Alibaba Cloud は、幅広いクラウドストレージとデータベースサービスを提供します。 DataWorks の Data Integration を使用して、ストレージサービスやデータベースサービスと Alibaba Cloud Elasticsearch (ES) との間でデータを同期し、データのクエリや分析をすることができます。 Data Integration を使用すると、最小 5 分間隔でデータを同期できます。
概要
次の手順に従って、データベースに保存されているデータを分析・検索します。
- データベースを作成します。 ApsaraDB RDS for RDS データベースを使用するか、ローカルサーバーにデータベースを作成することができます。 このトピックでは、ApsaraDB
RDS for MySQL データベースを使用します。 2 つの MySQL テーブルを結合してから、データを Elasticsearch と同期します。 次の図に、2
つの MySQL テーブルを示します。
図 1. テーブル 1 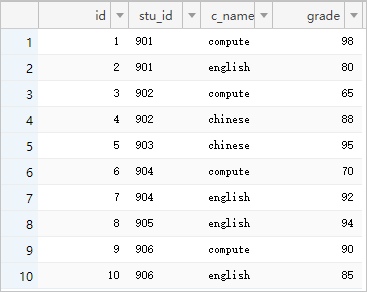
図 2. テーブル 2 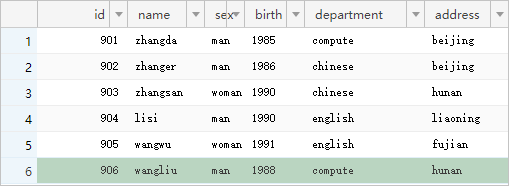
- VPC ネットワークを介して Elasticsearch インスタンスに接続可能な Elastic Compute Service (ECS) インスタンスを購入します。 ECS インスタンスを使用して、MySQL データベースからデータを読み取り、同期タスクを実行して Elasticsearch にデータを書き込みます。 同期タスクは Data Integration によってディスパッチされます。
- Data Integration を有効化し、同期タスクを実行するためのリソースとして ECS インスタンスを Data Integration に追加します。
- データ同期スクリプトを作成し、定期的に実行します。
- Data Integration で同期されたデータを保存するための Elasticsearch インスタンスを作成します。


準備
- VPC ネットワークと VSwitch を作成します。
- Alibaba Cloud Elasticsearch インスタンスの作成を行います。
重要 Elaticsearch インスタンスの [リージョン]、[VPC ネットワーク]、[VSwitch] は、手順 1 で指定したものと同じでなければなりません。
- Elasticsearch インスタンスと同じ VPC ネットワークに接続されている ECS インスタンスを購入し、パブリック IP アドレスか Elastic IP
アドレス (EIP) を割り当てます。
注
- 既存の ECS インスタンスを使用することもできます。
- ECS インスタンスには、CentOS 6、CentOS 7、または AliyunOS を選択することを推奨します。
- ECS インスタンスで MaxCompute または同期タスクを実行する場合、ECS インスタンスが Python V2.6 または V2.7 を実行していることを確認します。 CentOS 5 は Python V2.4 を使用します。 他のオペレーティングシステムは、Python バージョン V2.6 以降を使用します。
- ECS インスタンスにパブリック IP アドレスが割り当てられていることを確認します。
リソースグループの作成とデータソースの追加
- DataWorks コンソールにログインし、[Workspaces] タブをクリックします。
-
Data Integration が既に有効化されている場合、次のページが表示されます。
-
Data Integration が有効化されていない場合、次のページが表示されます。 手順に従って Data Integration を有効化します。 Data Integration は有料サービスです。 ページに表示される課金項目に基づいて料金を見積もることができます。
-
- 購入したワークスペースの [Actions] 列の [Data Integration] をクリックします。
- [Data Integration] ページの左側のナビゲーションペインで [Resource Group] を選択し、右上隅の [Add Resource Group] をクリックします。
- リソースグループを追加します。
- サーバーを追加します。
リソースグループ名を入力し、サーバー情報を指定します。 この例では、購入した ECS インスタンスを追加します。 サーバー情報を次に示します。
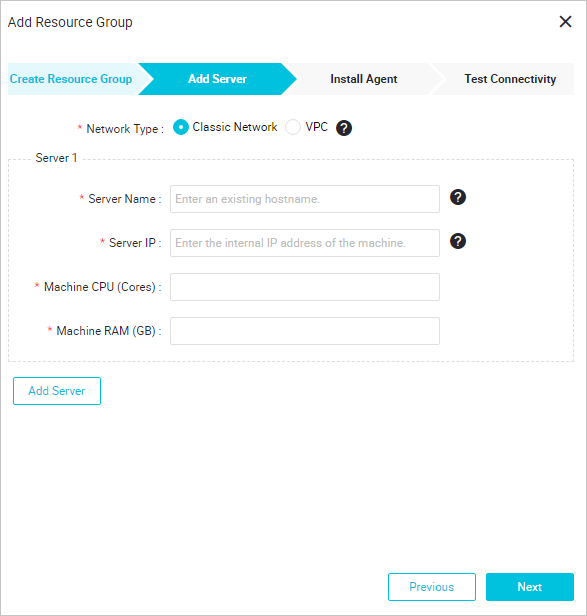
フィールド フィールドの説明 ECS UUID 手順 3: インスタンスへの接続を行い、 dmidecode | grep UUIDを実行します。戻り値をこのフィールドに入力します。Server IP Address/Server CPU (Cores)/Server RAM (GB) ECS インスタンスのパブリック IP アドレス、CPU コア、メモリサイズ。 必要な情報を取得するには、ECS コンソールにログインし、ECS インスタンス名をクリックします。 [設定情報] フィールドに、情報が表示されます。 - Security Center エージェントをインストールします。
