このトピックでは、DataWorks のデータ同期機能を使用して自動的にパーティションを作成する方法と、RDS から MaxCompute へデータを動的に移行する方法を説明します。
準備
- MaxCompute
MaxCompute を有効化し、ワークスペースを作成します。 この例では、次の図に示すように、中国 (北京) にワークスペースを作成し、このワークスペースに関係する DataWorks サービスを有効化します。
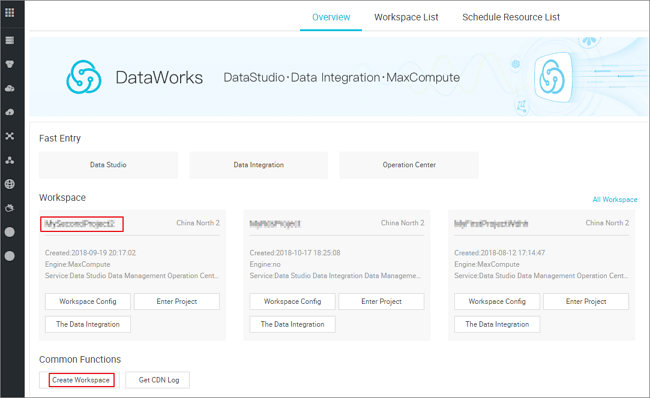 注 初めて DataWorks を使用する場合は、「準備」に記載されている操作を完了する必要があります。 たとえば、アカウントを用意し、ワークスペースロールを設定し、ワークスペースを設定する必要があります。 MaxCompute を有効化する方法の詳細については、「MaxCompute の有効化」をご参照ください。 DataWorks の準備が完了したら、DataWorks コンソールにログインし、該当するワークスペースを選択し、データ開発の [Enter Project] をクリックします。
注 初めて DataWorks を使用する場合は、「準備」に記載されている操作を完了する必要があります。 たとえば、アカウントを用意し、ワークスペースロールを設定し、ワークスペースを設定する必要があります。 MaxCompute を有効化する方法の詳細については、「MaxCompute の有効化」をご参照ください。 DataWorks の準備が完了したら、DataWorks コンソールにログインし、該当するワークスペースを選択し、データ開発の [Enter Project] をクリックします。 - データソースの追加
- RDS データソースを追加します。
DataWorks コンソールにログインし、[Data Integration] を選択して、[MySQL data source] を追加します。
- ODPS データソースを追加します。 詳細については、「MaxCompute データソースの設定」をご参照ください。
次の図に示すように、設定が完了したことを検証します。
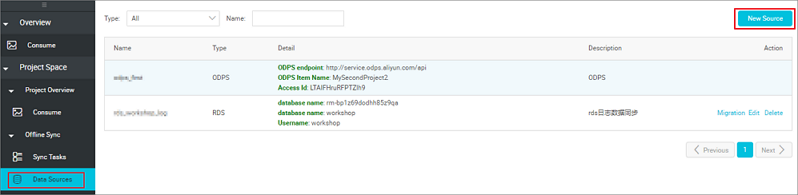
- RDS データソースを追加します。
- 宛先 ODPS データベースでテーブルが使用できることの確認
