このサンプルプロジェクトは、MapReduce、Pig、Hive、および Spark のサンプルコードを含む、完全、コンパイル可能、実行可能なプロジェクトです。
サンプルプロジェクト
- MapReduce
WordCount : 単語数をカウントします。
- Hive
sample.hive : テーブルを簡単に検索します。
- Pig
sample.pig : Pig が処理する OSS データインスタンス
- Spark
- SparkPi : Pi を計算します。
- SparkWordCount : 単語数をカウントします。
- LinearRegression : 線形回帰
- OSSSample : OSS のサンプル
- ODPSSample: ODPS サンプル
- MNSSample: MNS サンプル
- LoghubSample: Loghub サンプル
依存関係
- テストデータ (データディレクトリの下)
- The_Sorrows_of_Young_Werther.txt: WordCount (MapReduce/Spark) の入力データとして使用します。
- patterns.txt: WordCount (MapReduce) ジョブの文字をフィルタリングします。
- u.data: sample.hive スクリプトのテストテーブルのデータ
- abalone: 線形回帰アルゴリズムのテストデータ
- JAR 依存関係 (lib ディレクトリの下)
tutorial.jar: sample.pig ジョブに必要な JAR 依存関係
準備
-
(オプション) Log Service を有効にします。 『Log Service ユーザーガイド』をご参照ください。
-
(オプション) MaxCompute のプロジェクトとテーブルを作成します。 「MaxCompute プロジェクトの作成 (Create a MaxCompute project)」 および 『MaxCompute クイックスタート』をご参照ください。
-
(オプション) ONS を使用します。 「メッセージキューのクイックスタート (Quick Start for Message Queue)」ご参照ください。
-
(オプション) MNS を使用します。 Message Service コンソールの使用に関するページをご参照ください。
概念
-
OSSURI: oss://accessKeyId:accessKeySecret@bucket.endpoint/a/b/c.txt. 入力データソースと出力データソースを指定します。 OSSURI は、hdfs:// などの URL と類似しています。
-
AccessKey ID と AccessKey Secret の組み合わせは、Alibaba Cloud API にアクセスするうえで鍵となります。 取得するにはこちらをクリックします。
クラスターでジョブを実行
-
Spark
-
SparkWordCount:
spark-submit --class SparkWordCount examples-1.0-SNAPSHOT-shaded.jar&lt; inputPath&gt; <outputPath> <numPartition>パラメーターの記述は以下のとおりです。
-
inputPath : データ入力パス
-
outputPath : データ出力パス
-
numPartition : 入力データの RDD パーティションの数
-
-
SparkPi:
spark-submit --class SparkPi examples-1.0-SNAPSHOT-shaded.jar -
OSSSample:
spark-submit --class OSSSample examples-1.0-SNAPSHOT-shaded.jar <inputPath> <numPartition>パラメーターの記述は以下のとおりです。
-
inputPath : データ入力パス
-
numPartition : データ RDD パーティション数を入力します。
-
-
ONSSample:
spark-submit --class ONSSample examples-1.0-SNAPSHOT-shaded.jar <accessKeyId> <accessKeySecret> <consumerId> <topic> <subExpression> <parallelism>パラメーターの記述は以下のとおりです。
-
accessKeyId: Alibaba Cloud AccessKey ID.
-
accessKeySecret: Alibaba Cloud AccessKey Secret
-
consumerId: See Consumer ID description.
-
topic : 各メッセージキューにはトピックがあります。
-
subExpression: See Message filtering.
-
parallelism : キュー内のメッセージを消費するレシーバー数を指定します。
-
-
ODPSSample:
spark-submit --class ODPSSample examples-1.0-SNAPSHOT-shaded.jar <accessKeyId> <accessKeySecret> <envType> <project> <table> <numPartitions>パラメーターの記述は以下のとおりです。
-
accessKeyId : Alibaba Cloud AccessKey ID
-
accessKeySecret: Alibaba Cloud AccessKey Secret.
