Alibaba Cloud Elasticsearch では、Elasticsearch インスタンスからデータノードを削除して、データノードをダウングレードできます。
- この機能は、 サブスクリプションを使用し、1 つのゾーン にデプロイされている Alibaba Cloud Elasticsearch インスタンスのみをサポートします。 従量課金を使用するインスタンス、または複数のゾーン間にデプロイされているインスタンスはサポートしていません。 Alibaba Cloud Elasticsearch では、インスタンス内のデータノード数のみを変更できます。 専用マスターノード、クライアントノード、および Kibaba ノードの仕様やディスク容量をダウングレードすることはできません。
- インスタンスからデータノードを削除する場合、システムはインスタンスを再起動する必要があります。 ワークロードに悪影響を与えないことを確認してから、インスタンスを再起動する操作を実行してください。
手順
- Alibaba Cloud Elasticsearch コンソールにログインします。
- [インスタンス] ページで、[インスタンス ID/名前] 列にあるインスタンスの ID をクリックします。
- [基本情報] セクションで、[クラスターのスケールイン] をクリックします。
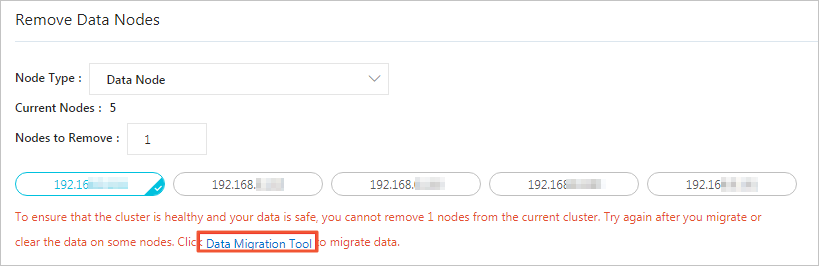
- [クラスターのスケールイン] をクリックした後、[クラスターのスケールイン] ページの [ノードタイプ] を指定し、ノードリストから削除するデータノードを選択します。

- (オプション) データを移行する
データのセキュリティを保証するために、削除されたデータノードにデータが保存されていないことを確認する必要があります。 これらのデータノードにデータが保存されている場合、システムはデータの移行を求めるメッセージを表示します。 データ移行プロセスの完了後、インデックスデータはデータノードに保存されず、データノードに書き込まれることもありません。
- ポップアップメッセージで、[データ移行ツール] をクリックします。
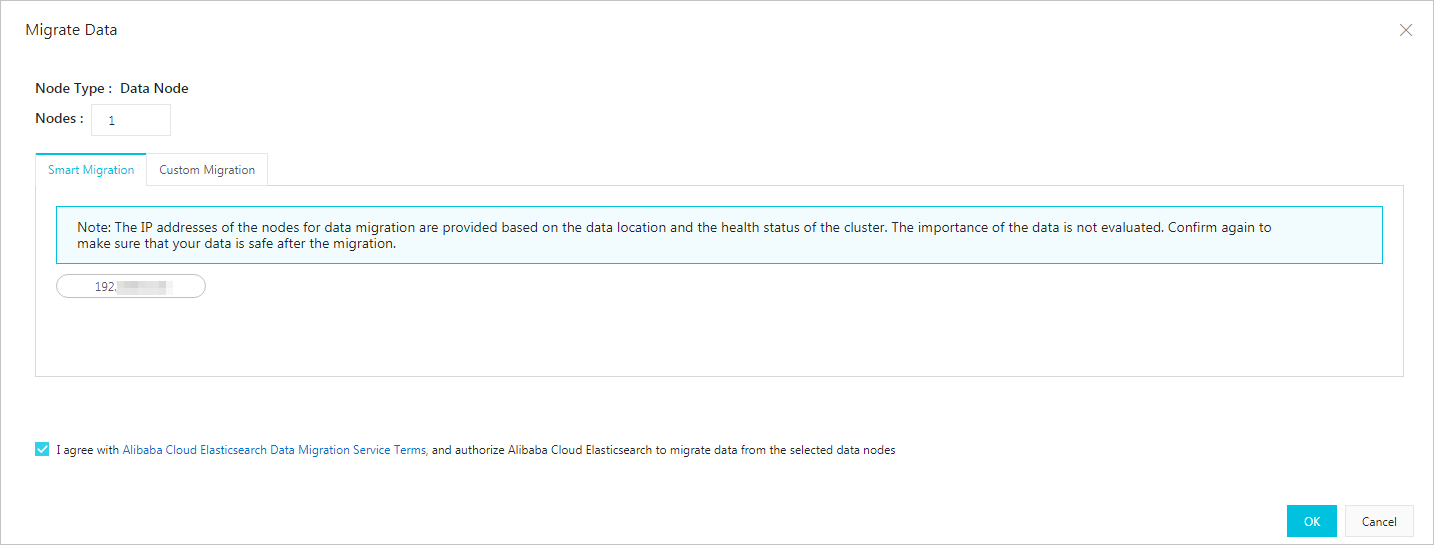
- [データの移行] ページで、データ移行方法を選択します。
- スマート移行
システムは、ダウングレードするデータノードを自動的に選択します。 データ移行の条件に同意するには、チェックボックスをオンにして、[OK] をクリックする必要があります。
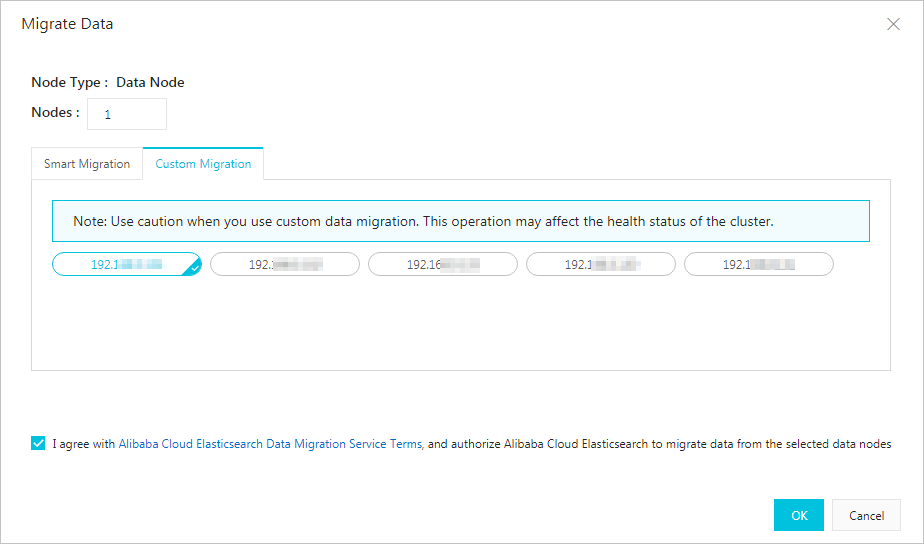
- カスタム
ダウングレードするデータノードを選択する必要があります。
- スマート移行
- チェックボックスをオンにしてデータ移行の条件を受け入れ、 [OK] をクリックします。
- ポップアップメッセージで、[データ移行ツール] をクリックします。
- データの移行後、 [OK]をクリックします。
データノードの削除を確認した後、インスタンスが再起動されます。 再起動プロセス中に、 [タスク] ページで進行状況を確認できます。 インスタンスを再起動すると、データノードがインスタンスから削除されます。
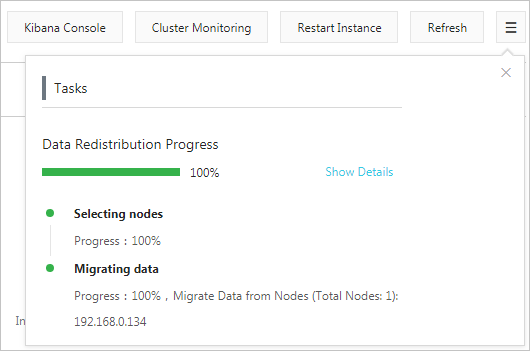 注 データ移行プロセス中に、 [タスクリスト] ページで、[停止] をクリックして、移行タスクを停止できます。
注 データ移行プロセス中に、 [タスクリスト] ページで、[停止] をクリックして、移行タスクを停止できます。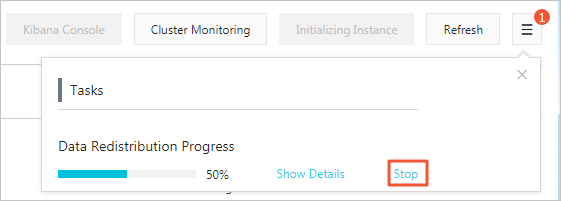







