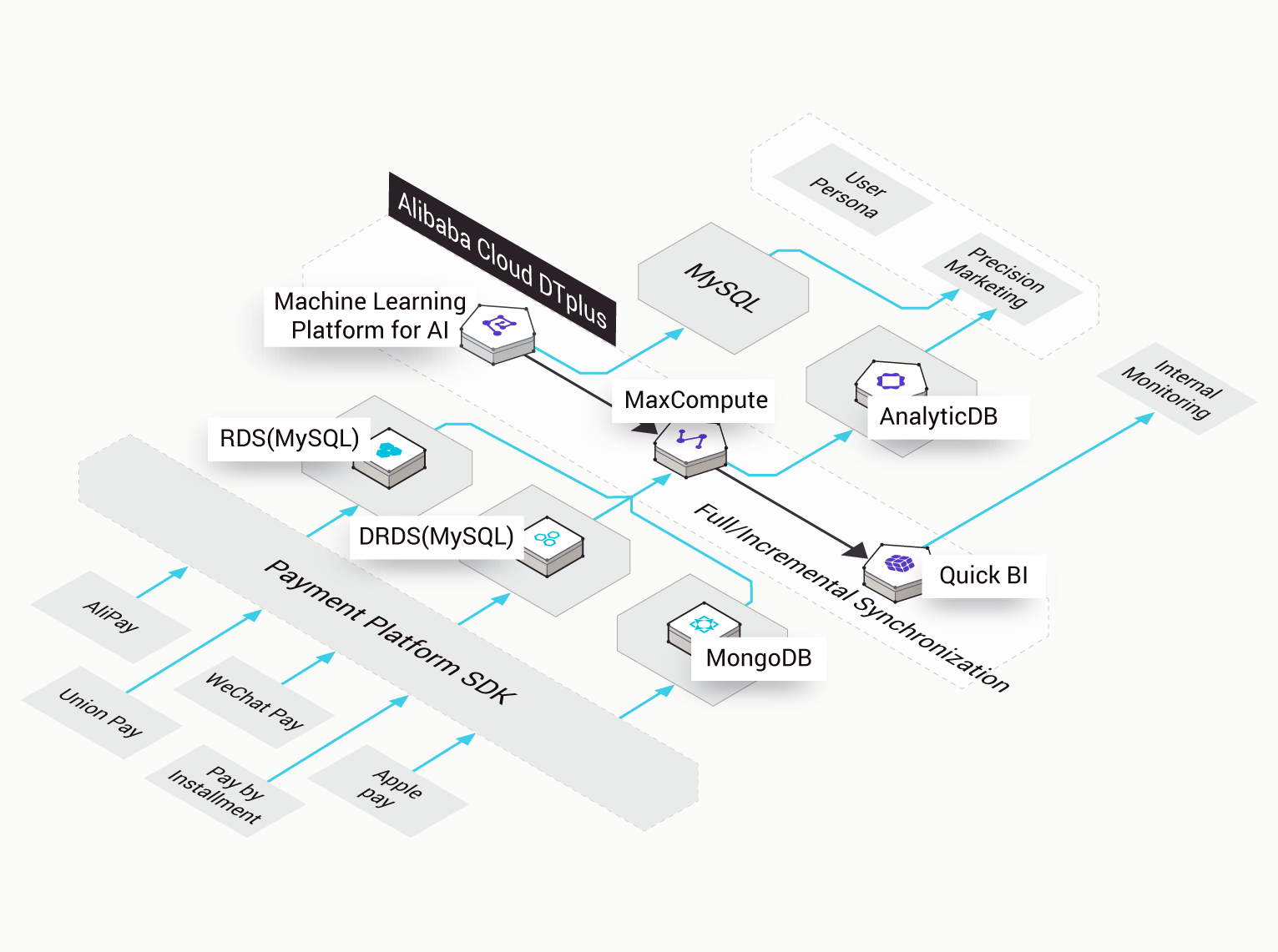
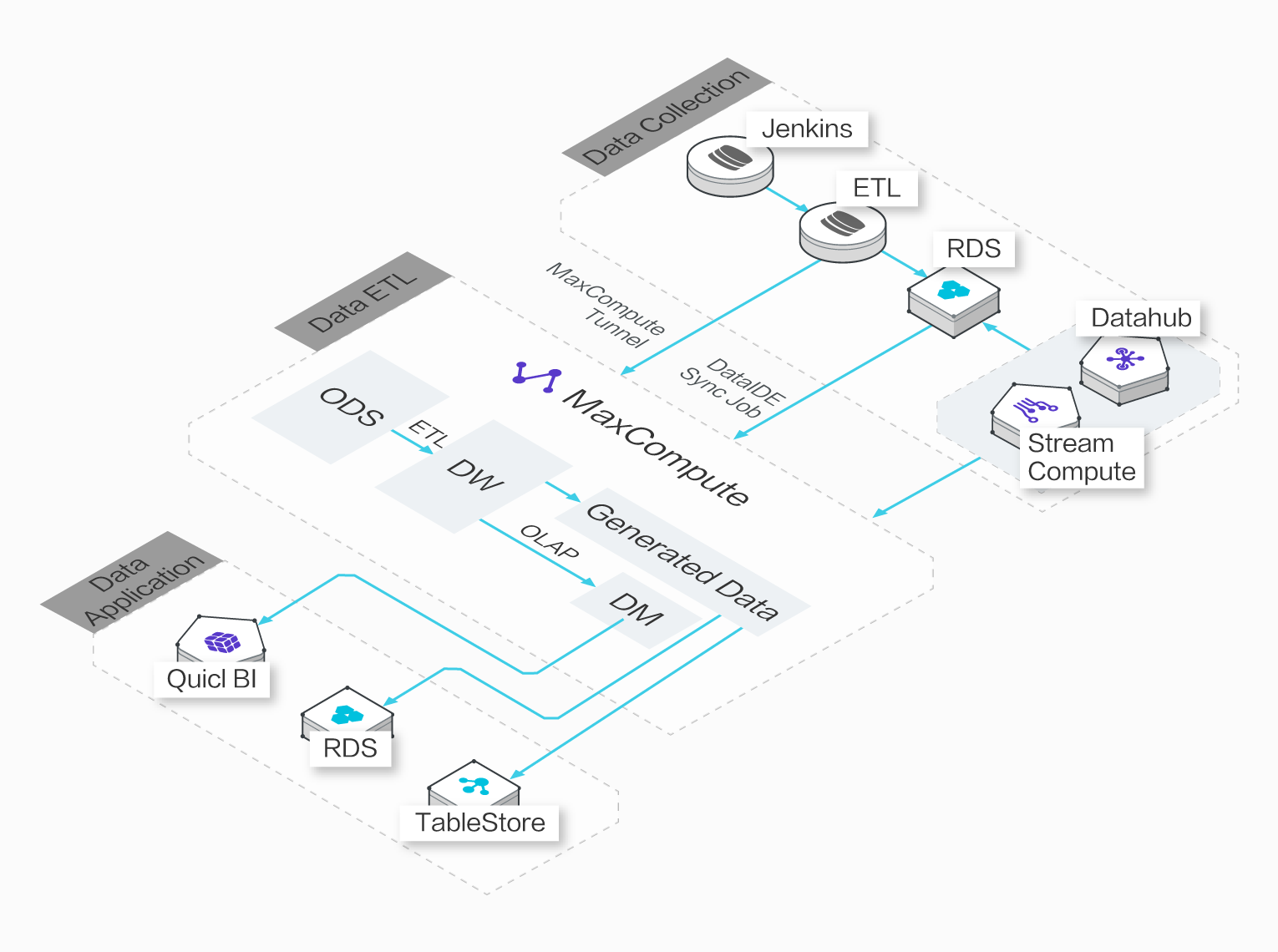
MaxCompute (旧プロダクト名 ODPS) は、大規模データウェアハウジングのためのフルマネージドかつマルチテナント形式のデータ処理プラットフォームです。さまざまなデータインポートソリューションと分散計算モデルにより、大規模データの効率的な照会、運用コストの削減、データセキュリティを実現します。
利点

