Log Service は、ログを簡単に検索できるように、クエリ条件を表現するために使用される一連のクエリ構文を提供します。
クエリメソッド
インデックス機能を有効にし、インデックスを構成 した後、ログクエリページでクエリと分析ステートメントを入力してログを照会できます。
- 全文テキストクエリ
全文クエリでは、ログ全体が特別なキー/値のペアと見なされ、ログの内容が値と見なされます。 全文クエリのキーワードを指定できます。 具体的には、クエリ条件に含めるか、クエリ条件から除外する必要があるキーワードを指定できます。 指定したクエリ条件を満たすログがクエリ結果として返されます。
Log Service は、フレーズクエリとファジークエリもサポートしています。- 一般的な全文クエリ:キーワードとルールを指定する必要があります。 キーワードを含み、ルールに適合するログは、クエリ結果として返されます。
たとえば、
a and bはクエリ結果がキーワードのaとbを両方含まなければならないことを示します。 - フレーズクエリ:ターゲットフレーズにスペースが含まれる場合、フレーズを二重引用符 (" ") で囲むことができます。 この場合、このフレーズがログクエリの完全なキーワードと見なされます。
たとえば、
"http error"はクエリ結果にhttp errorが含まれなければならないことを示します。 - ファジークエリ:最大 64 文字まで単語の一部を指定し、単語の中央または末尾にファジークエリキーワード (
*または?) を追加できます。 これにより、すべてのログの中でクエリ条件に一致する単語を最大 100 個まで照会し、単語 100 個に対応するログを結果として返します。たとえば、
addr?は、Log Service がaddrで始まる単語を 100 個まで照会し、対応するログを返す必要のあることを示します。
- 一般的な全文クエリ:キーワードとルールを指定する必要があります。 キーワードを含み、ルールに適合するログは、クエリ結果として返されます。
- キー/値クエリ
フィールドのインデックスを設定した後、特定のフィールドの名前またはコンテンツを照会できます。 double または longtype のフィールドの場合、クエリの値の範囲を指定することもできます。 たとえば、キー/値クエリステートメント
Latency > 5000 および Method:Get* and not Status:200は、クエリ結果が次の条件を満たす必要があることを示します。レイテンシの値が 5000 より大きいこと。-
[メソッド]フィールドはGetで始めなければなりません。 ステータスフィールドの値が 200 ではないこと。
フィールドインデックスに設定されたデータ型に応じて、さまざまな種類の基本的なクエリと結合クエリを実行できます。 キー/値クエリの例の詳細については、「インデックスデータタイプの概要」をご参照ください。
注意事項
- 全文クエリとキー/値クエリの両方が実行される場合、2 つのクエリメソッドに設定された区切り文字が異なる場合、キー/値クエリに設定された区切り文字が使用され、全文クエリのクエリ結果は無効になります。
- フィールドのデータ型を double または long に設定した後で、指定した値の範囲でフィールドをクエリできるようになります。 フィールドデータ型が指定されていない、または値の範囲をクエリするための構文が正しくない場合、Log Service はクエリ条件が全文クエリ用であると判断します。 これにより、予期しないクエリ結果が返される場合があります。
- フィールドの日付タイプがテキストから数値に変更された場合、変更前に収集されたデータは
=クエリのみサポートします。
演算子
| 演算子 | 説明 |
|---|---|
| and | バイナリ演算子です。 query1 and query2 形式で、 query1 と query2 のクエリ結果の共通部分を示します。 単語の間に構文キーワードがない場合、単語間の関係はデフォルトでは and です。 |
| or | バイナリ演算子です。 query1 or query2 の形式で、 query1 と query2 のクエリ結果の和集合を示します。
|
| not | バイナリ演算子です。 query1 not query2 の形式で、 query1 とは一致するが query2 とは一致しない結果を示します。つまり、query1–query2 と等しいです。 not query1 のみが存在する場合、すべてのログから query1 が含まれない結果を選択することを示します。
|