ODPS データベースに、ods_user_info_d という名前の宛先テーブルを作成します。 このテーブルは RDS のテーブルに対応します。 次の図に示すように、[Data Development] の下にある、[New ODPS SQL node] を右クリックし、create_table_ddl, and enter the table という名前のノードを作成し、テーブル作成文を入力します。
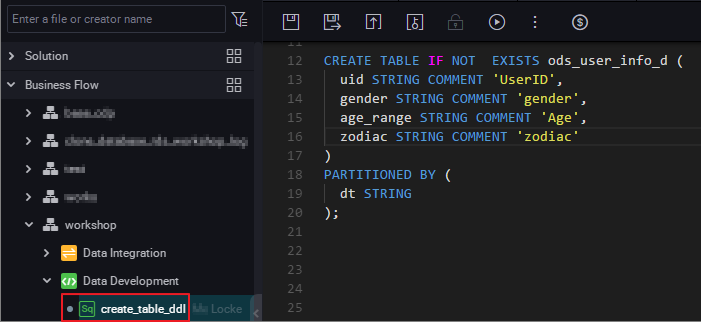 SQL 文は次のとおりです。
SQL 文は次のとおりです。CREATE TABLE IF NOT EXISTS ods_user_info_d ( uid STRING COMMENT 'UserID', gender STRING COMMENT 'gender', age_range STRING COMMENT 'Age', zodiac STRING COMMENT 'zodiac' ) PARTITIONED BY ( dt STRING );次の図に示すように、 の下にある [Create Table] を選択することも可能です。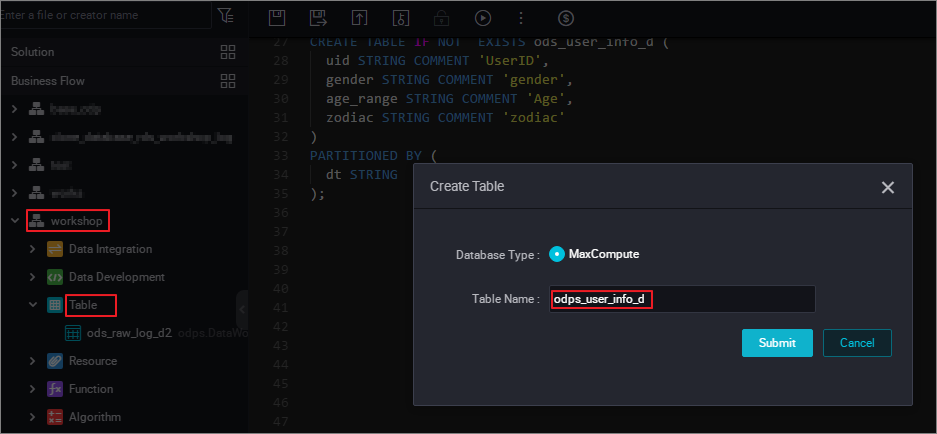
詳細については、「テーブルの作成とデータのアップロード」をご参照ください。
- ビジネスフローの作成
次の図に示すように、ワークショップを作成するために、 を選択し、[Create Business Flow] をクリックします。
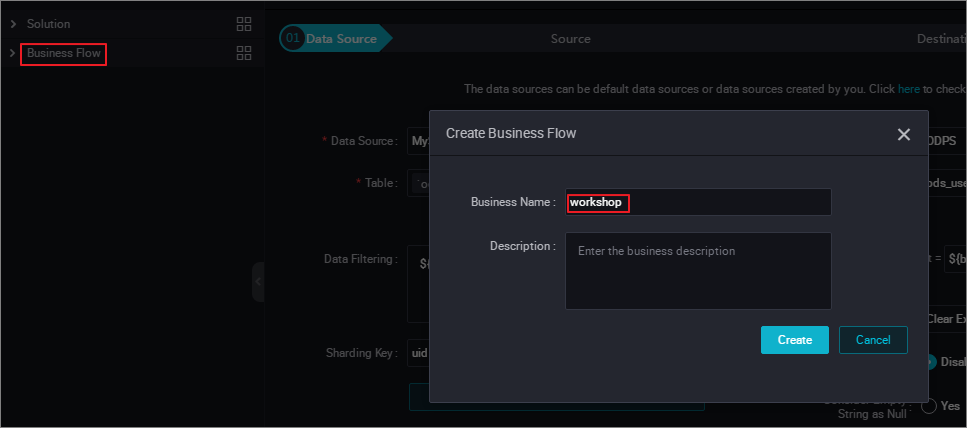
- 同期タスクノードの作成と設定
次の図に示すように、ワークショップビジネスフローの下に、rds_sync という名前の同期ノードを作成します。
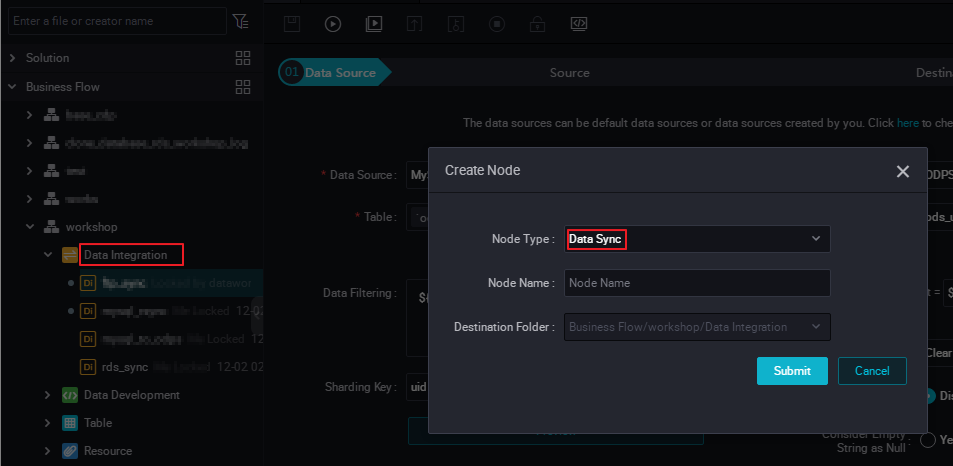






データ同期ノードの設定方法の詳細については、「DataWorks データ開発とO&M」をご参照ください。
パーティションの自動作成
準備が完了したら、日付ベースのパーティションが自動的に作成されるように、RDS のデータを毎日 MaxCompute と同期させる必要があります。
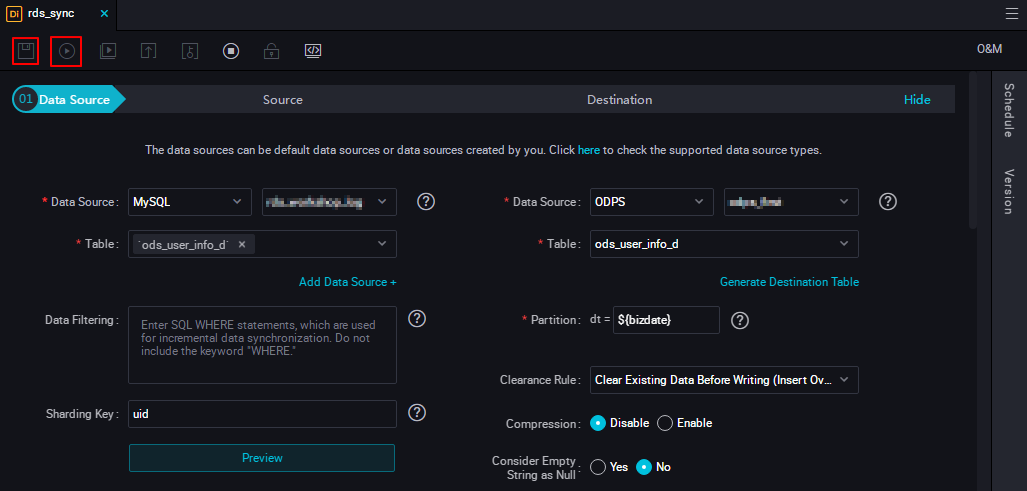
- 次の図に示すように、データソースとデータの宛先を選択します。
