- Graph のコードをコンパイルし、ローカルデバッグを使用して基本テストを実行します。
- クラスタのデバッグを実行し、結果を確認します。
例
このセクションでは、SSSP アルゴリズムを例として使用し、 Eclipse を使用した Graph プログラムの開発とデバッグの方法について説明します。
手順
- Java プロジェクトを作成します (例:graph_examples)。
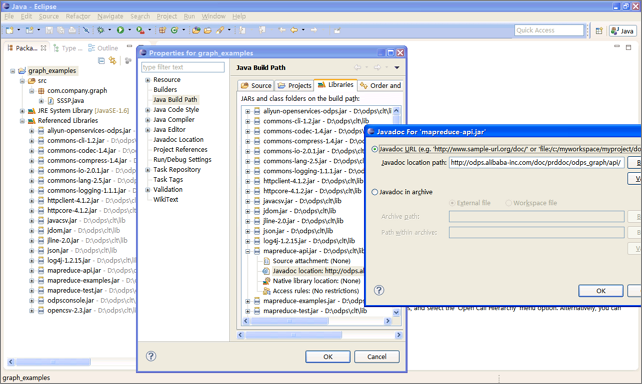
- MaxCompute クライアントの lib ディレクトリ内の jar パッケージを Eclipse プロジェクトのビルドパスに追加します。 次の図は、設定済みの
Eclipse プロジェクトを示します。
- MaxCompute Graph プログラムを開発します。
実際の開発プロセスでは、例 (SSSP など) をコピーしてから変更することがよくあります。 この例では、パッケージパスのみが package com.aliyun.odps.graph.example に変更されています。
- パッケージをコンパイルし、ビルドします。
Eclipse 環境で、ソースコードディレクトリ (src ディレクトリ) を右クリックし、[Export] > [Java] > [jar file] の順に選択し、 jar パッケージを生成します。 ターゲットの jar パッケージを保存するパスを選択します。 たとえば、
D:\\odps\\clt\\odps-graph-example-sssp.jarです。 - MaxCompute コンソールを使用して、SSSP を実行します。 関連する操作の詳細については、「クイックスタート」の「Graph の実行」をご参照ください。

ローカルデバッグ
MaxCompute Graph はローカルデバッグモードをサポートします。 Eclipse を使用してブレークポイントデバッグを実行します。
手順
- maven パッケージ odps-graph-local をダウンロードします。
- Eclipse プロジェクトを選択し、Graph ジョブのメインプログラムファイル (main 関数を含む) を右クリックし、[Run As] > [Run Configurations] の順に実行して実行パラメーターを設定します。
- [Arguments] タブページで、Program引数を、メインプログラムの入力パラメーターとして
1 sssp_in sssp_outに設定します。 - [Arguments] タブページで、VM 引数を以下のとおり設定します。
-Dodps.runner.mode=local -Dodps.project.name=<project.name> -Dodps.end.point=<end.point> -Dodps.access.id=<access.id> -Dodps.access.key=<access.key>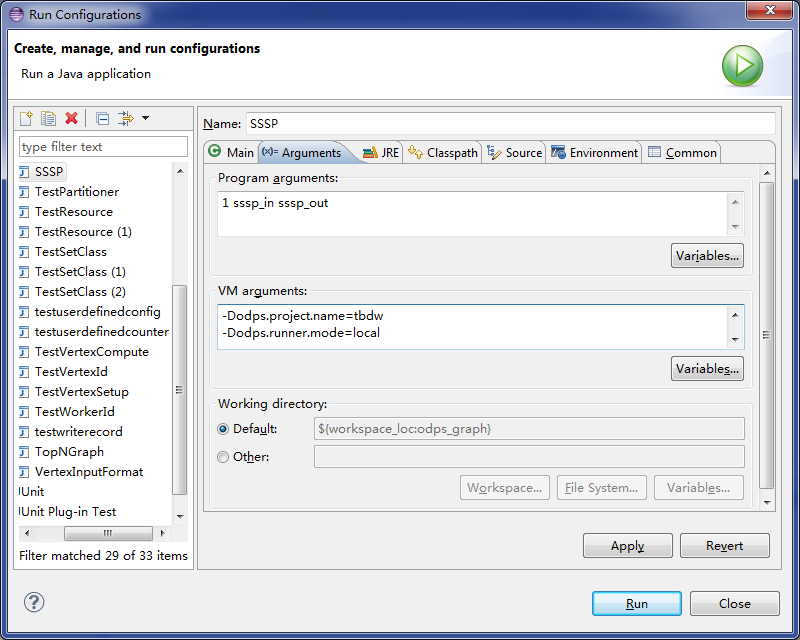
- MapReduce がローカルモード (odps.end.point の値が指定されていない) の場合、warehouse に sssp_in と sssp_out
テーブルを作成し、sssp_in のデータを追加する必要があります。 入力データは以下のとおりです。
1,"2:2,3:1,4:4" 2,"1:2,3:2,4:1" 3,"1:1,2:2,5:1" 4,"1:4,2:1,5:1" 5,"3:1,4:1"warehouse の詳細については、「MapReduce のローカル実行」をご参照ください。
- [Run] をクリックします。
注 MaxCompute クライアントの conf/odps_config.ini の設定を確認し、パラメーターを設定します。 上記パラメーターは共通で使用されます。 以下に、他のパラメーターについて説明します。
- odps.runner.mode: パラメーター値はローカルです。 このパラメーターはローカルデバッグ機能に必要です。
- odps.project.name: 必須です。 現在のプロジェクトを指定します。
- odps.end.point: 任意です。 現在の MaxCompute サービスのアドレスを指定します。 このパラメーターが指定されていないと、テーブルまたはリソースのメタデータが warehouse からのみ読み取られ、アドレスが存在しない場合に例外が発生します。このパラメーターが指定されていると、データは最初に warehouse から読み取られ、次に、アドレスが存在しない場合は、リモート MaxCompute から読み取られます。
