MaxCompute Studio は、CSV または TSV 形式のローカルデータファイルを MaxCompute テーブルにインポートし、MaxCompute テーブルデータをローカルファイルにエクスポートします。 MaxCompute Studio は、 MaxCompute プラットフォームが提供するバッチデータ Tunnel を使用して、データのインポートとエクスポートを完了します。
使用法の説明
- データのインポートとエクスポートには、MaxCompute Tunnel サービスを使用する必要があります。 したがって、Studio で追加された MaxCompute プロジェクトは、 Tunnel サービスで設定する必要があります。
- テーブルのインポートとエクスポートには関連する権限を付与する必要があります。
データのインポート
-
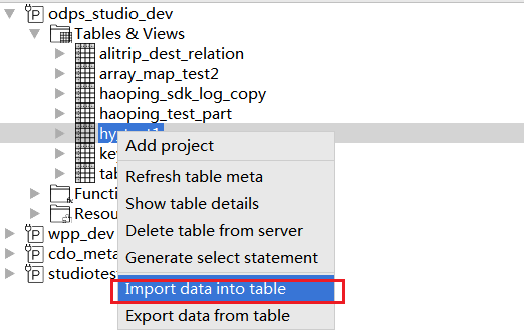
[Project Explorer] ウィンドウを開き、 [Table details] の Data Preview で、テーブル名またはフィールド属性を右クリックし、[Import Data Into Table] をクリックします。
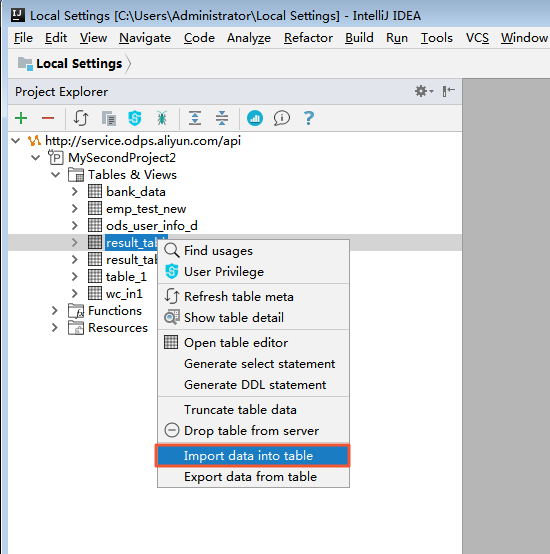
-
表示される [Import Data] ダイアログボックスで、 インポートしたデータファイルのパス、列の区切り記号、サイズ制限、および許容誤差の行数を選択し、[OK] をクリックします 。
-
Import Data Success と表示されたら、データのインポートは成功し、インポートされたデータがテーブルに表示されます。


データのエクスポート
- テーブルデータのエクスポートには 2 つの方法があります。
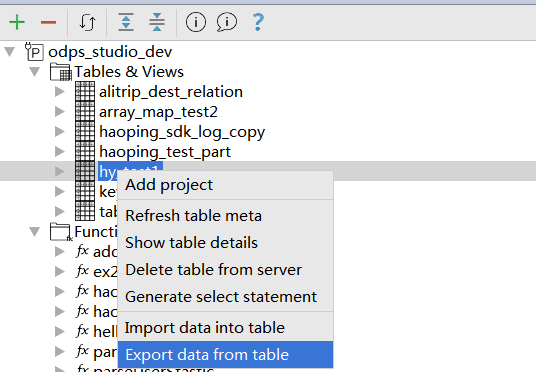
-
テーブル名を右クリックして、[Export Data From Table] をクリックします。
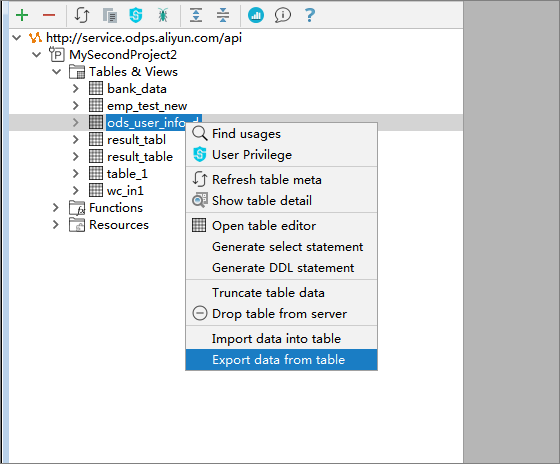
-
[Table details] のData Preview のフィールド属性を右クリックし、 [Export Data From Table] をクリックします。
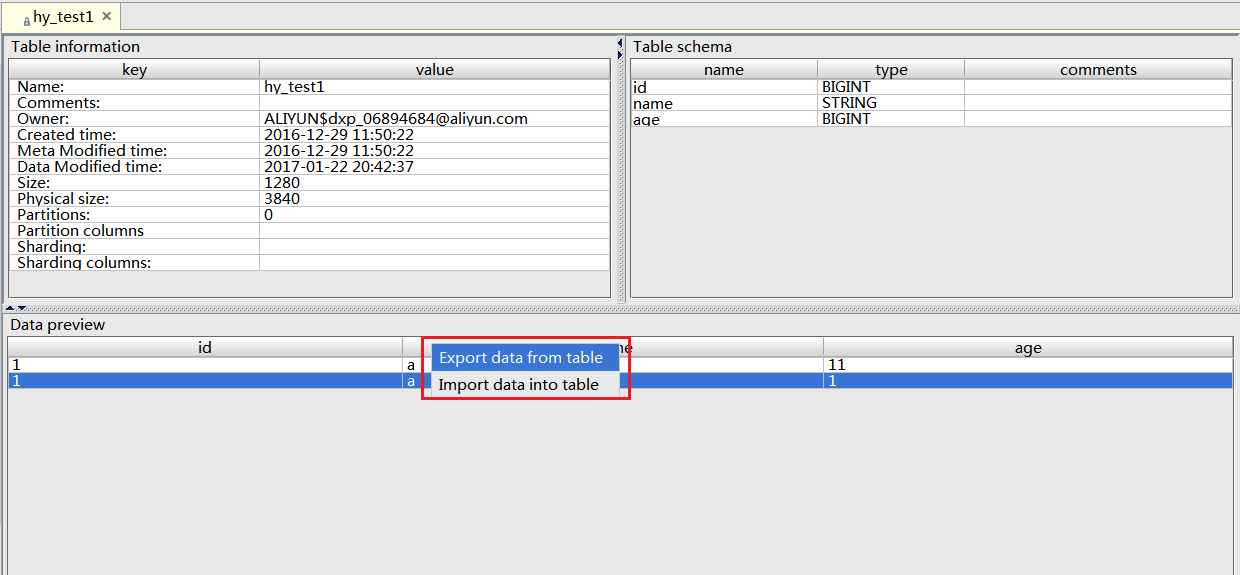
-
-
[Export Data] ダイアログボックスで、インポートしたデータファイルのパス、列の区切り記号、サイズ制限、および許容誤差の行数を選択し、[OK] をクリックします。
-
Export Data Success と表示されたら、データのエクスポートは成功し、エクスポートされたデータがターゲットファイルに表示されます。