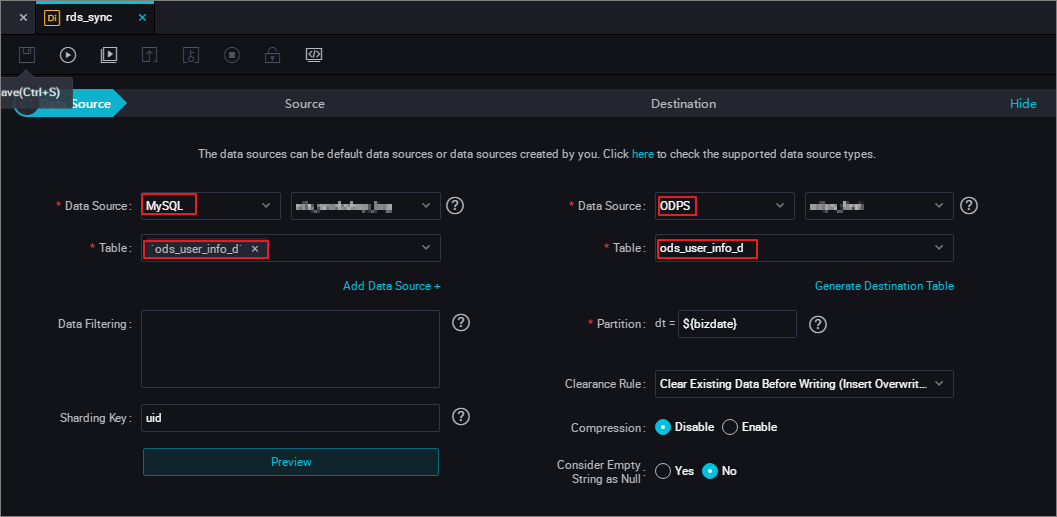
- 次の図に示すように、パラメーターを設定します。
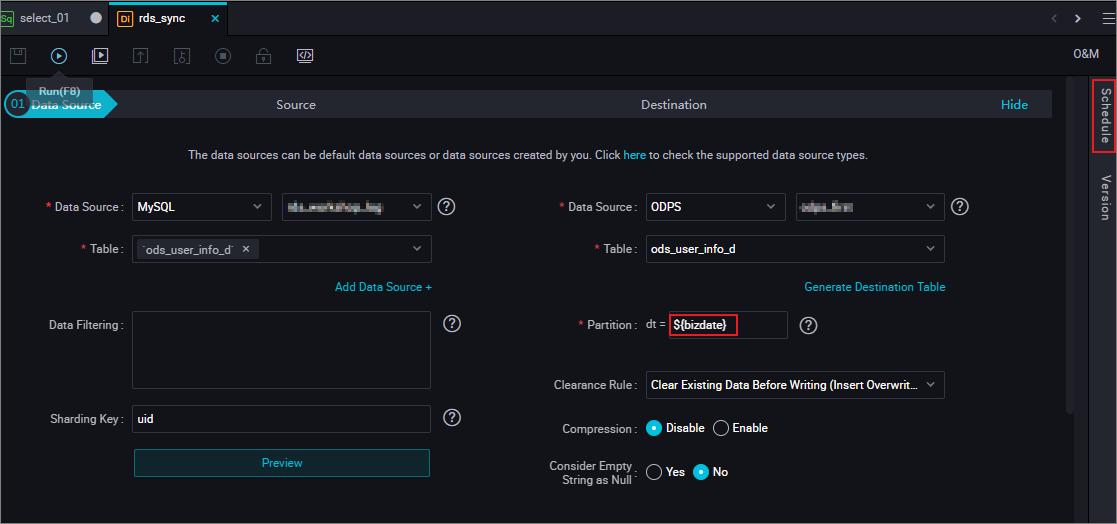 システム時刻パラメーター
システム時刻パラメーター${bizdate}が通常はデフォルトで使用されます。 形式は yyyymmdd です。 このパラメーターは [Destination] の下にある [Partition] パラメーターに対応します。 パーティション日付は営業日と呼ばれます。 ほとんどの場合、ユーザーは前日に生成されたビジネスデータを処理します。 したがって、データ同期タスクがスケジュールされて実行されるとき、パーティション日付は自動的にタスク実行日の 1 日前の日付に置き換えられます。 タスク実行日をパーティション値 (パーティション日付) として使用するには、次の図に示すように、[Schedule] を選択してパラメーターをカスタマイズする必要があります。カスタムパラメーターは、さまざまな形式で設定可能です。 デフォルトでは、リアルタイムの日付が表示されます。 必要に応じて、日付と形式を選択します。 カスタムパラメーターは、次の形式のうちいずれか 1 つで設定されます。
N years later:
$[add_months(yyyymmdd,12*N)]N years ago:
$[add_months(yyyymmdd,-12*N)]N months later:
$[add_months(yyyymmdd,N)]N months ago:
$[add_months(yyyymmdd,-N)]N weeks later:
$[yyyymmdd+7*N]N weeks ago:
$[yyyymmdd-7*N]N days later:
$[yyyymmdd+N]N days ago:
$[yyyymmdd-N]N hours later:
$[hh24miss+N/24]N hours ago:
$[hh24miss-N/24]N minutes later:
$[hh24miss+N/24/60]N minutes ago:
$[hh24miss-N/24/60]注- カスタムパラメーターの値計算式を編集するには、たとえば、