-
大規模コンピューティングとストレージ
EB レベルのデータ保存と計算が可能です。

-
主要な計算モデル
SQL、MapReduce、Graph、および MPI の反復アルゴリズムが利用可能です。

-
セキュリティ
7 年以上にわたり、安定したオフライン分析サービスを提供し、マルチレベルでのサンドボックス保護とモニタリングが可能です。
-
コスト削減
企業のプライベートクラウドよりも効率的なコンピューティングとストレージを提供し、購入コストを 20% から 30% 削減します。
特徴
-
Tunnel 機能
データ Tunnel、履歴データ Tunnel、増分データ Tunnel をサポートしています。
複数のデータ Tunnel と履歴データ Tunnel
MaxCompute は、Tunnel を使用してデータを送信します。Tunnel はスケーリングさせることができ、日常的に PB レベルのデータをインポート/エクスポートします。複数の Tunnel を介して、すべてのデータや履歴データをインポートできます。Tunnel サービスは、Java SDK をサポートしています。MaxCompute クライアント上でコマンドを使用して、クラウドとファイルやデータを交換できます。
リアルタイム増分データ Tunnel
MaxCompute は、リアルタイムでデータをアップロードするための DataHub サービスを提供しています。このサービスは低レイテンシで、簡単に操作できます。また、増分データのインポートに非常に適しています。DataHub では、Logstash、Flume、Fluentd、Sqoop などの複数のデータ転送プラグインがサポートされます。Log Service を使用して簡単にログを MaxCompute に送信できるほか、ビッグデータ開発キットを使用してログの解析とマイニングを実行することもできます。
-
テーブル形式でのデータ保存
MaxCompute はすべてのデータをテーブル形式で保存し、ファイルシステムを公開していません。高い圧縮比で圧縮された列式保存により、コストが大幅に削減されます。MaxCompute の圧縮比は 5 です。
-
計算モデル
SQL、MapReduce、Graph などの計算モデルをサポートしています。
SQL
MaxCompute SQL は、標準的な SQL 構文と Hive 構文に準じています。両者を組み合わせた構文は Hibernate Query Language (HQL) と似ているので、SQL や HQL のプログラマーは MaxCompute SQL を簡単に使用することができます。SQL 計算モデルを実行するためのコンピューティングフレームワークは、一般的な MapReduce モデルよりも効率的です。ただし、MaxCompute SQL はトランザクション、インデックス、更新、削除をサポートしていません。
MapReduce
MaxCompute は Java MapReduce プログラミングモデルを提供します。MaxCompute には、ファイル API がありません。システム内のテーブルとの間でデータを読み書きする必要があります。そのため、MaxCompute の MapReduce モデルは、オープンソースコミュニティの MapReduce モデルとは異なります。たとえば、並べ替えやハッシュのアルゴリズムをカスタマイズできません。ただし、開発プロセスはシンプルになります。また、MaxCompute は Extended MapReduce (MR²) モデルを提供します。このモデルでは、Map 操作の後に、複数の Reduce 操作を実行できます。
Graph
MapReduce で K-Means や PageRank などの複雑な反復計算を行った場合、タスクを完了するのに非常に時間がかかります。そのため、MaxCompute は Graph モデルを使用して、効率的にタスクを実行します。
-
セキュリティ
MaxCompute は、マルチテナント形式のコンピューティングプラットフォームです。デフォルトでは、テナントは分離されていて、データを共有しません。ただし、同一プロジェクトグループ内の他のユーザーに、特定のデータに対する権限を設定することができます。
利用イメージ
-
コスト削減