- odps.access.id: MaxCompute サービスに接続するための ID を示します。 このパラメーターは odps.end.point が指定されている場合にのみ有効です。
- odps.access.key: MaxCompute サービスに接続するためのキーを示します。 このパラメーターは odps.end.point が指定されている場合にのみ有効です。
- odps.cache.resources: 使用中のリソースリストを指定します。 このパラメーターは jar コマンドの -resources と同じ効果があります。
- odps.local.warehouse: ローカルの warehouse パスを示します。 このパラメーターが定されていなれば、デフォルトで ./warehouse に設定されています。
Eclipse のローカルで SSSP デバッグが実行された後、以下の情報が出力されます。Counters: 3 com.aliyun.odps.graph.local.COUNTER TASK_INPUT_BYTE=211 TASK_INPUT_RECORD=5 TASK_OUTPUT_BYTE=161 TASK_OUTPUT_RECORD=5 graph task finish注 上の例では、sssp_in および sssp_out テーブルがローカルの warehouse に存在している必要があります。 sssp_in および sssp_out テーブルの詳細については、「クイックスタート」の「Graph の実行」をご参照ください。

ローカルジョブの一時ディレクトリ
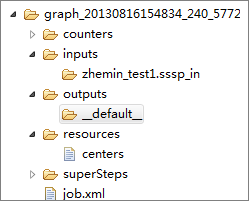
- counters: 実行中のジョブのカウント情報を保存します。
- inputs: ジョブの入力データを保存します。 データは優先的にローカルの warehouse から取得されます。 データがローカルに存在しない場合、MaxCompute
SDK はデータをサーバーから (odps.end.point が設定されている場合) 読み取ります。 入力はデフォルトで 10 データレコードを読み取ります。 このしきい値は
-Dodps.mapred.local.record.limitパラメーターで最大 10,000 まで変更可能です。 - outputs: ジョブの出力データを保存します。 ローカル warehouse が出力テーブルの場合、出力結果データはジョブ実行後にローカル warehouse の対応するテーブルを上書きします。
- resources: ジョブが使用するリソースを保存します。 inputs 同様、データは優先的にローカル warehouse から取得されます。 データがローカルに存在しない場合、データは MaxCompute SDK を使用してサーバーから (odps.end.point が設定されている場合) 読み取られます。
- job.xml: ジョブの設定を示します。
- superstep: 反復の度にメッセージ永続化に関する情報を保存します。
log4j.properties_odps_graph_cluster_debug に配置されている必要があります。
クラスタデバッグ
ローカルデバッグ後、テストのためにクラスタへジョブを送信します。
手順
- MaxCompute クライアントを設定します。
add jar /path/work.jar -f;コマンドを実行し、jar パッケージを更新します。- jar コマンドを実行してジョブを実行し、実行ログと結果データを確認します。
パフォーマンスチューニング
次のセクションでは、MaxCompute Graph フレームワーク上での一般的なパフォーマンスチューニング方法を説明します。
ジョブパラメーターの設定
- setSplitSize(long): 入力テーブルの分割サイズを示します。 単位は MB です。 値は 0 より大きくなければならず、デフォルト値は 64 です。
- setNumWorkers(int): ジョブの Worker 数を指定します。 値の範囲は [1,1000] で、デフォルト値は –1 です。 Worker 数はジョブの入力バイト数と分割サイズによって異なります。
- setWorkerCPU(int): Map の CPU リソースを示します。 1 コア CPU は 100 リソースを含んでいます。 値の範囲は [50, 800] で、デフォルト値は 200 です。