key1=$[yyyy-mm-dd]のように、角かっこ ([]) を使用する必要があります。 - カスタムパラメーターのデフォルトの計算単位は日です。 たとえば、
(yyyymmddhh24miss-(N/24/60 * 1 day))の計算結果は$[hh24miss-N/24/60]で示されます。 時、分、秒は hh24miss の形式になります。 - add_months の計算単位は月です。 たとえば、
(yyyymmddhh24miss-(12 N 1 month))-(M/24/60 1 day)の計算結果は$[add_months(yyyymmdd,12 N)-M/24/60]で示されます。 年、月、日はyyyymmddの形式になります。
詳細については、「パラメーター設定」をご参照ください。
- カスタムパラメーターの値計算式を編集するには、たとえば、
- テストを実行します。
次の図に示すように、[Save] をクリックしてすべての設定を保存し、[Run] をクリックします。
次の図に示すように、実行中のログを表示します。
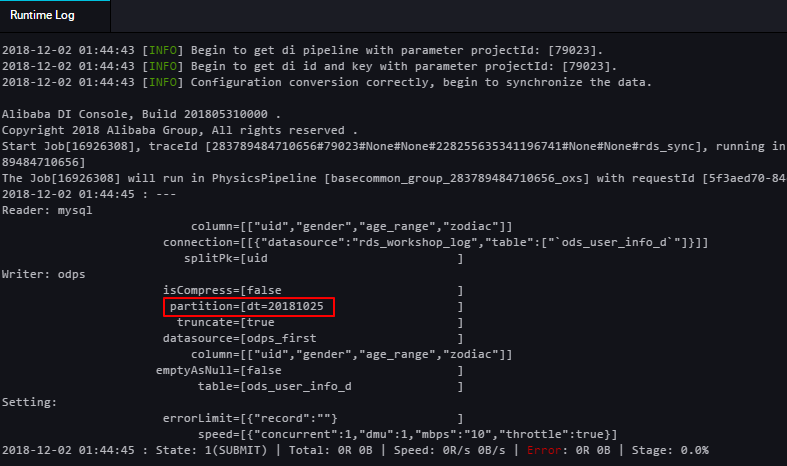 前の図でサンプルログが示すように、MaxCompute (表示されている名前は ODPS) 情報のパーティション値が dt=20181025 であることがわかります。 これはパーティション値が自動的に置き換えられたことを示します。 次の図に示すように、データが正常に ODPS テーブルへ移行されたことを検証します。
前の図でサンプルログが示すように、MaxCompute (表示されている名前は ODPS) 情報のパーティション値が dt=20181025 であることがわかります。 これはパーティション値が自動的に置き換えられたことを示します。 次の図に示すように、データが正常に ODPS テーブルへ移行されたことを検証します。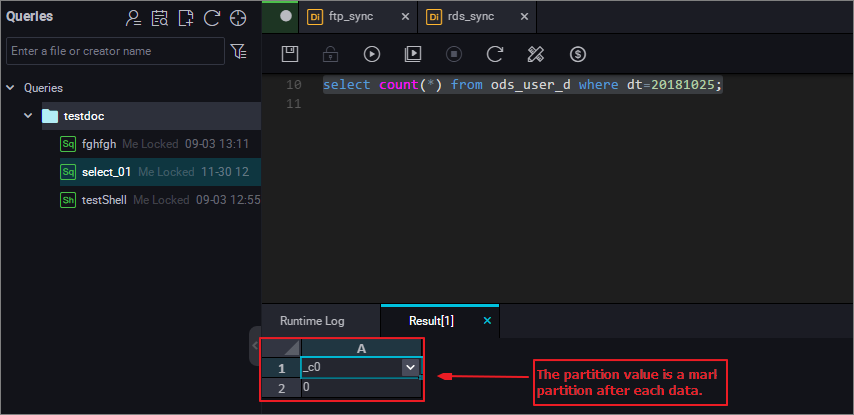 注 MaxCompute 2.0 では、パーティションテーブルクエリにパラメーター設定が必要です。 フルクエリはサポートされません。 SQL 文は次のとおりです。
注 MaxCompute 2.0 では、パーティションテーブルクエリにパラメーター設定が必要です。 フルクエリはサポートされません。 SQL 文は次のとおりです。--Check whether the data is successfully written to MaxCompute. select count(*)from ods_user_info_d where dt=business date;SELECT コマンドの詳細については、「Select 操作」をご参照ください。