| ( , ) | 左右のかっこは、1 つ以上のサブクエリを 1 つのクエリにマージして、左右かっこ内のクエリ優先度を高めるために使用します。 |
| : | キーと値のペアを照会するために使用します。term1:term2 は、キーと値のペアを形成します。 スペースが含まれている場合は、キーまたは値全体を含めるために引用符を使用する必要があります。
|
| “ | キーワードを共通のクエリ文字に変換します。 左右の引用符で囲まれた語はすべて照会され、構文キーワードとしては使用されません。 または、引用符 ( " ) で囲まれたすべての用語は、キーと値のクエリで全体として見なされます。 |
| \ | エスケープ文字です。 引用符をエスケープするために使用します。 エスケープされた引用符はシンボル自体を示し、 "\"" のようにエスケープ文字として使用することはできません。
|
| | | パイプライン演算子は、以前の計算に基づいてより多くの計算を示します (query1 | timeslice 1h | count など)。 |
| timeslice | time-slice 演算子は、データが全体としてどのくらい計算されるかを示します。 Timeslice の 1h、1m、1s は、それぞれ 1 時間、1 分、1 秒を示します。 たとえば、query1 | timeslice1h | count はクエリのクエリ条件を表し、1 時間で割った合計時間に戻ります。 |
| count | count 演算子は、ログ行数を示します。 |
| * | ファジークエリーキーワード 0 または複数の文字を置き換えるために使用します。 たとえば、que* のクエリ結果では、que で始まるすべてのヒットワードが返されます。
注 およそ 100 のクエリの結果が返されます。
|
| ? | ファジークエリキーワード 1 つの文字を置き換えるために使用します。 例えば、 qu? ry のクエリ結果は quで始まり、ryで終わり、中間の文字で始まります。
|
__topic__ |
トピックデータクエリ。 クエリ内のゼロまたは複数のトピックのデータをクエリできます。 例えば、 __topic__:mytopicname。
|
__tag__ |
タグキーのタグ値を照会します。 たとえば、__tag__:tagkey:tagvalueのようになります。
|
| ソース | IPのデータをクエリします。 例えば、source:127.0.0.1。
|
| > | 特定の数値より大きいフィールドの値でログを照会します。 例えば、latency > 100.
|
| >= | 特定の数値以上のフィールドの値でログを照会します。 (例:latency >= 100)
|
| < | 特定の番号よりも小さいフィールドの値を持つログを照会します。 (例:latency < 100)
|
| <= | 特定の数値以下のフィールドの値でログを照会します。 (例:latency <= 100)
|
| = | 特定の数値に等しいフィールドの値でログを照会します。 (例:latency = 100)
|
| in | 特定の範囲内のフィールドでログを照会します。 中括弧([])は閉じた間隔を示すのに使用され、かっこ(())は開いた間隔を示すために使用されます。 中括弧 ([])
またはかっこ (()) で 2 つの数字を囲み、数字を複数のスペースで区切ります。 (例: [100 200] のレイテンシ または (100 200]] のレイテンシ)
|
- 演算子は大文字と小文字を区別しません。
- 演算子は、優先度の高い方から
:>">( )>and>not>orという順番になります。 - Log Service は以下の演算子を使用する権利を保有します。
sort、asc、desc、group by、avg、sum、min、max、limit。これらのキーワードを使用するには、キーワードを引用符で囲みます。
クエリの例
| クエリデマンド | 例 |
|---|---|
| a と b を同時に含むログ | a and b または a b |
| a または b を含むログ | a or b |
| a を含むが b を含まないログ | a not b |
| a を含まないすべてのログ | not a |
| a と b を含み、c を含まないログ | a and b not c |
| a または b を含み、c を含まなければならないログ | (a or b ) and c |
| a または b を含むが、c を含まないログ | (a or b ) not c |