-
envType : 0 はパブリックネットワーク、1 はプライベートネットワークを示します。 ローカルデバッグには 0、E-MapReduce での実行には 1 を選択します。
-
project: 「ODPS クイックスタート (ODPS Quick Start)」をご参照ください。
-
numPartition: 入力データの RDD パーティションの数
-
-
MNSSample:
spark-submit --class MNSSample examples-1.0-SNAPSHOT-shaded.jar <queueName> <accessKeyId> <accessKeySecret> <endpoint>パラメーターの記述は以下のとおりです。
-
queueName: キュー名 コア概念をご参照ください。
-
accessKeyId: Alibaba Cloud AccessKey ID
-
accessKeySecret: Alibaba Cloud AccessKey Secret
-
endpoint: キューデータにアクセスするためのアドレス
-
-
LoghubSample:
spark-submit --class LoghubSample examples-1.0-SNAPSHOT-shaded.jar <sls project> <sls logstore> <loghub group name> <sls endpoint> <access key id> <access key secret> <batch interval seconds>パラメーターの記述は以下のとおりです。
-
sls project: Log Service プロジェクト名
-
sls logstore: Logstore 名
-
loghub group name: ジョブで Logstore データを消費するグループの名前 必要に応じて名前を指定できます。 sls project と sls store の値が同じ場合、同じグループ名のジョブは sls store 内のデータを共同で消費します。 グループ名が異なるジョブは、sls store 内のデータを個別に消費します。
-
sls endpoint: 「サービスエンドポイント (Service endpoint)」をご参照ください。
-
accessKeyId: Alibaba Cloud AccessKey ID
-
accessKeySecret: Alibaba Cloud AccessKey Secret
-
batch interval seconds: Spark Streaming ジョブ間の間隔 (単位 : 秒)
-
-
LinearRegression:
spark-submit --class LinearRegression examples-1.0-SNAPSHOT-shaded.jar <inputPath> <numPartitions>パラメーターの記述は以下のとおりです。
-
inputPath: データ入力パス
-
numPartition: 入力データの RDD パーティションの数
-
-
-
MapReduce
-
WordCount:
hadoop jar examples-1.0-SNAPSHOT-shaded.jar WordCount -Dwordcount.case.sensitive=true <inputPath> <outputPath> -skip <patternPath>パラメーターの記述は以下のとおりです。
-
inputPath: データ入力パス
-
outputPath: データ出力パス
-
patternPath: フィルタリングする文字を含むファイル。 data/patterns.txt を使用できます。
-
-
-
Hive
-