データが ODPS テーブルへ移行され、パーティション値が正常に作成されたことがわかります。 スケジュールされた時間にタスクが実行されるとき、RDS のデータは自動的に MaxCompute の日付ベースのパーティションに同期されるようになります。





データパッチ
実行日より前に生成された多数の履歴データがあり、自動同期とパーティショニングを実装する場合は、DataWorks コンソール にログインし、[O&M] をクリックし、データ同期ノードを選択して、[Patch Data] をクリックします。
- 日付で RDS の履歴データをフィルタします。 たとえば、2018-09-13 に生成された履歴データをフィルタし、MaxCompute の 20180825 パーティションに自動的にデータを同期します。
次の図に示すように、WHERE 句を使用してRDS のデータをフィルタします。
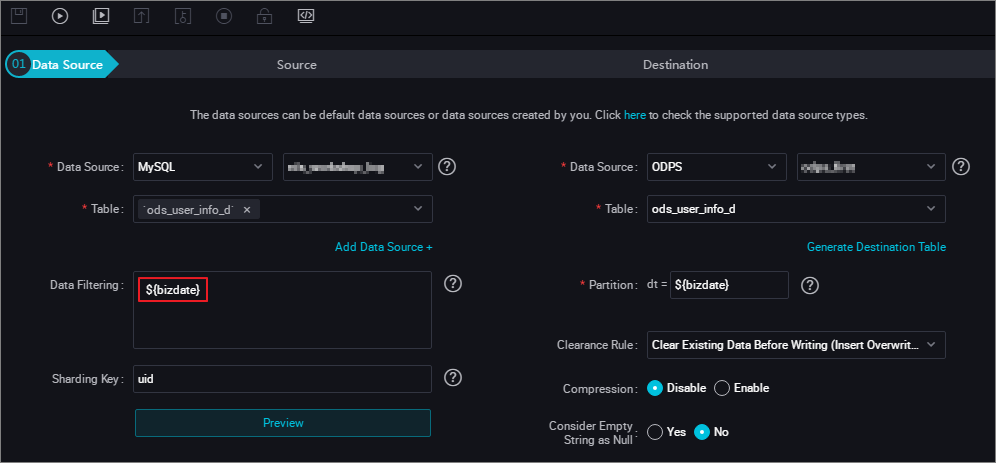
- データパッチを実行します。 を選択します。 次の図に示すように、データが送信されたら、 を選択し、rds_sync ノードを選択し、 を選択します。
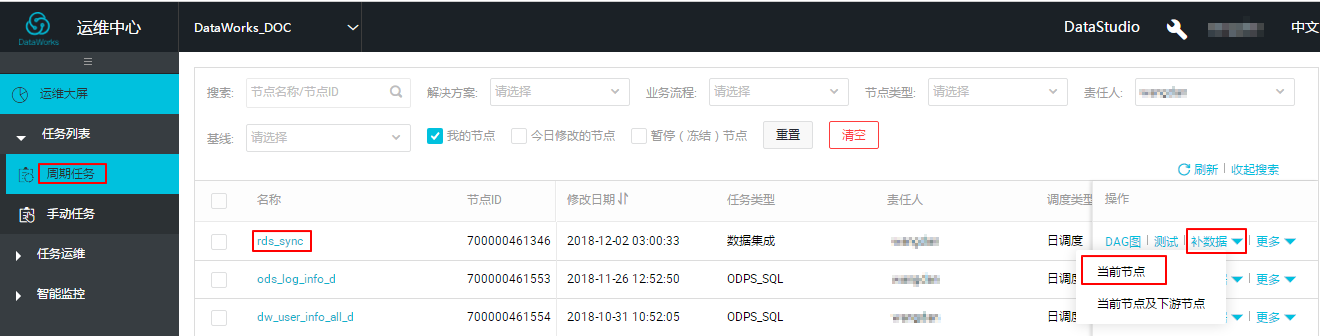
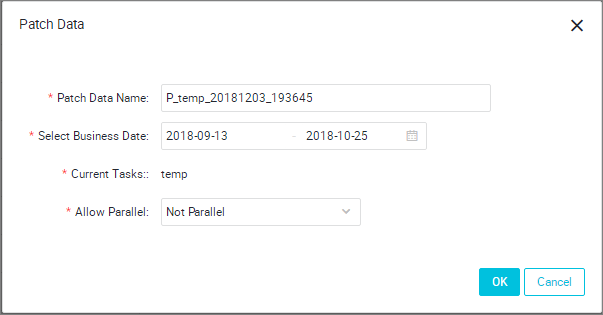
- 次の図に示すように、表示されたページで、営業日を選択します。
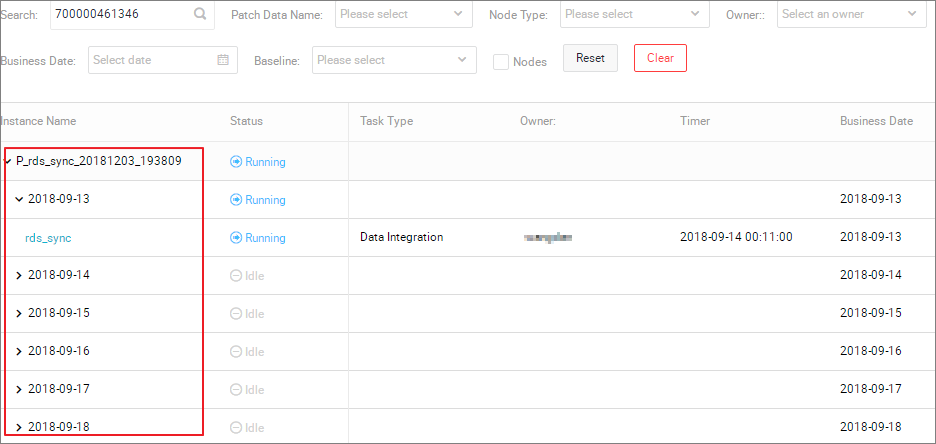
- をクリックします。 次の図に示すように、複数の同期タスクインスタンスが同じ時間に生成され、順番に実行されます。
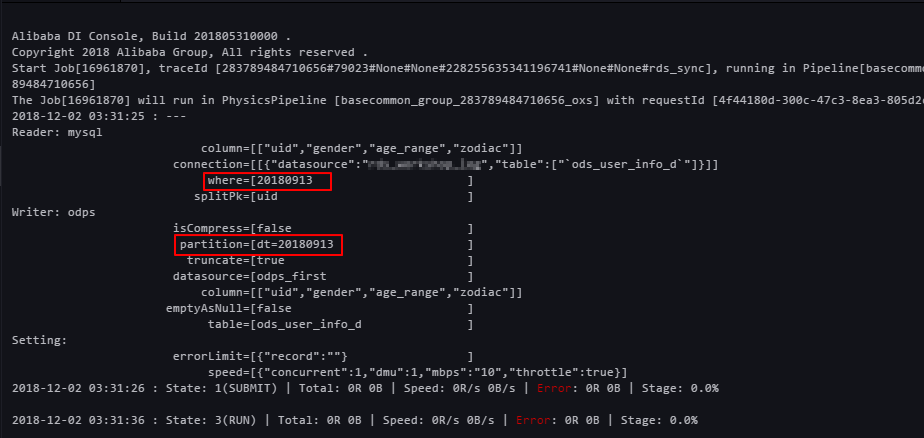
- 実行中ログを表示します。 RDS からデータを抽出する処理を確認します。 次の図に示すように、MaxCompute では、パーティションは自動的に作成されています。
 結果を表示します。 次の図に示すように、データが正常に書き込まれたかどうか、パーティションが作成されたかどうか、パーティションテーブルにデータが同期されたかどうかを確認します。