移行をロールバックする
- 削除されたデータノードの IP アドレスを照会します。
[タスクリスト] ページで、削除されたデータノードの IP アドレスを確認するか、またはKibana コンソールにログインし、次のリクエストを送信できます。
//クラスターの設定を照会します。 GET _cluster/settings次の結果が返されます。{ "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": "192.168. ***. ***,192.168. ***. ***,192.168. ***. ***" } } } } } } - データをロールバックします。
Kibana にログインし 、[コンソール] タブで次のリクエストを送信して、データをロールバックします。
- 一部のデータノードでデータをロールバックします。 exclude パラメーターを使用して、ロールバックしないデータノードを除外します。
PUT _cluster/settings { "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": "192.168. ***. ***,192.168. ***. ***" } } } } } } - すべてのデータノードでデータをロールバックします。
PUT _cluster/settings { "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": null } } } } } }
- 一部のデータノードでデータをロールバックします。 exclude パラメーターを使用して、ロールバックしないデータノードを除外します。
- データがロールバックされているかどうかを確認します。
Kibana コンソールにログインし、
GET _cluster/settingsリクエストを送信して 、 返されたデータノード IP アドレスに基づき、ロールバックタスクの進捗状況を確認します。 シャードが対応するデータノードに再割り当てされているかどうかに基づいて、ロールバックの進行状況を確認することもできます。注 データ移行またはロールバックタスクのステータスを確認するには、GET _cat/shards? vリクエストを送信します。
エラーメッセージ
- この操作により、シャード配布エラーが発生したり、ストレージ、CPU、またはメモリリソースが不足したりする場合があります。
原因:データの移行またはダウングレードタスクが完了した後、クラスターに、システムデータを格納したり、ワークロードを処理したりするのに十分なストレージ、メモリ、または CPU リソースがありません。
解決策:
GET _cat/indices? vリクエストを送信して、クラスターがスケールインされた後、クラスターのインデックスレプリカの数がデータノードの数を超えているかどうか確認できます。 また、クラスターがデータを保存したり、リクエストを処理するのに十分なリソースを確保できるよう、ディスク使用量などのリソース使用量がしきい値を下回っているかどうかを確認する必要もあります。 これらの要件が満たされていない場合は、クラスターのアップグレード を実行してください。 - クラスターがタスクを実行中かエラー状態です。 後でもう一度やり直してください。
解決策 :