- setWorkerMemory(int): Map のメモリリソースを示します。 単位は MB です。 値の範囲は [256 MB, 12 GB] で、デフォルト値は 4,096 MB です。
- setMaxIteration(int): 反復の最大数を指定します。 デフォルト値は –1 です。 値が 0 以下の場合、反復の最大数はジョブ終了条件となりません。
- setJobPriority(int): ジョブの優先度を指定します。 値の範囲は [0, 9] で、デフォルト値は 9 です。 値が大きいほど、優先順位は低くなります。
- Worker 数を増やすには、setNumWorkers() メソッドを使用することができます。
- 分割サイズを縮小し、ジョブがデータをロードする速度を上げるには、setSplitSize() メソッドを使用することができます。
- Worker の CPU またはメモリを増やします。
- 反復の最大数を設定します。 アプリケーションが結果の精度について高い要件を持たない場合は、反復の回数を減らしてプロセスをスピードアップさせることができます。
- splitNum == workerNum の場合、各 Worker は 1 つの分割をロードします。
- splitNum > workerNum の場合、各 Worker は 1 つ以上の分割をロードします。
- splitNum < workerNum の場合、各 Worker は 0 または 1 つの分割をロードします。
そのため、最初の 2 つの条件に一致する場合、workerNum と splitSize を調整することで高速データロードを実現できます。反復フェーズでは、 workerNum だけを調整する必要があります。
ランタイムパーティショニングを false に設定する場合、 setSplitSize を使用して Worker 数を制御することを推奨します。 3 つめの条件については、一部の Worker の頂点の数が 0 であるかもしれません。jar コマンドの前に、 setNumWorkers と setSplitSize 同様の効果がある set odps.graph.split.size=<m>; set odps.graph.worker.num=<n>; を使用できます。
もう 1 つの共通するパフォーマンスの問題はデータスキューです。 たとえば、カウンターでは、ある Worker で処理される頂点と辺の数が、他の Worker で処理される量を大きく上回ることがあります。
データスキューは通常、キーに対応する頂点、辺またはメッセージの数が、他のキーを大きく上回る場合に発生します。 データ量の多いキーは、少数の Worker で処理され、結果的にこれらの Worker の実行時間は長くなります。
- コンバイナを使用して、そのようなキーに対応する頂点のメッセージをローカルで集計し、送信メッセージ数を減らします。
- サービスロジックを改善します。
コンバイナを使用する
メッセージとネットワークデータトラフィック量を保存するメモリを縮小し、ジョブの実行時間を短縮するため、コンバイナを定義します。 詳しい情報は、MaxCompute SDK の 「コンバイナ」 をご参照ください。
データ入力量を減らす
- 入力データ量を減らす: 意思決定アプリケーションでは、データのサンプリング後にサブセットを処理することで取得できる結果は、全体の精度ではなく結果の精度にのみ影響します。 そのため、特別なデータサンプリングを実行し、データを入力テーブルにインポートして処理することができます。
- 使用されていないフィールドの読み取りを回避する: MaxCompute Graph フレームワークの Tableinfo クラスは、全テーブルの読み取りやテーブルパーティションの読み取りではなく、特定の列 (列名配列を使用して送信される) の読み取りをサポートします。 これにより入力データ量が減り、ジョブのパフォーマンスが向上します。
組み込み jar パッケージ
- commons-codec-1.3.jar
- commons-io-2.0.1.jar
- commons-lang-2.5.jar
- commons-logging-1.0.4.jar
- commons-logging-api-1.0.4.jar
- guava-14.0.jar
- json.jar
- log4j-1.2.15.jar
- slf4j-api-1.4.3.jar
- slf4j-log4j12-1.4.3.jar
- xmlenc-0.52.jar