結果を表示します。 次の図に示すように、データが正常に書き込まれたかどうか、パーティションが作成されたかどうか、パーティションテーブルにデータが同期されたかどうかを確認します。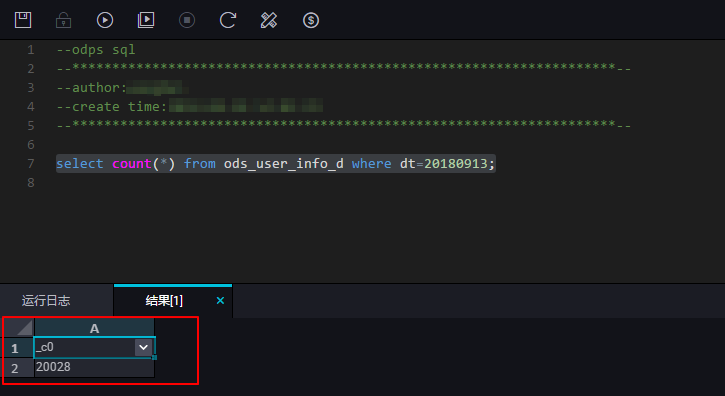 次の図に示すように、パーティション情報を照会します。
次の図に示すように、パーティション情報を照会します。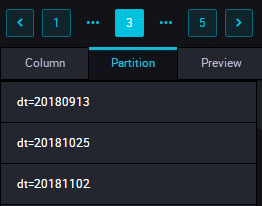 注 MaxCompute 2.0 では、パーティションテーブルクエリにパラメーター設定が必要です。 パーティション列は営業日に更新される必要があります タスク実行日が 20180717 の場合は、営業日は 20180716 です。 SQL 文は次のとおりです。
注 MaxCompute 2.0 では、パーティションテーブルクエリにパラメーター設定が必要です。 パーティション列は営業日に更新される必要があります タスク実行日が 20180717 の場合は、営業日は 20180716 です。 SQL 文は次のとおりです。--Check whether the data is successfully written to MaxCompute. select count(*)from ods_user_info_d where dt=business date;







ハッシュを使用した、日付のないフィールドでのパーティションの作成
大量のデータを処理する必要がある場合、またはすべてのデータを日付のないフィールド (都道府県など) に従って初めて分割する場合、データ移行中にデータパーティションは自動的に作成されません。 したがって、ハッシュアルゴリズムを使用して、RDS フィールドの同じ値を MaxCompute の対応するパーティションに保存します。
- すべてのデータを MaxCompute の一時テーブルに同期します。 SQL スクリプトノードを作成し、を選択します。
SQL 文は次のとおりです。
