時系列クラスタリング関数を使用して、複数の時系列データをクラスタリングし、異なる曲線形状を取得できます。 次に、対応するクラスター中心と、クラスター内のカーブ形状とは異なる形状のカーブをすばやく見つけることができます。
機能一覧
| 機能 | 説明 |
|---|---|
ts_density_cluster |
密度ベースのクラスタリング手法を使用して、複数の時系列データをクラスタリングします。 |
ts_hierarchical_cluster |
階層クラスタリング手法を使用して、複数の時系列データをクラスタリングします。 |
ts_similar_インスタンス |
指定したカーブに似たカーブを照会します。 |
ts_density_cluster
関数の形式:
select ts_density_cluster(x, y, z) 次の表は、各パラメーターの説明です。
| 項目 | 説明 | 値 |
|---|---|---|
| x | 昇順の時間のシーケンス。 | UNIX タイムスタンプ。 単位は秒です。 |
| y | 指定された各時点に対応する数値データのシーケンス。 | N/A |
| z | Theメトリック名データに対応する各指定時点。 | 文字列型 (例: machine01.cpu_usr) 。 |
例:
-
クエリと分析のステートメントは次のとおりです。
* and (h: "machine_01" OR h: "machine_02" OR h: "machine_03") | select ts_density_cluster(stamp, metric_value, metric_name) from (select __time__ - __time_% 600 as stamp, avg(v) tric_value as metric_value, h from log GROUP stamp_me -
以下の図にテスト結果を示します。
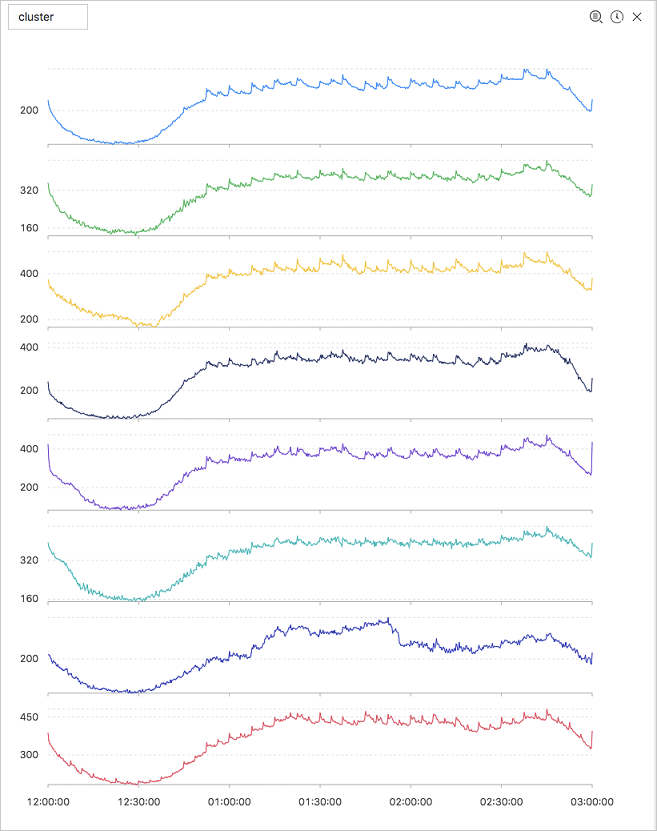
表示項目について、次の表に説明します。
| 表示項目 | 説明 |
|---|---|
| cluster_id | クラスターのカテゴリ。 値-1は、クラスターがどのクラスターセンターにも分類されていないことを示します。 |
| rate | クラスター内のインスタンスの割合。 |
| time_series | クラスターセンターのタイムスタンプシーケンス。 |
| data_series | クラスターセンターのデータシーケンス。 |
| instance_names | クラスターセンターに含まれるインスタンスのコレクション。 |
| sim_instance | クラスター内のインスタンスの名前。 |
ts_hierarchical_cluster
関数の形式:
select ts_hierarchical_cluster(x, y, z) 次の表は、各パラメーターの説明です。
| 項目 | 説明 | 値 |
|---|---|---|
| x | 昇順の時間のシーケンス。 | UNIX タイムスタンプ。 単位は秒です。 |
| y | 指定された各時点に対応する数値データのシーケンス。 | N/A |
| z | 指定された各時点のデータに対応するメトリック名。 | 文字列型 (例: machine01.cpu_usr) 。 |
例:
-
クエリと分析のステートメントは次のとおりです。
