コンテナ、サーバーレスプログラミングメソッドの出現により、ソフトウェアの配信とデプロイの効率が大幅に向上しました。 アーキテクチャの進化により、以下の点が変わりました。
- アプリケーションアーキテクチャは、単一のシステムからマイクロサービスに変わりつつあり、 ビジネスロジックはマイクロサービス間での呼び出しとリクエストに変化しています。
- リソースに関しては、従来の物理サーバーは、次第に少なくなってきており、目に見えない仮想リソースに変化しています。

前述の 2 つの変化は、標準化された柔軟なアーキテクチャの背後で、運用管理 (O&M) と診断の要件がますます複雑化していることを示しています。 これらの変化に対応するために、集中ログシステム、集中測定システム 、分散トレースシステムを含む一連の DevOps 向けの診断および分析システムが登場しました。
Alibaba Cloud は Jaeger に加えて、OpenTracing リンクトレースサービス XTrace も提供します。
ロギング、メトリック、トレーシング
ロギング、メトリック、トレーシングの特徴は次のとおりです。
- ロギングは、離散イベントを記録します 。
アプリケーションのデバッグ情報やエラー情報などのデータを記録します。 このデータが診断の基礎となります。
- メトリックは、集約可能なデータを記録します。
たとえば、キューの現在の深さをメトリックとして定義し、要素がキューに追加またはキューから削除される際に更新します。 HTTP リクエスト数は、カウンターとして定義することが可能で、新しいリクエストを受信するたびに累積されます。
- トレーシングは、リクエスト範囲内で情報を記録します 。
リモートメソッド呼び出しのプロセスや消費時間などのデータを記録します。 このデータは、システムパフォーマンスの問題を調査するために使用するツールです。 ロギング、メトリック、およびトレーシングは、下図のように重なり合う部分があります。

以上から、既存のシステムを分類することができます。 たとえば、Zipkin はトレーシングに特化しています。 Prometheus はメトリックに特化し始めており、今後より多くのトレーシング機能が実装されていく可能性は高いですが、ロギングにはあまり関心がないようです。 ELK や Alibaba Cloud Log Service などのシステムは、ロギングに重点を置き、他の分野の機能と継続的に統合し始め、3 つすべてのシステムの共通部分に向かっています。
詳細については、「トリック、トレーシング、ロギング」をご参照ください。 次はトレーシングシステムの紹介です。
トレーシングの技術的背景
トレーシングテクノロジーは 1990年代から存在していましたが、 この分野を主流にしたのは Googleの記事「Dapper, a Large-Scale Distributed Systems Tracing Infrastructure」でした。 また、「Uncertainty in Aggregate Estimates from Sampled Distributed Traces」では、サンプリングのより詳細な分析が説明されていました。 これらの記事が発表されたことで、数多くの優れたトレーシングソフトウェアプログラムの開発グループが現れました。
よく利用されている製品
- Dapper (Google):あらゆる Tracer の基盤
- StackDriver Trace (Google)
- Zipkin (Twitter)
- Appdash (golang)
- EagleEye (Taobao)
- Ditecting (Pangu、Alibaba Cloud のクラウドプロダクトで使用されるトレーシングシステム)
- Cloud Map (Ant Tracing システム)
- sTrace (Shenma)
- X-ray (AWS)
分散トレーシングシステムは急速に発展しており、種類も数多くあります。 ただし、いずれも共通してコードトラッキング、データストレージ、およびクエリの表示の 3 ステップがあります。

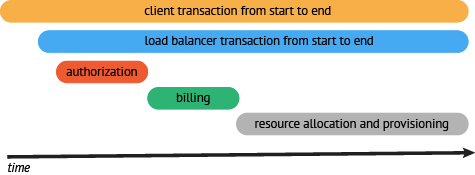
データが収集され保存されると、分散型トレーシングシステムはタイムラインを含むタイミング図にトレースを提供します。 ただし、データ収集プロセスでは、システムがユーザーコードに割り込む必要があります。さらに、異なるシステム間での API 互換性がないため、 トレーシングシステムを切り替えるには、大きな変更を加える必要があります。
OpenTracing

