Kubernetes クラスターを使用して GPU コンピューティングを実行する際、必要に応じて GPU ノードラベルを使って、GPU デバイスがインストールされているノードにアプリケーションをスケジュールできます。
始める前に
- GPU ノードを持った Kubernetes クラスターの作成が必要です。 詳細は、「Kubernetes GPU クラスターを設定して、GPU スケジューリングに対応する」をご参照ください。
- Master ノードへの接続が必要です。これにより、ノードラベルやその他の情報の参照を簡単に行えます。 詳細は、「kubectl を利用した Kubernetes クラスターへの接続」をご参照ください。
このタスクについて
NVIDIA GPU ノードのデプロイ時、Alibaba Cloud で実行されている Kubernetes により GPU 属性が検出され、ノードラベルの情報として公開されます。 ノードラベルは以下のメリットがあります。
- ノードラベルにより GPU ノードのフィルターが簡単に行えます。
- ノードラベルを、アプリケーションデプロイに関するスケジューリングの条件として利用することができます。
手順
- Container Service-Kubernetes の左側のナビゲーションウインドウで 、 を選択します。
注 このページの例では、クラスターには 3 つの Worker ノードがあり、そのうち 2 つは GPU デバイスにマウントされています。 検証のため、ノードの IP アドレスを表示する必要があります。
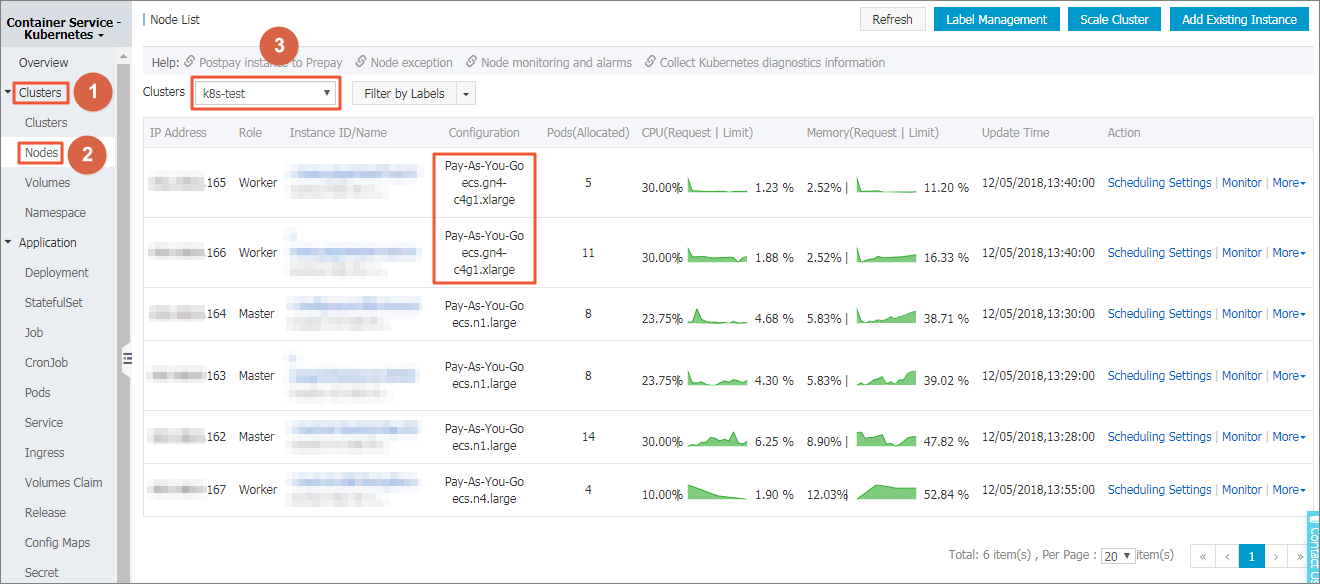
- GPU ノードを選択し、アクション列で を選択します。 Kubernetes ダッシュボード上で GPU ノードラベルを表示できます。
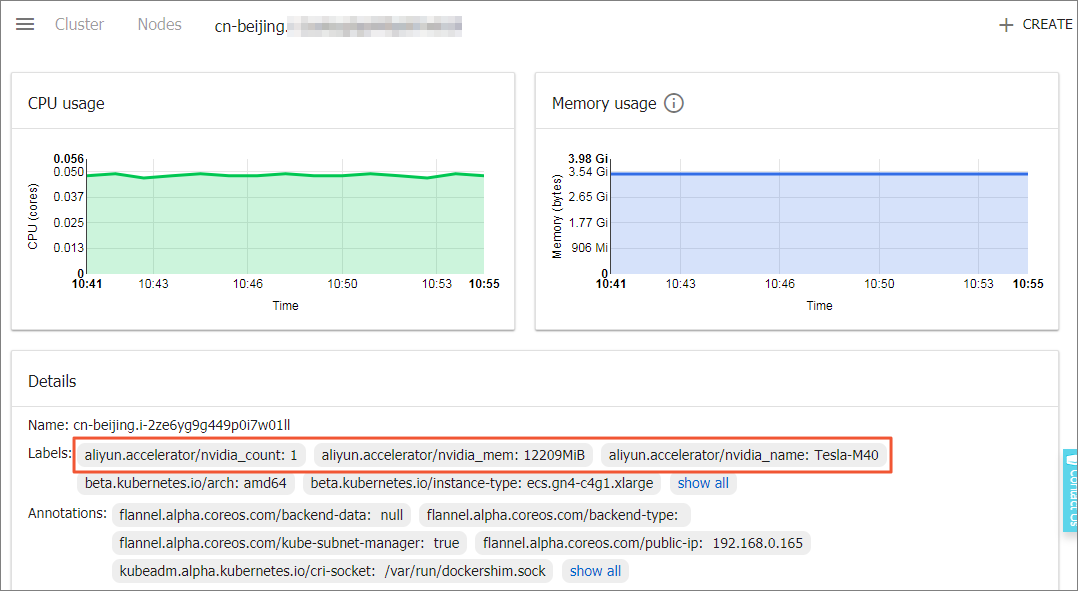
Master ノードにログインし、以下のコマンドを実行して、GPU ノードラベルを表示することもできます。
# kubectl get nodes NAME STATUS ROLES AGE VERSION cn-beijing.i-2ze2dy2h9w97v65uuaft Ready master 2d v1.11.2 cn-beijing.i-2ze8o1a45qdv5q8a7luz Ready <none> 2d v1.11.2 #Compare this node with the node displayed in the console to determine the GPU