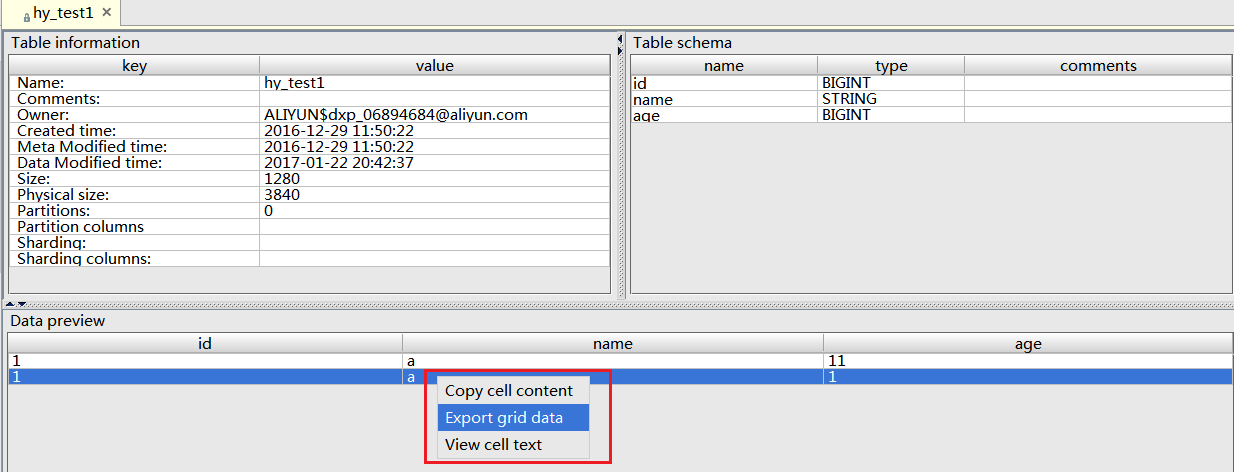
テーブルの [Data Preview] を右クリックし、[Export Grid Data] をクリックして、データをエクスポートすることも可能です。
新しい型のインポートとエクスポート
所定の形式でテキストを生成し、CSV または TSV 形式で保存するだけで、Studio を介してテーブルにインポートが可能です。
各データ型の変換ルールについては、後で詳しく説明します。
基本型- Tinyint、smallint、Int、bigint は整数文字列として直接格納され、型の境界を超える数値型はエラーとして報告されます。
- Float、double は、2.342 1x + 7 などの小数文字列または浮動小数点形式を格納します。
- Varchar は文字列として直接格納され、上限を超えると自動的に切り捨てられ、エラーは報告されません。
- 文字列は文字列として直接格納されます。
- 10 進数文字列は、整形または浮動小数点をサポートします。
- バイナリは、バイナリデータを base64 文字列にエンコードする必要があります。
- Datetime の日時は、インポートダイアログで指定されたフォーマットが一致している必要があります。フォーマットが一致しないと、誤りとして報告されます。
- Timestamp タイムスタンプは、yyyy-[m] M-[d] d hh \: mm \: ss [. f...] に従う必要があります。 フォーマットは文字列として格納されます。
- ブール値は true または false 文字列です。
- 配列は JSON 配列として格納する必要があります。 配列要素は、このドキュメントで定められたルールに従って文字列に変換されます。配列要素は任意の型をサポートします。
- Map は JSON オブジェクトとして格納する必要があり、マップキー、値は、このドキュメントで定められたルールに従って文字列に変換され、値は任意の型の入れ子をサポートします。
- Struct は JSON オブジェクトとして格納する必要があります。struct のフィールド名は文字列です。キーは JSON オブジェクトに変換され、struct フィールド値は JSON に変換されます。 オブジェクトの値、フィールドの値は、このドキュメントのルール変換で定義されています。
Array 型
次のようなテーブル構造とします。
| 列名 | 列データ型 |
|---|---|
| c_1 | ARRAY<TINYINT> |
| c_2 | ARRAY<INT> |
| c_3 | ARRAY<FLOAT> |
| c_4 | ARRAY<DATETIME> |
| c_6 | ARRAY<TIMESTAMP> |
| c_7 | ARRAY<STRING> |
