MaxCompute Lightning は MaxCompute が提供する対話型のクエリサービスです。PostgreSQL のプロトコルと構文に基づいて MaxCompute プロジェクトへ容易に接続できます。 このサービスを使用すると、標準 SQL やよく使われているツールを使用して、MaxCompute プロジェクト データを迅速にクエリおよび分析することができます。
Tablueu や FineReport などの主要 BI ツールを使用して、MaxCompute プロジェクトに簡単に接続し、BI 分析やアドホッククエリを実行できます。 MaxCompute Lightning のクイッククエリ機能を使用すると、プロジェクトテーブルデータを API にカプセル化することでサービスを提供し、データの移行なしにさまざまなアプリケーションシナリオをサポートできます。
MaxCompute Lightning は、サーバーレスコンピューティングサービスを提供します。 インフラストラクチャは必要なく、料金はクエリに対してのみ発生します。
主な機能
- PostgreSQL プロトコル互換
MaxCompute Lightning では、PostgreSQL プロトコル互換の JDBC (Java Database Connectivity) インターフェイスや、ODBC (Open Database Connectivity) インタフェイスが提供されます。 PostgreSQL データベースをベースにしたツールやアプリケーションは、デフォルトのドライバを使用して MaxCompute プロジェクトに簡単に接続できます。 簡単な接続により、MaxCompute プロジェクトデータの分析にさまざまな PostgreSQL ツールが使用できます。
- 性能の向上
MaxCompute テーブルのクイッククエリは、小規模なデータセットやクエリの同時実行性が高い場合に特に最適化されており、通常のレポートやサービス API など、さまざまなアプリケーションシナリオをサポートします。
- 統合された権限管理
MaxCompute Lightning は、MaxCompute プロジェクト用に設計されたプロダクトで、MaxCompute プロジェクトへのアクセスを提供します。 このサービスは、MaxCompute プロジェクトと同じアクセス制御システムを共有します。 これにより、ユーザーはアクセスが許可されているデータのみをクエリできます。
- すぐに使える機能と、クエリに基づく料金
MaxCompute Lightning では、既存の MaxCompute コンピューティングリソースに基づいて、サーバーレスコンピューティングサービスが提供されます。 クエリを実行するには、MaxCompute Lightning を使用して MaxCompute プロジェクトへの接続を確立するだけです。
MaxCompute Lightning のリソースを設定、管理、保守する必要はありません。 MaxCompute Lightning を使用すると、各クエリで処理されるデータ量に対してのみコストが発生します。
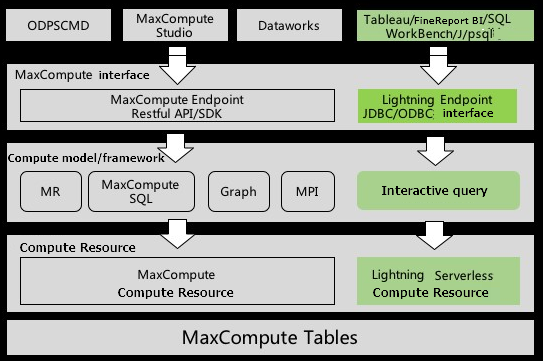
システムアーキテクチャ
MaxCompute Lightning では、PostgreSQL ドライバを使用して、エンドポイント、クライアント、またはアプリケーションを JDBC や ODBC インターフェイスに接続する方法を提供します。 これにより、MaxCompute プロジェクトの統合アクセス制御システム内で安全なデータアクセスが可能になります。
JDBC または ODBC インターフェイスで接続、送信されるクエリタスクは、MaxCompute Lightning のサーバーレスコンピューティングリソースを使用してクエリサービスの品質を保証します。
シナリオ
- アドホッククエリ
小さなデータセット (100 GB 未満) のクエリは、MaxCompute テーブルを低レイテンシで簡単にクエリできるように最適化されています。 MaxCompute データを ADS (AnalyticDB)、RDS (Relational Database Service) や、その他のシステムにインポートする必要がないため、必要なリソースと管理コストが削減されます。
このシナリオには、クエリ用の柔軟なデータオブジェクト、複雑なロジック、迅速なクエリ、クエリロジックの簡単な調整、および 1 分以内の低レイテンシクエリ要件などの特徴があります。 ユーザーは多くの場合、SQL スキルを習得し、クエリ分析に使い慣れたクライアントツールを使用したいデータアナリストです。
- レポートと分析
分析レポートは、ETL (Extract-Transform-Load) プロセスで統合された MaxCompute プロジェクトデータに基づいて生成されます。 レポートは、定期的なチェックのためマネージャーとビジネスユーザーに提供されます。
このシナリオには、クエリ対象のデータオブジェクトは通常集約されたデータである、という特長があります。 クエリ対象のデータオブジェクトは、小さいデータセットに含まれます。 クエリは、固定された簡単なクエリロジックに基づいています。 このシナリオでは低レイテンシという要件があります。 ほとんどのクエリでは、レイテンシは 5 秒以内です。 クエリのレイテンシ時間は、データ量とクエリの複雑さによって大きく異なります。
- オンラインアプリケーション
MaxCompute プロジェクトデータは、オンラインアプリケーションをサポートするために RESTful API にカプセル化できます。
このシナリオでは、MaxCompute Lightning は高速クエリエンジンとして機能し、MaxCompute テーブルデータが 手作業による介入を最小限とした API サービスとして提供されます。 これは Alibaba Cloud DataWorks のデータサービスコンポーネントを統合することによって可能になります。