- OpenTracing は Cloud Native Computing Foundation (CNCF) に入られており、グローバル分散トレースシステムの統一コンセプトとデータ標準を提供しています。
- OpenTracing は、プラットフォームやベンダーに関係なく API を提供します。 これにより、開発者はトレースシステムの実装を簡単に追加または変更できます。
OpenTracing 内の Trace (呼び出しチェーン) はこの呼び出しチェーン内の Span によって暗黙的に定義されます。 トレース (呼び出しトレース) は、有向非巡回グラフ (DAG) と見なすことができます。 DAG は複数の Span で構成されています。 Span 間の関係は参照と呼ばれます。
たとえば、次の Trace は 8 つの Span で構成されています。
単一の Trace の Span 間における因果関係
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C は Span A の子ノード、 ChildOf)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G は Span F の後に呼び出されます、FollowsFrom)次の例に示すように、タイムラインに基づくタイミング図が、Trace (呼び出しトレース) をより適切に表示できることがあります。
単一の Trace の Span 間における時間的関係。
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]各 Span には、次のステータスが含まれます。
- 操作名
- 開始タイムスタンプ
- 終了タイムスタンプ
- Span タグ。 これは、キーと値のペアで構成された Span タグのコレクションです。 キーと値のペアでは、キーは文字列でなければなりません、値の型は文字列、ブール値、または数値にすることができます。
- Span log。 Span ログのコレクション。 各ログ操作には、キー、値のペア、及びタイムスタンプが 1 つずつ含まれています
キーと値のペアでは、キーは文字列である必要があり、値は任意のタイプにすることができます。 ただし、トレーサーをサポートする OpenTracing はすべての値タイプをサポートするわけではありません。
- SpanContext (Span の内容です)
- References 関連しているゼロまたは複数の Span (Span の間では、SpanContext を通じて関係を確立します)。
各 SpanContext には、次のステータスが含まれます。
- いかなる OpenTracing 実装も、一意の Span に基づいてプロセスの境界を越えて現状の呼び出しチェーンのステータス (Trace ID と Span ID など) を送信する必要があります。
- Baggage items (Trace に付属するデータのこと)。 Trace に保存されているキーと値のペアのコレクションであり、プロセスの境界を越えて送信する必要があります。
OpenTracing データモデルの詳細については、「OpenTracing のセマンティック標準」をご参照ください。
関数の実装
ドキュメント「サポートされている Tracer」にはすべての OpenTracing の実装が一覧表示されています。 Jaeger と Zipkin の実装が最も一般的です。
Jaeger
Jaeger は、Uber によりリリースされたオープンソースの分散トレースシステムで、 OpenTracing API 操作と互換性があります。
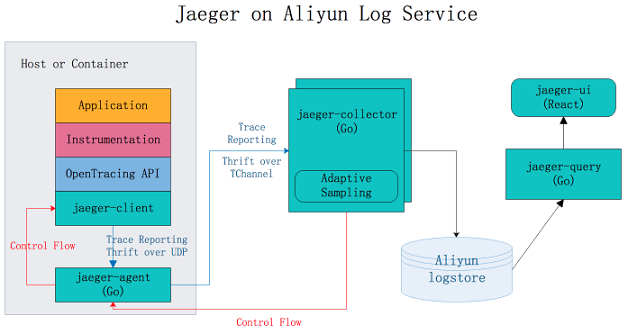
アーキテクチャ

