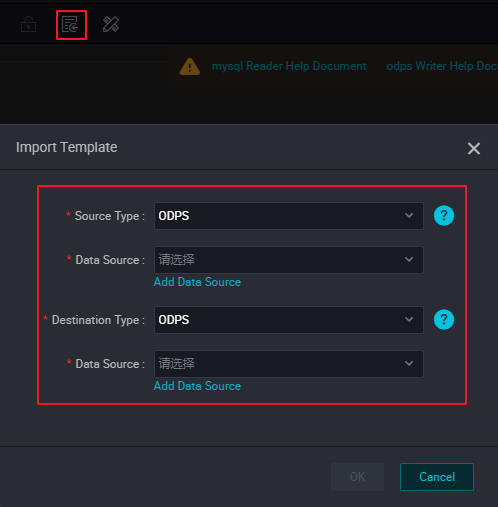
- [Script Mode] ページの上部にある [Apply Template] アイコンをクリックします。 [Source Type]、[Data Source]、[Destination Type]、[Data Source] のオプションに情報を入力し、[OK] をクリックして初期スクリプトを生成します。
-
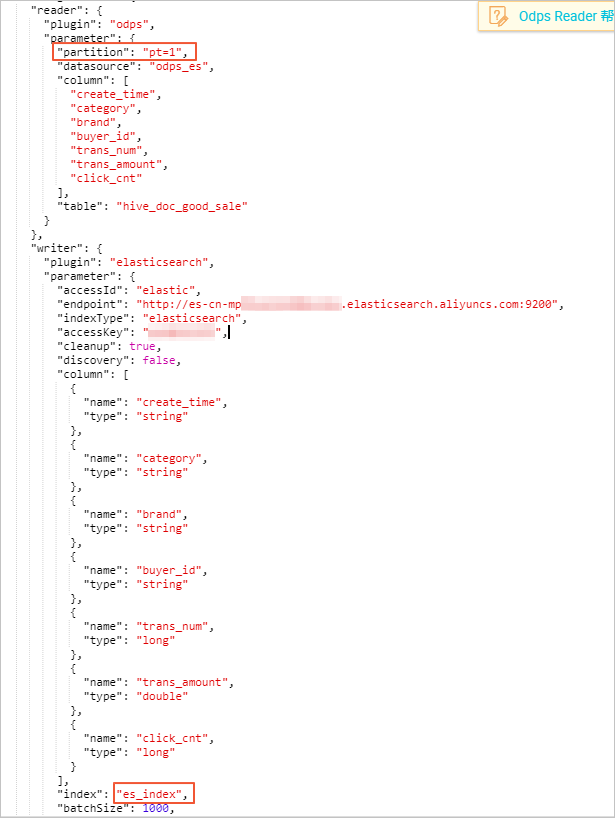
データ同期スクリプトの設定を行います。 Elasticsearch の設定ルールの詳細は、「writer プラグインの設定」をご参照ください。
 注
注- 同期スクリプトの設定には、Reader、Writer、Setting の 3 つの部分があります。 Reader では、データを同期するソースクラウドサービスを設定します。 Write では、Elasticsearch の設定ファイルを設定します。 Setting では、パケットロスと最大同時タスクを設定します。
- Endpoint には、Elasticsearch インスタンスのプライベートまたはパブリック IP アドレスを指定します。 この例では、プライベート IP アドレスを使用します。 したがって、ホワイトリストは不要です。 外部 IP アドレスを使用する場合、Elasticsearch の [ネットワークとスナップショット] ページで、Elasticsearch へのアクセスが許可されているパブリック IP アドレスを含むホワイトリストを設定する必要があります。 ホワイトリストには、DataWorks サーバーの IP アドレスと、使用するリソースグループを指定する必要があります。
- Elasticsearch インスタンスへのログインに使用されるユーザー名とパスワードを Elasticsearch Writer の accessId と accesskey に設定する必要があります。
- Elasticsearch インスタンスのインデックス名を index に入力します。 Elasticsearch インスタンスのデータにアクセスするには、このインデックス名を使用する必要があります。 この例では、es_index という名前の インデックスを使用します。
- MaxCompute テーブルがパーティションテーブルの場合、partition フィールドにパーティション情報を設定する必要があります。 この例のパーティション情報は、pt=1 です。