node. cn-beijing.i-2ze8o1a45qdv5q8a7lv0 Ready <none> 2d v1.11.2 cn-beijing.i-2ze9xylyn11vop7g5bwe Ready master 2d v1.11.2 cn-beijing.i-2zed5sw8snjniq6mf5e5 Ready master 2d v1.11.2 cn-beijing.i-2zej9s0zijykp9pwf7lu Ready <none> 2d v1.11.2GPU ノードを選択し、以下のコマンドを実行し GPU ノードラベルを表示します。
# kubectl describe node cn-beijing.i-2ze8o1a45qdv5q8a7luz Name: cn-beijing.i-2ze8o1a45qdv5q8a7luz Roles: <none> Labels: aliyun.accelerator/nvidia_count=1 #This field is important. aliyun.accelerator/nvidia_mem=12209MiB aliyun.accelerator/nvidia_name=Tesla-M40 beta.kubernetes.io/arch=amd64 beta.kubernetes.io/instance-type=ecs.gn4-c4g1.xlarge beta.kubernetes.io/os=linux failure-domain.beta.kubernetes.io/region=cn-beijing failure-domain.beta.kubernetes.io/zone=cn-beijing-a kubernetes.io/hostname=cn-beijing.i-2ze8o1a45qdv5q8a7luz ......この例では、GPU ノードは以下の 3 つのノードラベルを含んでいます。
キー 値 aliyun.accelerator/nvidia_countGPU コア数 aliyun.accelerator/nvidia_memMiB 単位の GPU メモリー量 aliyun.accelerator/nvidia_nameNVIDIA デバイスの GPU コンピューティングカードの名称 同じタイプの GPU クラウドサーバーでは、同じ GPU コンピューティングカード名を共有します。 そのため、このラベルをノードのフィルタリングに利用できます。