上図に示すように、Jaeger は次のコンポーネントで構成されています。
- Jaeger client:異なるプログラミング言語の OpenTracing 標準に準拠した SDK を実装します。 アプリケーションは API を使用してデータを書き込みます。 Client Library は、アプリケーションで指定されたサンプリングポリシーに従って Trace 情報を jaeger-agent に送信します。
- Agent:ユーザーデータグラムプロトコル (UDP) ポートが受信したスパンデータを監視し、同時に複数のデータアイテムを Collector に送信するネットワークデーモンです。 Agent は基本コンポーネントとして設計されており、すべてのホストにデプロイされています。 Client Library と Collector を分離し、コレクタールーティングとディスカバリーの詳細から Client Library を保護します。
- Collector:jaeger-agent によって送信されたデータを受信してから、そのデータをバックエンドストレージに書き込みます。 Collector はステートレスコンポーネントとして設計されています。 そのため、任意の数の jaeger-collectors を同時に実行できます。
- Data store:バックエンドストレージは、Cassandra と Elasticsearch へのデータ書き込みをサポートするプラグイン可能なコンポーネントとして設計されています。
- Query:クエリリクエストを受信し、バックエンドストレージシステムから Trace 情報を取得して UI に表示します。 クエリにはステートがありません。 複数のインスタンスを起動し、NGINX ロードバランサーの背後にインスタンスを展開できます。
Jaeger on Alibaba Cloud Log Service
利点
- ネイティブ Jaeger は Cassandra と Elasticsearch へのデータの永久保存のみをサポートします。 ユーザーはバックエンドストレージシステムの安定性を保守し、ストレージ容量を調整する必要があります。 Jaeger on Alibaba Cloud Log Service は、 Log Service を使用して大量のデータを処理します。 このようにして、Jaeger 分散トレーシングテクノロジーの利点をすぐに感じることができ、バックエンドストレージシステムへの労力を減らすことができます。
- Jaeger UI は、トレースを照会および表示はできますが、問題分析とトラブルシューティングに改善の余地があります。 Alibaba Cloud Log Service で Jaeger を使用すると、Log Service の強力なクエリおよび分析機能を使用して、システムの問題を効率的に分析できます。
- バックエンドストレージに Elasticsearch を使用する Jaeger と比較して、Log Service は従量課金に対応しているため、そのコストは Elasticsearch のコストのわずか 13 %となります。 詳細については、「自己構築 ELK vs Log Service (SLS)」をご参照ください。
手順
詳細については、 GitHub をご参照ください。
例
HotROD は、複数のマイクロサービスで構成されたアプリケーションで、OpenTracing API を使用して Trace 情報を記録します。
Alibaba Cloud Log Service で Jaeger を使用して HotROD の問題を診断するには、チュートリアルビデオに示されている次の手順に従います。
- Log Service の設定
- docker-compose コマンドを実行して Jaeger を起動
- HotROD の実行
- Jaeger UI を使用して、指定された Trace 情報の取得
- Jaeger UI を使用して、詳細な Trace 情報の表示
- Jaeger UI を使用して、アプリケーションのパフォーマンスボトルネックの特定
- Jaeger UI を使用して、アプリケーションのパフォーマンスボトルネックの特定
- アプリケーションによる OpenTracing API の呼び出し
チュートリアル
http://cloud.video.taobao.com//play/u/2143829456/p/1/e/6/t/1/50081772711.mp4
この例では、次のクエリ文を使用します。
- 1 分ごとにフロントエンドサービスの HTTP GET / dispatch 操作の平均待ち時間およびリクエスト数をカウント
process.serviceName: "frontend" and operationName: "HTTP GET /dispatch" | select from_unixtime( __time__ - __time__ % 60) as time, truncate(avg(duration)/1000/1000) as avg_duration_ms, count(1) as count group by __time__ - __time__ % 60 order by time desc limit 60 - 2 つの Trace 操作の所要時間を比較
traceID: "trace1" or traceID: "trace2" | select operationName, (max(duration)-min(duration))/1000/1000 as duration_diff_ms group by operationName order by duration_diff_ms desc - 待ち時間が 1.5 秒を超える Trace の IP アドレスをカウント
process.serviceName: "frontend" and operationName: "HTTP GET /dispatch" and duration > 1500000000 | select "process.tags.ip" as IP, truncate(avg(duration)/1000/1000) as avg_duration_ms, count(1) as count group by "process.tags.ip"