サンプル設定コード:{ "configuration": { "reader": { "plugin": "odps", "parameter": { "partition": "pt=1", "datasource": "odps_es", "column": [ "create_time", "category", "brand", "buyer_id", "trans_num", "trans_amount", "click_cnt" ], "table": "hive_doc_good_sale" } }, "writer": { "plugin": "elasticsearch", "parameter": { "accessId": "elastic", "endpoint": "http://es-cn-mpXXXXXXX.elasticsearch.aliyuncs.com:9200", "indexType": "elasticsearch", "accessKey": "XXXXXX", "cleanup": true, "discovery": false, "column": [ { "name": "create_time", "type": "string" }, { "name": "category", "type": "string" }, { "name": "brand", "type": "string" }, { "name": "buyer_id", "type": "string" }, { "name": "trans_num", "type": "long" }, { "name": "trans_amount", "type": "double" }, { "name": "click_cnt", "type": "long" } ], "index": "es_index", "batchSize": 1000, "splitter": ",", } }, "setting": { "errorLimit": { "record": "0" }, "speed": { "throttle": false, "concurrent": 1, "mbps": "1", "dmu": 1 } } }, "Type": "job ", "version": "1.0" } -
スクリプトが同期されたら、[Run] をクリックして、ODPS データを Elasticsearch と同期させます。

- [Data Analytics] ページの左側のナビゲーションウィンドウで、[Data Analytics] アイコンをクリックし、[Business Flow] をクリックします。
-
- 結果の検証
-
Elasticsearch コンソールにログインし、右上隅の Kibana コンソールをクリックし、[Dev Tools] を選択します。
-
次のコマンドを実行して、データが Elasticsearch に正常にレプリケートされたことを確認します。