hive -f sample.hive -hiveconf inputPath=<inputPath>パラメーターの記述は以下のとおりです。
- inputPath: データ入力パス
-
-
Pig
-
pig -x mapreduce -f sample.pig -param tutorial=<tutorialJarPath> -param input=<inputPath> -param result=<resultPath>パラメーターの記述は以下のとおりです。
-
tutorialJarPath: JAR 依存関係。 lib/tutorial.jar を使用できます。
-
inputPath: データ入力パス
-
resultPath: データ出力パス
-
-
- E-MapReduce で作業している場合は、テストデータと JAR 依存関係を OSS にアップロードします。 パスルールは、上記のとおり OSSURI の定義に従います。
- クラスター内で使用する場合は、ローカルに格納できます。
ローカルに実行
- IntelliJ IDEA
- 準備
IntelliJ IDEA、Maven、IntelliJ IDEA 用の Maven プラグイン、IntelliJ IDEA 用の Scala および Scala プラグインをインストールします。
- 開発プロセス
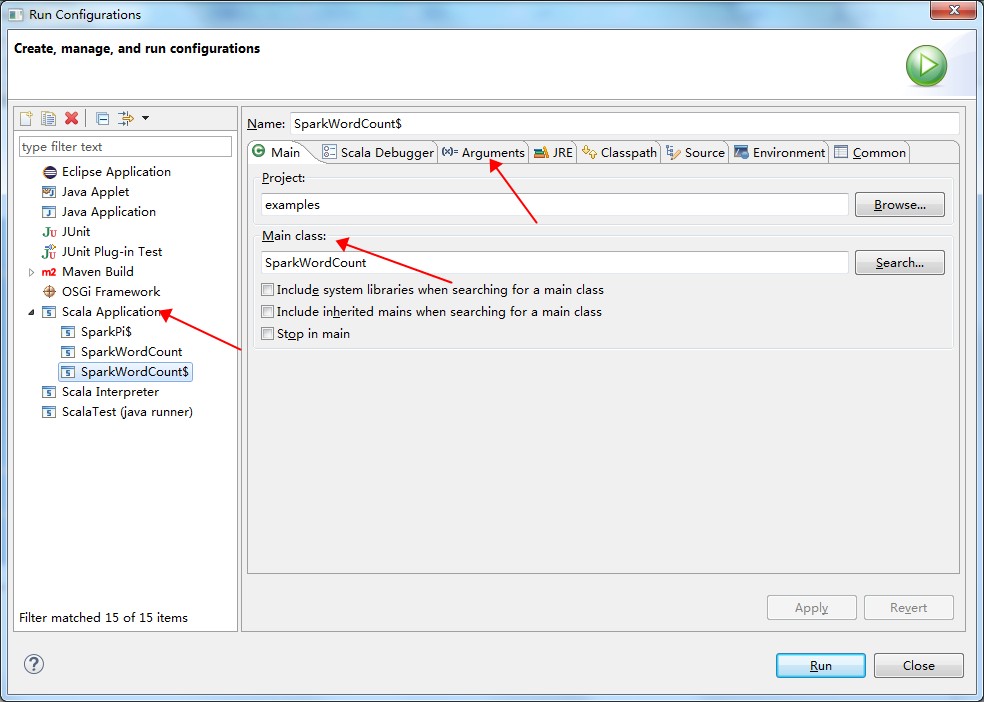
- ダブルクリックして SparkWordCount.scala を入力します。
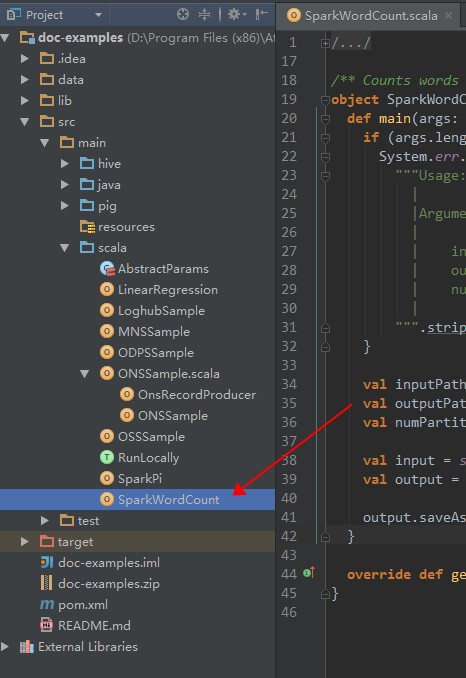
- 方向ボタンをクリックしてジョブ設定ページに入ります (次の図を参照)。
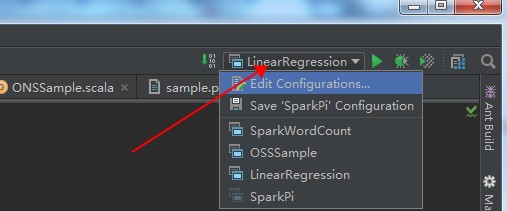
- SparkWordCount を選択し、必要なジョブパラメーターをジョブパラメーターボックスに入力します。
