By default, each shard of an ApsaraDB for MongoDB sharded cluster instance contains three nodes. When a node fails, the high availability system of ApsaraDB for MongoDB automatically triggers a primary/secondary failover to ensure the overall availability. You can also manually trigger a primary/secondary failover for an ApsaraDB for MongoDB instance in scenarios such as routine disaster recovery drills.
Usage notes
ApsaraDB for MongoDB provides connection strings for you to connect to the primary node and a secondary node. The other secondary node is hidden as a backup to ensure high availability. After you log on to the ApsaraDB for MongoDB console or call the SwitchDBInstanceHA operation to trigger a primary/secondary failover for a shard of a sharded cluster instance, ApsaraDB for MongoDB switches the roles of the primary and secondary nodes.
- You can trigger a primary/secondary failover for replica set and sharded cluster instances, but not for standalone instances due to their single-node architecture.
- You can trigger a primary/secondary failover only for shards in the running state.
- Each time you trigger a primary/secondary failover for an instance, the instance may encounter a transient connection error of about 30 seconds. We recommend that you perform this operation during off-peak hours and make sure that your applications can automatically re-establish a connection.
Procedure
- Log on to the ApsaraDB for MongoDB console.
- In the upper-left corner of the page, select the resource group and region to which the instance belongs.
- In the left-side navigation pane, click Sharded cluster instance.
- On the page that appears, find the instance that you want to manage and click its ID.
- In the Shard List section, find the shard node and choose
 > Primary/Secondary Switchover.
> Primary/Secondary Switchover.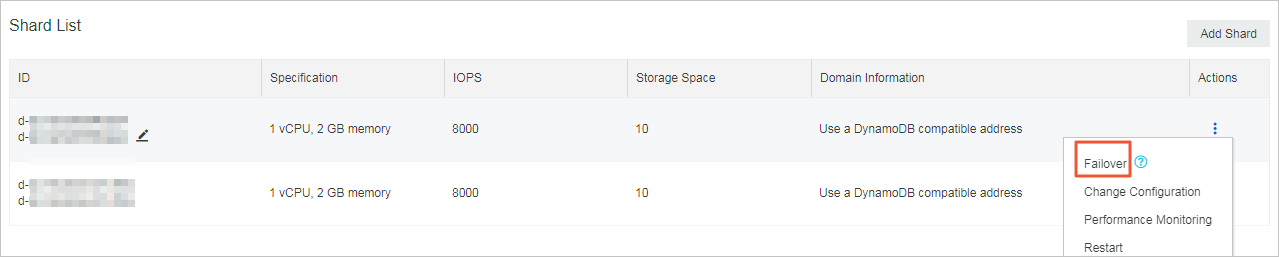
You can trigger a primary/secondary failover separately for each shard node. The failover operation takes effect only for the current shard node and does not affect other shard nodes of the same sharded cluster instance.
- In the Primary/Secondary Switchover dialog box, select Effective At and click Submit.Note Primary/Secondary Switchover supports two types of Effective At:
- Effective Immediately: The system immediately performs a primary/secondary failover.
- Maintenance Window:The system performs a primary/secondary failover within the specified maintenance window. For more information about how to set the maintenance time, see Specify a maintenance window.
- The instance status changes to HA Switching.The failover is successful when the instance status changes back to Running.Note The failover operation is complete in about 1 minute. You can repeat the preceding procedure to trigger a primary/secondary failover for other shards of the same sharded cluster instance.