POST /es_index/_search? pretty { "query": { "match_all": {}} }es_index は、データ同期中の index フィールドの値です。
データが正常に同期されると、次のページが表示されます。
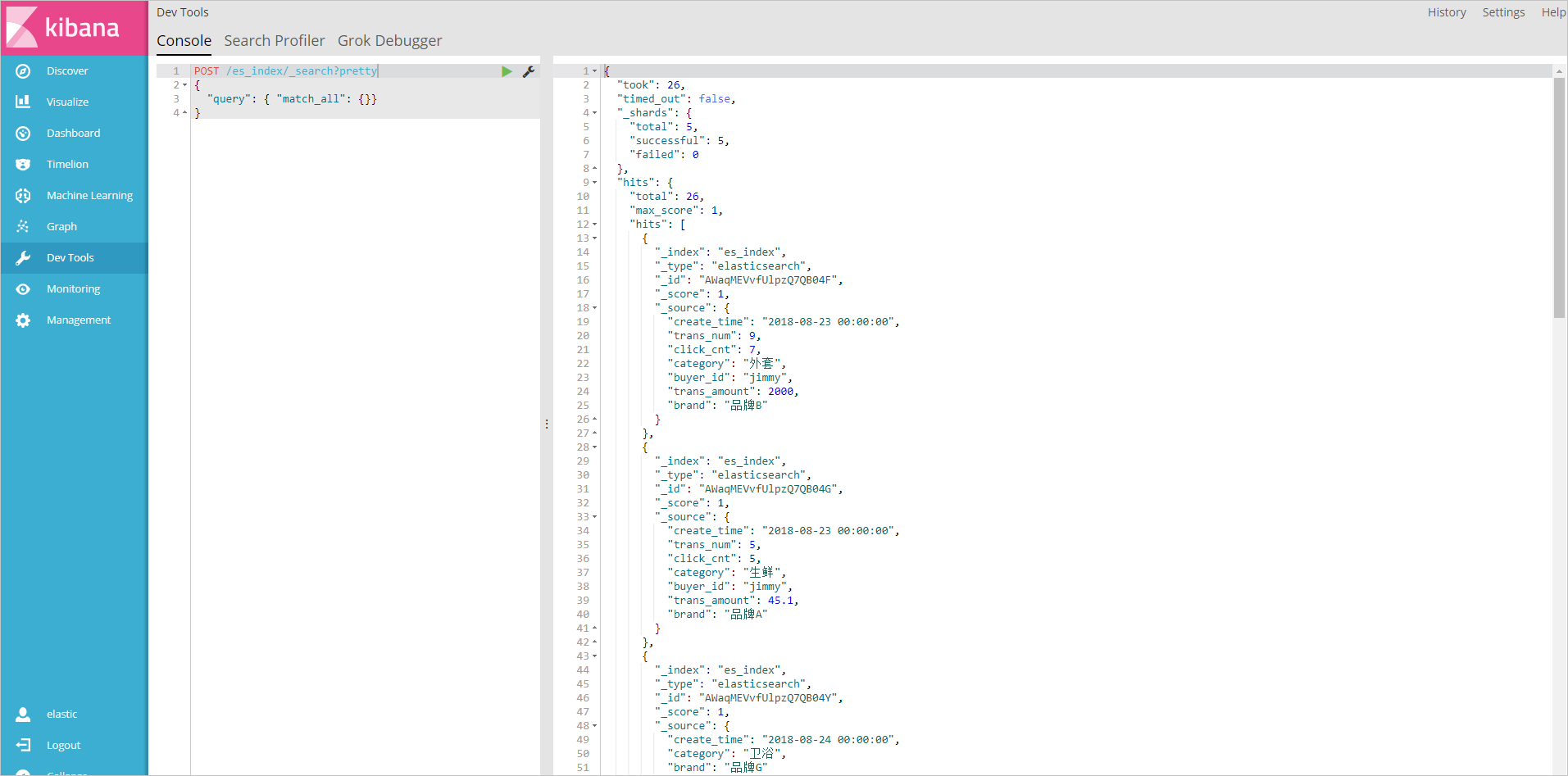
-
次のコマンドを実行して、trans_num フィールドを基準にドキュメントをソートします。
POST /es_index/_search? pretty { "query": { "match_all": {} }, "sort": { "trans_num": { "order": "desc" } } } -
次のコマンドを実行して、ドキュメント内の category フィールドと brand フィールドを検索します。
POST /es_index/_search? pretty { "query": { "match_all": {} }, "_source": ["category", "brand"] } -
次のコマンドを実行して、 category が fresh のドキュメントをクエリします。
POST /es_index/_search? pretty { "query": { "match": {"category":"fresh"} } }詳細は、「Alibaba Cloud Elasticsearch インスタンスへのアクセス」と『Elastic help center』をご参照ください。
-


















よくある質問
Elasticsearch インスタンスに接続するときにエラーが発生します-
同期スクリプトを実行する前に、前の手順で作成したリソースグループが、右側の [configuration tasks resources group] メニューで選択されているかどうかを確認してください。
- リソースグループが選択されている場合、次の手順に進みます。
- リソースグループが選択されていない場合、右側の [configuration tasks resources group] メニューで、作成したリソースグループを選択し、[Run] をクリックします。
-
endpoint、accessId、accesskey など、同期スクリプトの設定が正しいかどうかを確認してください。 endpoint には、Elasticsearch インスタンスのプライベートまたはパブリック IP アドレスを指定します。 パブリック IP アドレスを使用する場合、ホワイトリストを設定してください。 accessId には、Elasticsearch インスタンスへのアクセスに使用されるユーザー名を指定します。デフォルトは elastic です。 accesskey には、Elasticsearch インスタンスへのアクセスに使用されるパスワードを指定します。