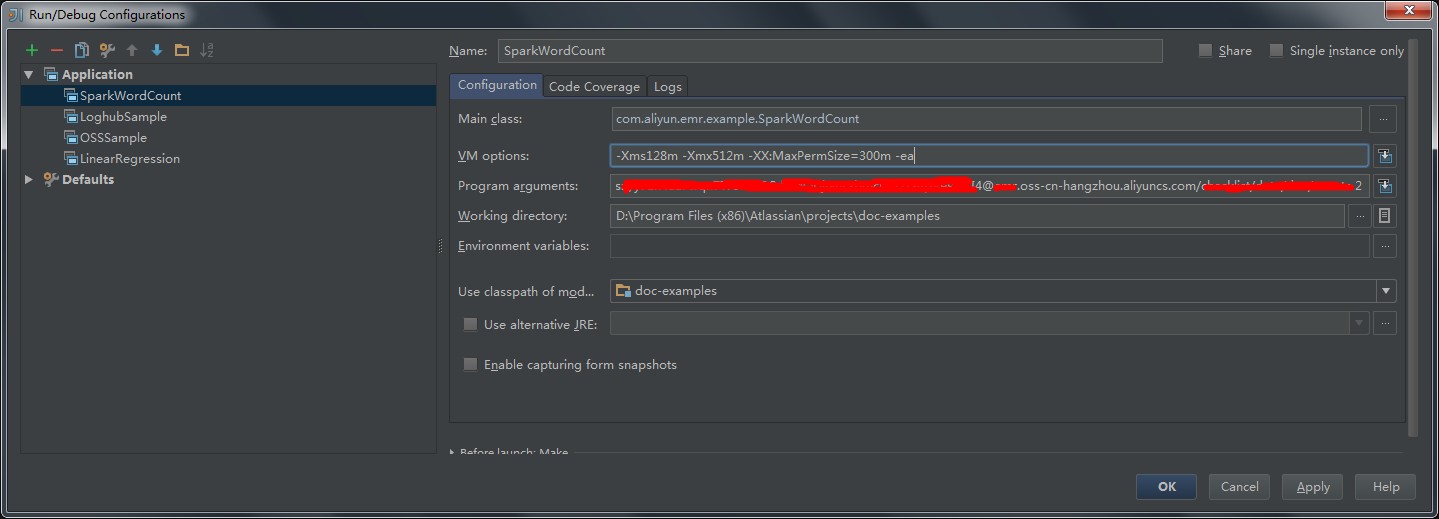
- [OK] をクリックします。
- [実行] をクリックしてジョブを実行します。
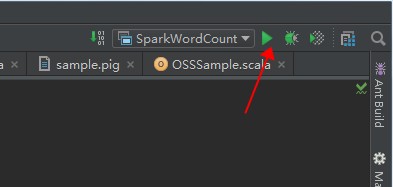
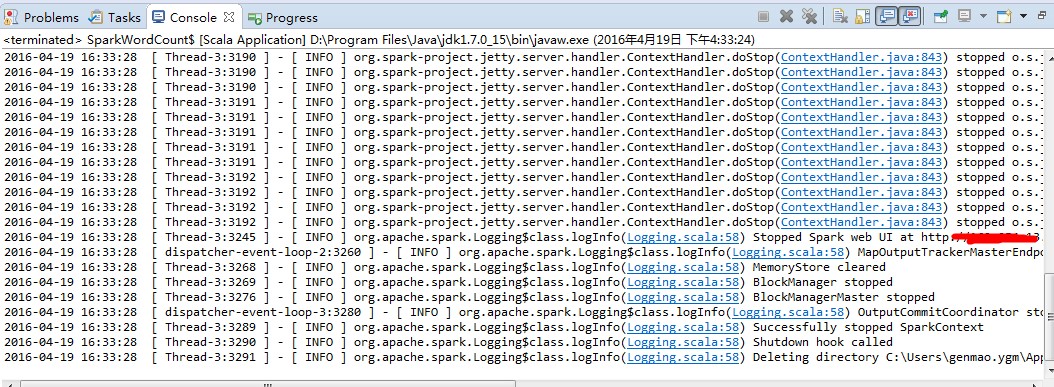
- ジョブログを閲覧します。
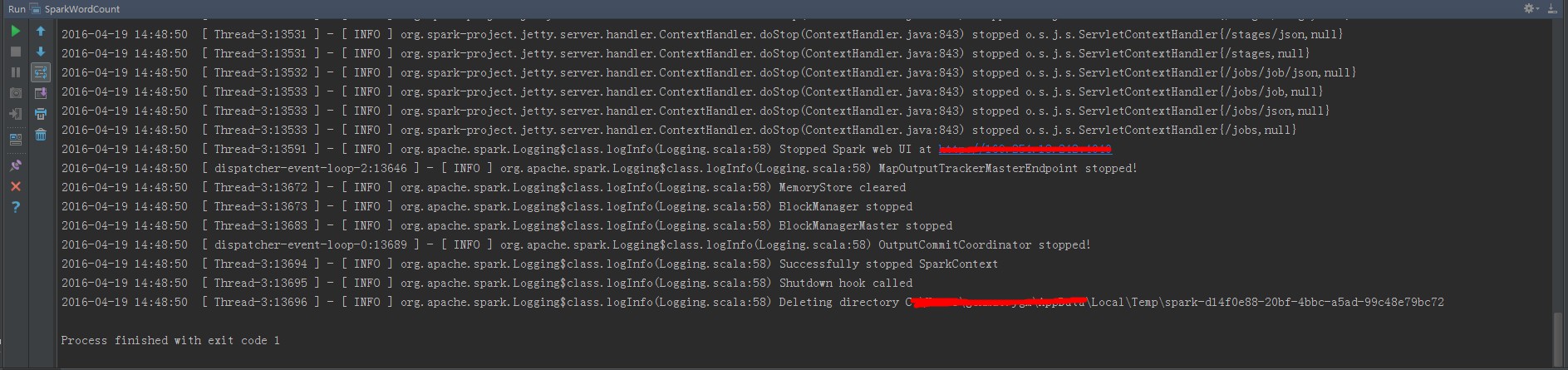
- ダブルクリックして SparkWordCount.scala を入力します。
- 準備
- Scala IDE for Eclipse
- 準備
Scala IDE for Eclipse、Maven、および Eclipse 用の Maven プラグインをインストールします。
- 開発プロセス
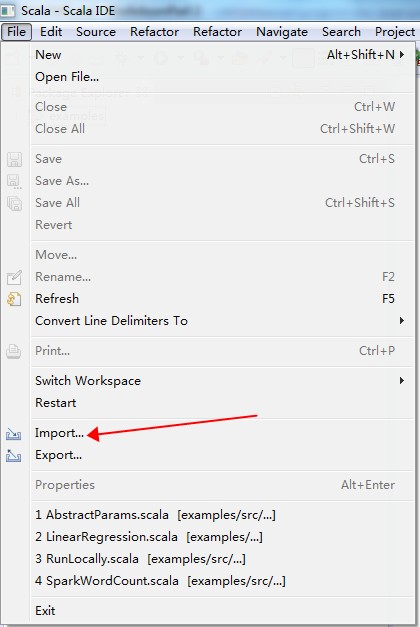
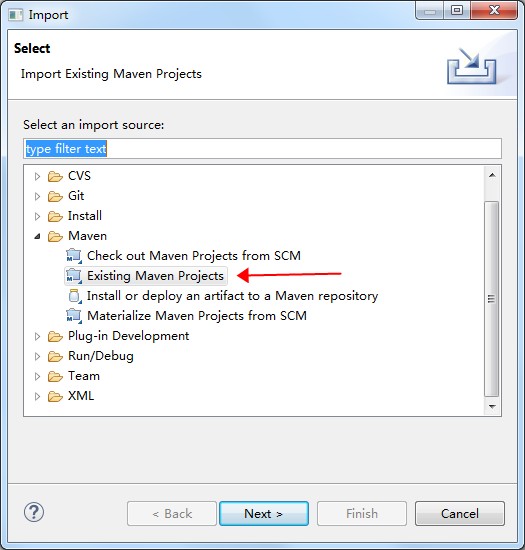
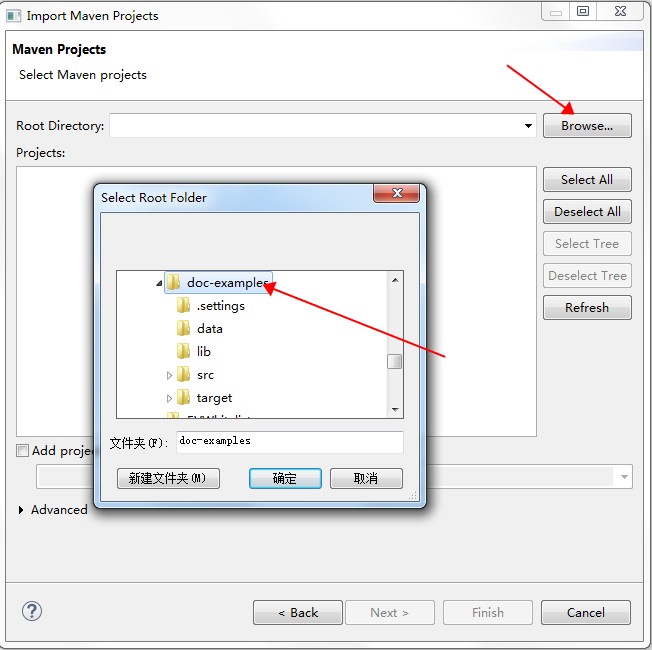
- 次の図のとおりプロジェクトをインポートします。
- The shortcut for Run as Maven ビルドでの実行時のショートカットは Alt + Shift + X, M です。プロジェクト名を右クリックして をクリックすることもできます。
- コンパイル後に実行するジョブを右クリックし、[設定の実行] を選択して設定ページに入ります。
- 設定ページで [Scalaアプリケーション] を選択してジョブのメインクラスとパラメーターを設定します (次の図を参照)。
- [実行] をクリックします。
- コンソールの出力ログを閲覧します (次の図を参照)。
- 次の図のとおりプロジェクトをインポートします。
- 準備