drop table if exists ods_user_t; CREATE TABLE ods_user_t ( dt STRING, uid STRING, gender STRING, age_range STRING, zodiac STRING); insert overwrite table ods_user_t select dt,uid,gender,age_range,zodiac from ods_user_info_d;--Save the data in the ODPS table to the temporary table. - 次のテーブルに示すように、mysql_to_odps という名前の同期タスクノードを作成し、パーティションを設定せず、MaxCompute にすべての RDS データを同期します。
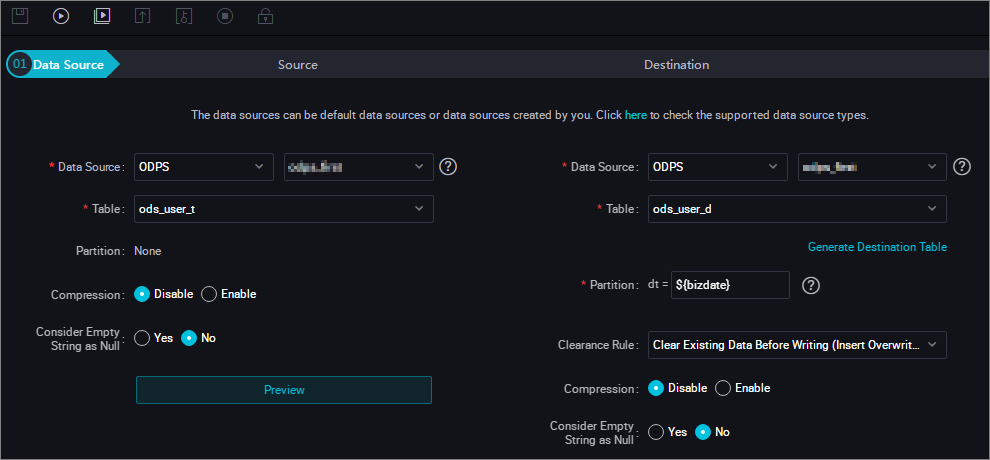
- SQL 文を使用して、宛先テーブルにパーティションを動的に作成します。 SQL 文は次のとおりです。
drop table if exists ods_user_d; --Create a partition table (the destination table) in ODPS. CREATE TABLE ods_user_d ( uid STRING, gender STRING, age_range STRING, zodiac STRING ) PARTITIONED BY ( dt STRING ); --Execute the dynamic partitioning SQL statements to automatically create a partition according to the dt field in the temporary table. The partition value is automatically created for a data record. Data records that share the same dt value have the same partition field value. --For example, some data records share the value 20180913 in the dt field. As a result, a partition is automatically created in the MaxCompute partition table with a partition value of 20181025. --The dynamic partitioning