| a および b を含み、c を含む可能性があるログ | a and b or c |
| FILE フィールドに apsara が含まれるログ | FILE:apsara |
| FILE フィールドに apsara と shennong が含まれるログ | FILE: "apsara shennong", FILE:apsara FILE:shennong またはFILE:apsaraおよびFILE:shennong |
| and を含むログ | and |
| apsara または shennong を含む FILE フィールドを持つログ | FILE:apsara or FILE:shennong |
| apsara を含むファイル情報フィールドを持つログ | "file info":apsara |
| 引用符 ("") を含むログ | \ " |
| shen で始まるすべてのログ | shen* |
| FILE フィールドの shen で始まるすべてのログ | FILE:shen* |
| shen * の FILE フィールドを持つすべてのログ | FILE: "shen*" |
| Logs starting with shen で始まり、ong で終わり、真ん中に文字のあるログ | shen?ong |
| shen と aps で始まるログ | shen* and aps* |
| 20 分ごとに shen で始まるログ | shen*| timeslice 20m | count |
| topic1 および topic2 のすべてのデータ | __topic__:topic1 or __topic__ : topic2 |
| tagkey1 の tagvalue2 のすべてのデータ | __tag__ : tagkey1 : tagvalue2 |
| レイテンシが 100 以上 200 未満のすべてのデータ | レイテンシ >=100 およびレイテンシ < 200 または[100 200) のレイテンシ |
| 待ち時間が 100 を超えるすべてのリクエスト | latency > 100 |
| スパイダーを含まず、http_referer に opx を含まないログ | not spider not bot not http_referer:opx |
| 空の cdnIP フィールドを持つログ | not cdnIP:"" |
| cdnIP フィールドなしのログ | not cdnIP:* |
| cdnIP フィールドを持つログ | cdnIP:* |
指定されたトピックまたはクロストピックのクエリ
トピックごとに、各 LogStore を 1 つ以上の部分空間に分割できます。 therfhfrg クエリ中にトピックを指定すると、クエリの範囲が制限され、速度が向上する可能性があります。 したがって、LogStore の 2 次分類要件がある場合は、トピックを使用して LogStore を分割することを推奨します。
1 つまたは複数のトピックが指定されている場合、クエリは条件を満たすトピックでのみ実行されます。 ただし、トピックが指定されていない場合は、デフォルトですべてのトピックのデータが照会されます。
たとえば、異なるドメイン名でログを分類するには、topic を使用します。
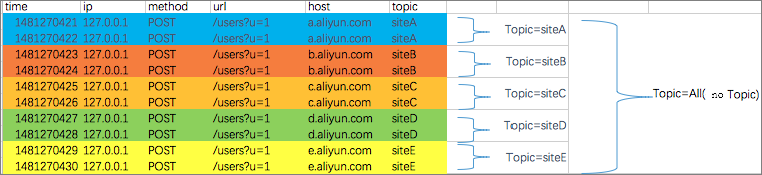
- すべてのトピックのデータを照会できます。 クエリの構文とパラメータにトピックが指定されていない場合は、すべてのトピックのデータがクエリされます
- トピックごとにクエリをサポートします。 クエリ構文は
__topic__:topicNameです。 古いモード (URL パラメーターでトピックを指定) は引き続きサポートされます。 - 複数のトピックを照会することができます。 たとえば、
__topic__:topic1 or __topic__:topic2は、Topic1 と Topic2 からのデータの結合クエリを示します。
ファジー検索
ログサービスはファジー検索をサポートしています。 64 文字以内の単語を指定し、ファジー検索キーワード (例:* や ?) を 単語の間または最後に追加します。 100 件の適格な単語が検索され、やがて 100 語を含むすべてのログが返されます。
-
*または?で始めることができないクエリログには、接頭辞を指定する必要があります。 - 特定の単語を度をあげることで、結果の精度が向上します。
- ファジー検索は、64 文字を超える単語の検索には使用できません。 64 文字以下の単語を指定することを推奨します。