以下に示す CSV 形式のデータをインポートします。
c_1,c_2,c_3,c_4,c_6,c_7
"[" "1" "," "2 "", "3" "]", "[" 1 "", "2", "3", "4"], "[" "1.2" "," 2.0 ""] ", "[" "3-00:00:00", "3-5-00:00:00 "", "00:00:00", "[" At 00:00:00. 123456789 "", "At 00:00:00. 123456789 "", "At 00:00:00. 123456789 ""] "," ["AAA" "," Steamboat "", "4C" "]"
"[""1"",""2"",""3""]","[""1"",""2"",""3"",""4""]","[""1.2"",""2.0""]","[""2017-11-11 00:00:00"",""2017-11-11 00:00:00"",""2017-11-11 00:00:00""]","[""2017-11-11 00:00:00.123456789"",""2017-11-11 00:00:00.123456789"",""2017-11-11 00:00:00.123456789""]","[""aaa"",""bbb"",""ccc""]"
"[""1"",""2"",""3""]","[""1"",""2"",""3"",""4""]","[""1.2"",""2.0""]","[""2017-11-11 00:00:00"",""2017-11-11 00:00:00"",""2017-11-11 00:00:00""]","[""2017-11-11 00:00:00.123456789"",""2017-11-11 00:00:00.123456789"",""2017-11-11 00:00:00.123456789""]","[""aaa"",""bbb"",""ccc""]"次のようなテーブル構造とします。
| 列名 | 列データ型 |
|---|---|
| c_1 | MAP<TINYINT,STRING> |
| c_2 | MAP<STRING,INT> |
| c_3 | MAP<FLOAT,STRING> |
| c_4 | MAP<STRING,DATETIME> |
| c_5 | MAP<STRING,STRING> |
| c_6 | MAP<TIMESTAMP,STRING> |
以下に示す CSV 形式のデータをインポートします。
c_1,c_2,c_3,c_4,c_5,c_6