GET _cluster/healthリクエストを送信してクラスターのステータスを確認するか、 [ Intelligent Maintenance] ページに移動して原因を確認できます。 - クラスター内のノードにデータが含まれています。 最初にデータを移行する必要があります。
解決策:データ移行の詳細については、 手順 の 6 をご参照ください。
- 予約するノードの数を 2 より大きく、既存のノードの半分より多くする必要があります。
原因 :クラスターの信頼性を確保するには、リザーブドノードの数は 2 より大きくなければなりません。 クラスターの安定性を確保するには、毎回ロールバックまたは削除するデータノードの数が、既存のデータノードの半分以下でなければなりません。
ソリューション:これらの要件が満たされていない場合は、ロールバックする必要があるデータノードを再選択するか、 クラスターのアップグレード を実行してください。
- 現在の Elasticsearch クラスター設定が、この操作をサポートしていません。 最初に Elasticsearch クラスター設定を確認してください。
ソリューション :
GET _cluster/settingsリクエストを送信して、クラスター設定を照会し、クラスター設定にデータ割り当てを禁止する設定が含まれているかどうかを確認できます。 - auto_expand_replicas
原因:一部のユーザーが、X-Pack でサポートされている権限管理機能を使用している場合があります。 以前の Elasticsearch バージョンでは、この機能はデフォルトで、
"index.auto_expand_replicas" : "0-all"設定を .security および .security-6 インデックスに 適用しています。 これにより、データを移行するとき、またはノードをスケールインする際にエラーが発生します。ソリューション:インデックス設定auto_expand_replicasを次のとおり変更することを推奨します。- インデックス設定を照会します。
GET .security/_settings次の結果が返されます。{ ".security-6" : { "settings" : { "index" : { "number_of_shards" : "1", "auto_expand_replicas" : "0-all", "provided_name" : ".security-6", "format" : "6", "creation_date" : "1555142250367", "priority" : "1000", "number_of_replicas" : "9", "uuid" : "9t2hotc7S5OpPuKEIJ****", "version" : { "created" : "6070099" } } } } } - 以下のいずれかの方法を使用して、設定を変更します。
//方法 1: PUT .security/_settings { "index" : { "auto_expand_replicas" : "0-1" } }//方法 2: PUT .security/_settings { "index" : { "auto_expand_replicas" : "false", "number_of_replicas" : "1" } }重要 実際のニーズに基づいてレプリカの数を設定します。 インデックスごとに少なくとも 1 つのレプリカを確保し、レプリカの数が使用可能なデータノードの数以下であることを確認する必要があります。
- インデックス設定を照会します。