SQL statements are as follows: --A date_time field is added in the select field, indicating that a partition is automatically created according to this field. insert overwrite table ods_user_d partition(dt)select dt,uid,gender,age_range,zodiac from ods_user_t; --After the import is completed, you can delete the temporary table to reduce excessive storage costs. drop table if exists ods_user_d; - 次の図に示すように、3 つのノードを設定してワークフローを形成し、それらのノードを順番に実行します。
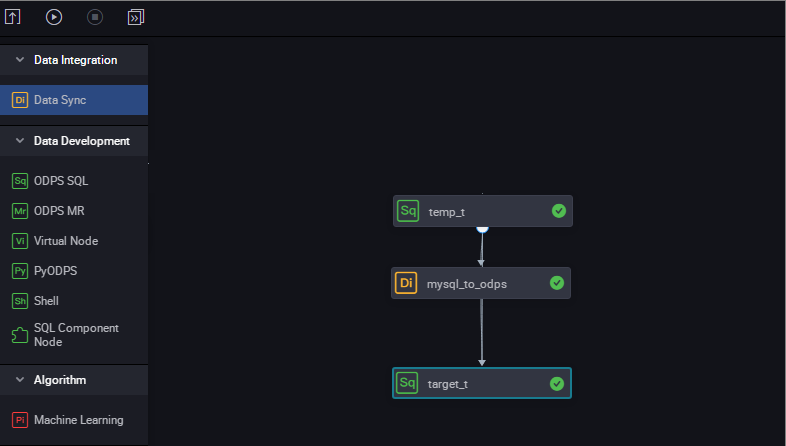
- 実行プロセスを表示します。 次の図に示すように、最後のノードでは、動的パーティションニングのプロセスが示されます。
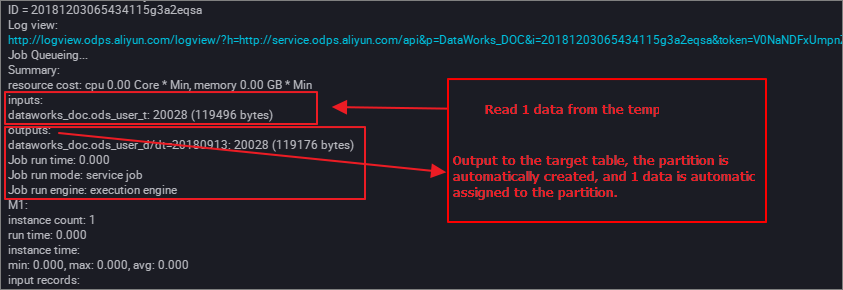 データを表示します。 動的パーティショニングは自動的に完了します。 次の図に示すように、同じ日付のデータレコードは同じパーティションに同期されます。
データを表示します。 動的パーティショニングは自動的に完了します。 次の図に示すように、同じ日付のデータレコードは同じパーティションに同期されます。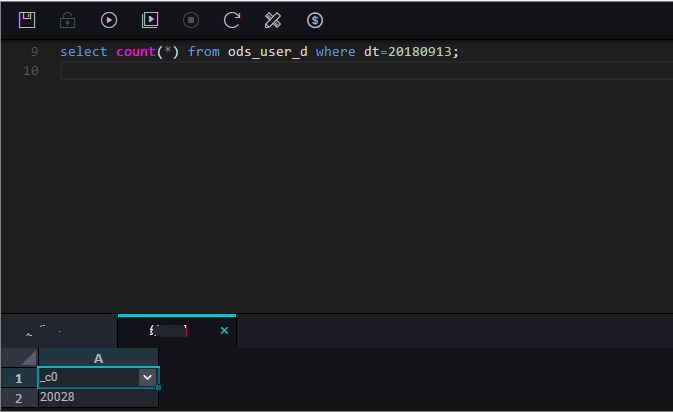 次の図に示すように、パーティション情報を照会します。
次の図に示すように、パーティション情報を照会します。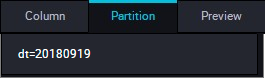
前述の手順に従って、都道府県フィールドを使用しているパーティションに名前を付けます。





DataWorks のデータ同期機能では、データ同期、データ移行、データ同期タスクスケジューリングを含む自動データ処理がサポートされます。 スケジューリング設定の詳細については、 スケジューリング設定の「時間属性」をご参照ください。