-
データウェアハウス

-
ログのビッグデータ解析

-
データ管理

-
プレシジョンマーケティング

-
大容量データの分析


East Environment Energy
コスト効率の良い迅速なクラウド移行
すべての関連するサービスを 3 か月以内にクラウドに移行する支援をしました。East Environment Energy ではビッグデータプラットフォームを構築せずに移行し、データ処理時間を 3 分の 2 以上短縮しました。また、クラウド上のグリーンエネルギー利用データも確保しています。
利点
-
主要業務への集中
3 か月以内にすべての関連するサービスをクラウドに移行する支援をします。クラウド上に大量のリソースを置くことで、業務遂行に役立ちます。
-
コスト削減
人材投入や研究開発にかかるコストを大幅に削減できます。
-
安全性と信頼性
豊富な機能と安定したパフォーマンスにより、お客様のデータをクラウド上に確実に保護できます。
関連プロダクトとサービス
Xiaohongchun
データウェアハウス
データウェアハウスはクラウドコンピューティングおよびビッグデータのアプリケーションに不可欠です。Xiaohongchun は MaxCompute を使用してデータウェアハウスを構築中です。
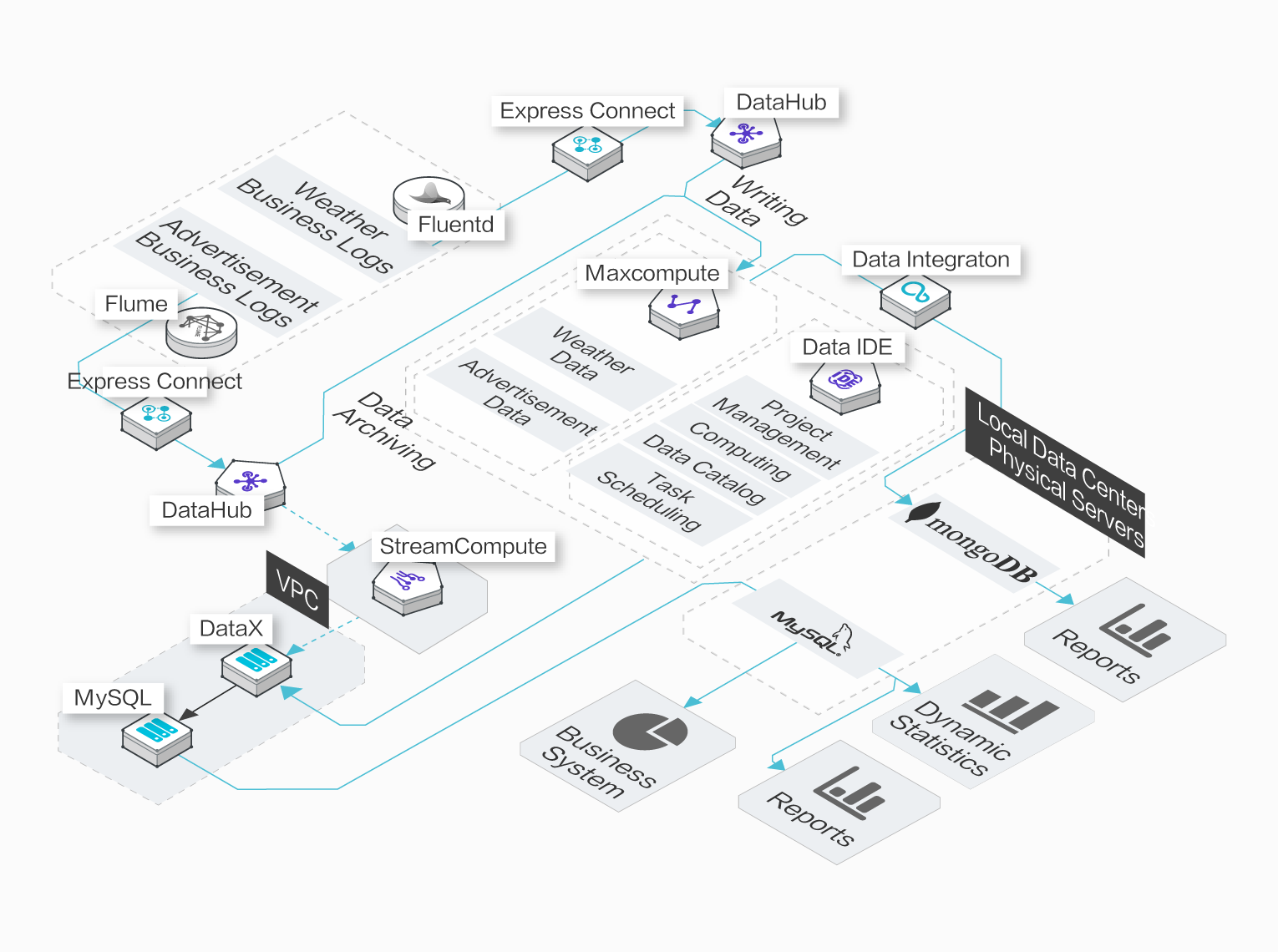
Moji Weather
効率的な開発およびコスト効率に優れたストレージとコンピューティング
Moji Weather ではログ分析機能を MaxCompute に移行したことで、開発効率が 5 倍向上し、ストレージおよびコンピューティングコストは 70% 削減されました。毎日 2TB のログを処理・分析し、分析結果を考慮した経営戦略の決定を実現しました。