* and (h: "machine_01" OR h: "machine_02" OR h: "machine_03") | select ts_hierarchical_cluster(stamp, metric_value, metric_name) from (select __time__ - __time_% 600としてスタンプ、avg(v) tric_valueとして、hとしてmetr -
以下の図にテスト結果を示します。
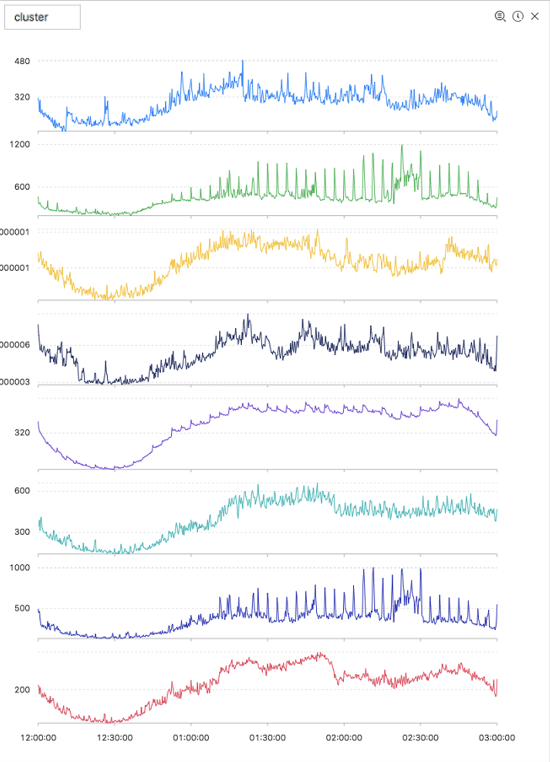
表示項目について、次の表に説明します。
| 表示項目 | 説明 |
|---|---|
| cluster_id | クラスターのカテゴリ。 値-1は、クラスターがどのクラスターセンターにも分類されていないことを示します。 |
| rate | クラスター内のインスタンスの割合。 |
| time_series | クラスターセンターのタイムスタンプシーケンス。 |
| data_series | クラスターセンターのデータシーケンス。 |
| instance_names | Theコレクションのインスタンスで付属クラスタセンター。 |
| sim_instance | The名のインスタンスでクラスタ。 |
ts_similar_instance
関数の形式:
select ts_similar_instance( x, y, z, instance_name, topK, metricType) 次の表は、各パラメーターの説明です。
| 項目 | 説明 | 値 |
|---|---|---|
| x | 昇順の時間のシーケンス。 | UNIX タイムスタンプ。 単位は秒です。 |
| y | 指定された各時点に対応する数値データのシーケンス。 | N/A |
| z | Theメトリック名データに対応する各指定時点。 | 文字列型 (例: machine01.cpu_usr) 。 |
| instance_name | zコレクションで照会される指定されたメトリックの名前。 | 文字列型 (例: machine01.cpu_usr) 。
説明 メトリックは既存のメトリックでなければなりません。 |
| topK | 与えられたカーブと同様のカーブ。 最大K個のカーブが返されます。 | N/A |
| metricType | 時系列曲線間の類似性を測定するために使用されるメトリック。 | {'shape', 'manhattan', 'euclidean'} |
たとえば、クエリと分析のステートメントは次のとおりです。
* およびm: NET and m: Tcp and (h: "nu4e01524.nu8" OR h: "nu2i10267.nu8" OR h: "nu4q10466.nu8") | select ts_similar_instance(stamp, metric_value, metric_name, 'nu4e01524._time 600_as__sum,_____sum,_,______time_time_time_s_time_hとしてmetric_nameログからGROUP BYスタンプ、metric_name注文BY metric_name、スタンプ)表示項目について、次の表に説明します。
| 表示項目 | 説明 |
|---|---|
| instance_name | 指定されたメトリックに似ているメトリックのリスト。 |
| time_series | クラスターセンターのタイムスタンプシーケンス。 |
| data_series | クラスターセンターのデータシーケンス。 |