ページの指示に従って、エージェントをインストールします。 手順 5 で、ECS インスタンスのポート 8000 を開きます。 この手順をスキップすると、デフォルト設定が使用されます。
- 接続をテストします。
- サーバーを追加します。
- MySQL データベースと Elasticsearch ホワイトリストを設定します。
ECS インスタンスの IP アドレスを MySQL データベースと Elasticsearch インスタンスのホワイトリストに追加して、ECS インスタンスが MySQL データベースと Elasticsearch インスタンスと通信できるようにします。
- 左側のナビゲーションペインで [Connections] を選択し、[Add Connection] をクリックします。
- [MySQL] を選択します。 [Add MySQL Connection] ページで、必要な情報を入力します。
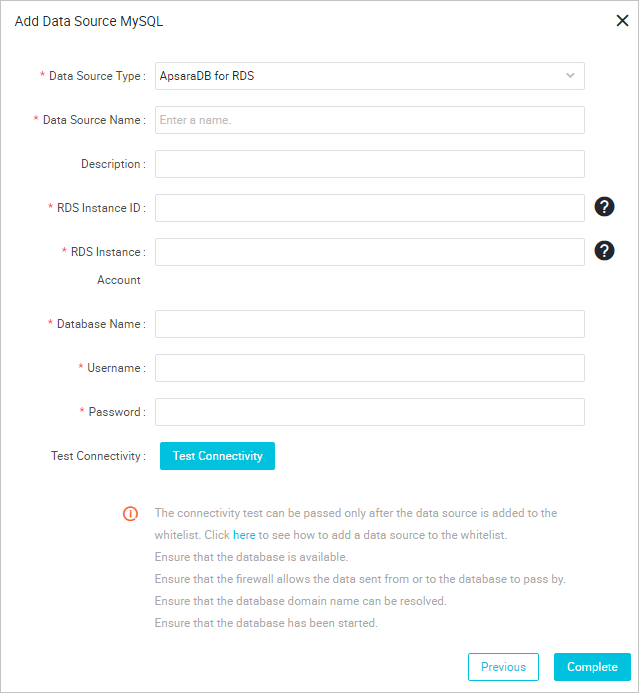
Connect To:この例では、ApsaraDB RDS for MySQL データベースを使用します。 [User-created Data Store with Public IP Addresses] か [User-created Data Store without Public IP Addresses] から選択できます。 パラメーターの詳細については、「MySQL データソースの設定」をご参照ください。
重要 ECS インスタンスがデータベースへの接続に失敗した場合、データベースのホワイトリストを確認してください。




同期タスクの作成
- DataWorks コンソールにノード所有者としてログインします。
- [Workspaces] タブで、[Actions] 列の [Data Analytics] をクリックします。
- [Data Studio] ページで、 を選択します。
- [Create Workflow] ダイアログボックスで、[Workflow Name] と[Description] を指定し、[Create] をクリックします。
- 作成したワークフローを左側のワークフローリストで展開し、[Data Integration] を右クリックし、 を選択します。
- [Create Node] ダイアログボックスで、[Node Name] を指定し、[Commit] をクリックします。
- [node] タブの上部のツールバーで、[Switch to Code Editor] アイコン
 をクリックします。
をクリックします。
- 操作を確認して、コードエディターに切り替えます。
コードエディターの使用方法については、「スクリプトモードの設定」をご参照ください。
次のスクリプトは、2 つのテーブルから学生と試験の情報を取得する例です。{ "type": "job", "steps": [ { "stepType": "mysql", "parameter": { "column": [ "id"、 "name", "sex", "birth", "department", "address": { ], "connection": [ { "querysql":["SELECT student.id,name,sex,birth,department,address,c_name,grade FROM student JOIN score on student.id=score.stu_id;"], "datasource": "zl_****_rdsmysql", "table": [ "score" ] } ], "where": "", "splitPk": "", "encoding": "UTF-8" }, "name":"Reader", "category": "reader" }, { "stepType": "elasticsearch", "parameter": { "accessId": "elastic", "endpoint": "http://es-cn-0p*********2dpxtx.elasticsearch.aliyuncs.com:9200", "indexType": "score", "accessKey": "******", "cleanup": true, "discovery": false, "column": [ { "name":"student_id", "type":"id" }, { "name": "sex", "type": "text" }, { "name": "name", "type": "text" }, { "name": "birth", "type": "integer" }, { "name": "quyu", "type": "text" }, { "name": "address", "type": "text" }, { "name": "cname", "type": "text" }, { "name": "grades", "type": "integer" } ], "index": "mysqljoin", "batchSize": 1000, "splitter": "," }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "jvmOption": "-Xms1024m -Xmx1024m", "errorLimit": { "record": "" }, "speed": { "throttle": false, "concurrent": 1 } } }スクリプトには 3 つのセクションがあります。