# kubectl get no -l aliyun.accelerator/nvidia_name=Tesla-M40 NAME STATUS ROLES AGE VERSION cn-beijing.i-2ze8o1a45qdv5q8a7luz Ready <none> 2d v1.11.2 cn-beijing.i-2ze8o1a45qdv5q8a7lv0 Ready <none> 2d v1.11.2 - Container Service コンソールのホームページに戻ります。 次に、左側のナビゲーションウインドウで、 を選択し、右上隅の [テンプレートによる作成] をクリックします。
- TensorFlow アプリケーションを作成し、GPU ノードにこのアプリケーションをスケジュールします。
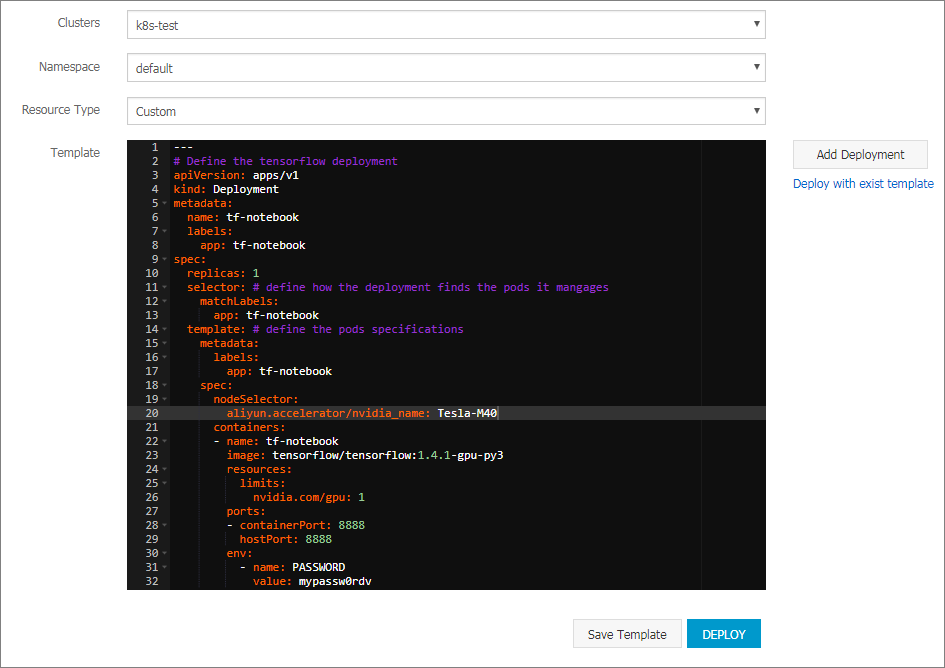 この例では、YAML テンプレートが以下のようにオーケストレーションされます。
この例では、YAML テンプレートが以下のようにオーケストレーションされます。--- # Define the tensorflow deployment apiVersion: apps/v1 kind: Deployment metadata: name: tf-notebook labels: app: tf-notebook spec: replicas: 1 selector: # define how the deployment finds the pods it manages matchLabels: app: tf-notebook template: #Define the pod specifications. metadata: labels: app: tf-notebook spec: nodeSelector: #This field is important. aliyun.accelerator/nvidia_name: Tesla-M40 containers: - name: tf-notebook image: tensorflow/tensorflow:1.4.1-gpu-py3 resources: limits: nvidia.com/gpu: 1 #This field is important. ports: - containerPort: 8888 hostPort: 8888 env: - name: PASSWORD value: mypassw0rdv
- TensorFlow アプリケーションを作成し、GPU ノードにこのアプリケーションをスケジュールします。
- 左側のナビゲーションウィンドウで、 を選択し、対象となるクラスターと名前空間を選択します。