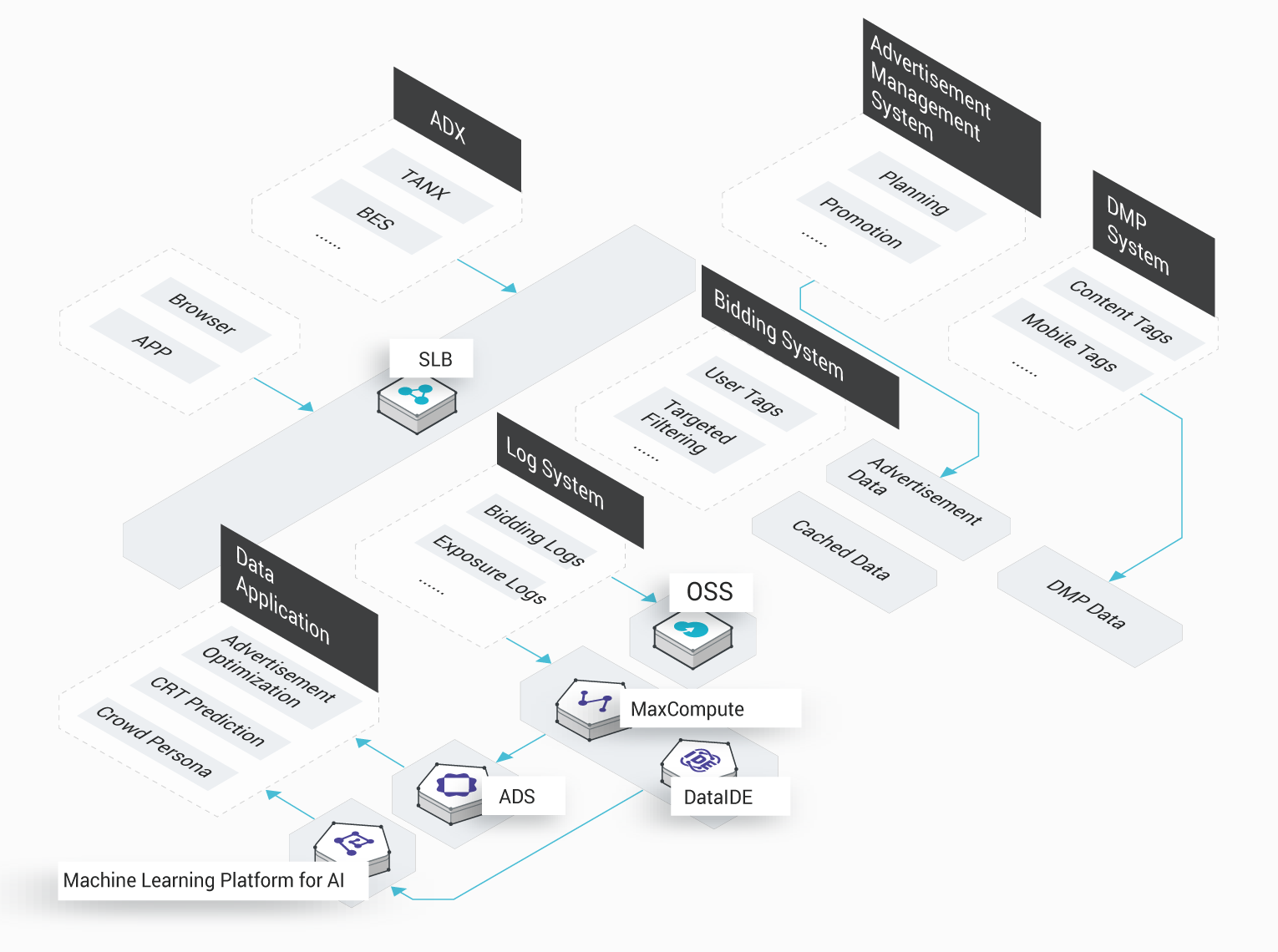
Huihe Marketing
ビッグデータをベースとした高精度なマーケティング
Huihe Marketing では、MaxCompute を使用してビッグデータに基づく高精度なマーケティングプラットフォームを構築しました。このプラットフォームで MaxCompute にすべてのログを格納し、DataWorks でオフラインスケジューリングと分析を実行します。
利点
-
コスト効率の良い大量データの分析
大容量のログの統計・分析処理を実行することで、コスト効率の良い開発が可能になります。
-
リアルタイムのデータ検索・分析
検索リクエストに対して即時に結果を返します。
-
利用者に優しい機械学習機能
アルゴリズムモデルの品質は最終的な収益にも反映されます。MaxCompute では利用者に優しい機械学習機能を提供します。