Reader:このセクションは、MySQL リーダーの設定に使用されます。querysqlを使用して、特定の条件に基づいてデータを取得する SQL 文を定義します。querysqlが設定されている場合、MySQL Reader はtable、column、where、splitPk条件を無視します。 これは、querysqlの優先順位はtable、column、where、splitPkよりも高いためです。datasourceはquerysqlを使用して、ユーザー名とパスワード情報を解析します。Writer:このセクションは、ElasticSearch Writer の設定に使用されます。endpoint:Elasticsearch インスタンスのパブリックまたはプライベートネットワークエンドポイント。 Elasticsearch インスタンスに接続するには、Elasticsearch インスタンスの [セキュリティ] ページでパブリックまたはプライベートネットワークのホワイトリストを設定する必要があります。accessId/accessKey:Elasticsearch インスタンスのユーザー名とパスワード。 デフォルトのユーザー名は、elastic です。index:Elasticsearch インスタンスのインデックスの名前。 インデックスに保存されたデータにアクセスするには、インデックス名を指定する必要があります。ReaderとWriter内の列は、同じ順序で定義する必要があります。Readerは、指定された列からデータを読み取り、データを配列に保存します。 次に、Writerは配列からデータを取り出し、定義された列に順番にデータを書き込むためです。
setting:このセクションは、パケット損失や最大同時数などの設定に使用されます。
- スクリプトの設定後、右上隅の [Resource Group] をクリックし、作成したリソースグループを選択し、上部のツールバーで [Run] アイコンをクリックして MySQL データを Elasticsearch と同期します。

 をクリックします。
をクリックします。

同期結果の確認
- Elasticsearch インスタンスの Kibana コンソールにログインします。
- 左側のナビゲーションペインで、[Dev Tools] を選択します。
- [Console] タブで、次のコマンドを実行して同期データをクエリします。
POST /mysqljoin/_search? pretty { "query": { "match_all": {}} }文字列 mysqljoin は、同期データが保存されている index の名前です。
FAQ
-
Q:データベース接続エラーを解決するにはどうすればよいですか。
A:リソースグループ内の ECS インスタンスのパブリックまたはプライベート IP アドレスが、データベースのホワイトリストに追加されているかどうかを確認してください。 IP アドレスがホワイトリストに追加されていない場合は、追加してください。
-
Q:Elasticsearch インスタンスの接続エラーを解決するにはどうすればよいですか。
A:次の手順に従って原因を特定します。
- コードエディターの右上隅にある [Resource Group] をクリックし、前の手順で選択したリソースグループが選択されているかどうかを確認します。
- 選択されている場合、 次の手順に進みます。
- 選択されていない場合、 [Resource Group] をクリックし、作成したリソースグループを選択します。 次に、[Run] アイコンをクリックしてスクリプトを実行します。
- リソースグループ内の ECS インスタンスの IP アドレスが Elasticsearch インスタンスのホワイトリストに追加されているかどうかを確認します。
- 追加されている場合、 次の手順に進みます。
- 追加されていない場合、 ECS インスタンスの IP アドレスを Elasticsearch インスタンスのホワイトリストに追加してください。
重要 ECS インスタンスのプライベート IP アドレスが使用されている場合、Elasticsearch インスタンスの [セキュリティ] ページに移動し、IP アドレスを Elasticsearch システムのホワイトリストに追加します。 ECS インスタンスのパブリックIPアドレスが使用されている場合、Elasticsearch インスタンスの [セキュリティ] ページに移動し、IP アドレスをパブリックネットワークホワイトリストに追加します。
- スクリプトの設定が正しいかどうかを確認します。 確認する必要があるフィールドには、
endpoint(Elasticsearch インスタンスのパブリックまたはプライベートネットワークエンドポイント)、accessId(Elasticsearch インスタンスのユーザー名。 デフォルトのユーザー名は elastic)、accessKey(Elasticsearch インスタンスのパスワード) があります。
- コードエディターの右上隅にある [Resource Group] をクリックし、前の手順で選択したリソースグループが選択されているかどうかを確認します。