"{1:" "2345" "}", "{" 123 "": "2", "3": "4 ""}", "{2.0:" "223445" ", 1.2:" 1111 ""}", "{" "AAA" ":" "hub11 00:00:00 "", "4C" ":" China "11 00:00:00" "," Steamboat "": "00:00:00"} "," ckey "": "cvalue"} "," {"" hub11 01:00:00. 123456789 "": "dddd" "," "hub11 00:00:00. 123456789 "": "AAA" "," 027 11 00:01:00. 123456789 "": "DDD ""}"
"{1:" "2345" "}", "{" 123 "": "2", "3": "4 ""}", "{2.0:" "223445" ", 1.2:" 1111 ""}", "{" "AAA" ":" "hub11 00:00:00 "", "4C" ":" China "11 00:00:00" "," Steamboat "": "00:00:00"} "," ckey "": "cvalue"} "," {"" hub11 01:00:00. 123456789 "": "dddd" "," "hub11 00:00:00. 123456789 "": "AAA" "," 027 11 00:01:00. 123456789 "": "DDD ""}"
"{1:""2345""}","{""123"":""2"",""3"":""4""}","{2.0:""223445"",1.2:""1111""}","{""aaa"":""2017-11-11 00:00:00"",""ccc"":""2017-11-11 00:00:00"",""bbb"":""2017-11-11 00:00:00""}","{""ckey"":""cvalue""}","{""2017-11-11 01:00:00.123456789"":""dddd"",""2017-11-11 00:00:00.123456789"":""aaa"",""2017-11-11 00:01:00.123456789"":""ddd""}"次のようなテーブル構造とします。
| 列名 | 列データ型 |
|---|---|
| C_struct | <RUCT<x:INT,y:VARCHAR(256),z:STRUCT<a:TINYINT,b:STRING>> |
以下に示す CSV 形式のデータをインポートします。
c_struct
"{""x"":""1000"",""y"":""varchar_test"",""z"":{""a"":""123"",""b"":""stringdemo""}}"
"{""x"":""1000"",""y"":""varchar_test"",""z"":{""a"":""123"",""b"":""stringdemo""}}"