分散した Kubernetes クラスターのログに関する要件は、開発者を悩ませます。 これは主に、コンテナーの特性と、ログ収集ツールの弱点によるものです。
- コンテナーの特性
- 収集対象が多い: コンテナーの特性は収集対象の数が膨大になることで、これはコンテナーログおよびコンテナー stdout を収集する必要があるためです。 現在、コンテナーから動的にログファイルを収集する良いツールはありません。 異なるデータソースごとに、異なる収集ソフトウェアがあります。 しかし、ワンストップ収集ツールは存在しません。
- オートスケーリングによる難しさ: Kubernetes クラスターは分散モードです。 サービスのオートスケーリングおよびその環境により、ログ収集が極めて困難になります。 あらかじめログ収集パスを設定することができず、これまでの仮想マシン (VM) 環境と同じことをしなくてはなりません。 動的な収集およびデータ整合性は大きなチャレンジです。
- 現在のログ収集ツールの弱点
- 動的なログ収集設定に対する容量不足: 現在のログ収集ツールは、あらかじめ手動でログ収集方法およびパスを設定する必要があります。 これらのツールは動的にログ収集を設定できません。自動的にライフサイクルの変更や動的なコンテナーの移行を検出することができないためです。
- ログの複製や消失などのログ収集の問題点: 現在のログ収集ツールのいくつかは、テールメソッドによりログを収集しています。 この方法ではログが消失することがあります。 たとえば、ログ収集ツールの再起動中にアプリケーションがログの書き込みを行います。 この間に書き込まれたログは消失することがあります。 一般的に、標準的な解決法では、デフォルトで 1 MB または 2 MB 前から現在までのログを収集します。 しかし、この方法ではログ収集の複製が発生することがあります。
- 明確なマークのないログソース: アプリケーションは同じアプリケーションログを出力する複数のコンテナーを持つことがあります。 すべてのアプリケーションログが未定義のログストレージバックエンドに収集されると、ログを照会した際、どのノードのどのコンテナーアプリケーションで生成されたログなのかを判断できません。
ここでは、Log-pilot という Docker ログの収集ツールを紹介します。これは、Elasticsearch および Kibana と一緒に使用するツールで、Kubernetes 環境におけるログ収集の問題へワンストップソリューションを提供しています。
Log-pilot の紹介
Log-pilot はインテリジェントツールで、コンテナーログの収集に使用されます。これは、コンテナーログの収集および、これらのログを複数のタイプのログストレージバックエンドへ効率的で簡便に出力するだけでなく、動的にコンテナーからログファイルの検出および収集を行います。
Log-pilot は宣言型の設定を使い、コンテナーイベントの強力に管理し、コンテナーの stdout および ファイルログを取得します。これにより、オートスケーリングに関する問題が解決されます。 加えて、Log-pilot は自動検出、チェックポイント、ハンドルのメンテナンスおよびログデータの自動トリガーの各機能をもち、これにより、動的設定、ログの複製、ログの消失およびログソースのマーキングなどの問題に効果的に対応することができます。
現在、Log-pilot は完全な GitHub オープンソースです。 プロジェクトのアドレスは 『https://github.com/AliyunContainerService/log-pilot』 です。 Log-pilot の実行原則について詳しく解説されています。
コンテナーログの宣言型設定
Log-pilot はコンテナーイベントの管理をサポートしています。これにより、コンテナーのイベント変更を動的にlistenし、コンテナーラベルによる変更を解析し、ログ収集の設定ファイルの生成が可能です。そして、ログ収集のための収集プラグインへのファイルの提供を提供します。
Kubernetes クラスターでは、Log-pilot は、環境変数 aliyun_logs_$name = $path によりログ収集の設定ファイルの生成を動的に行うことができます。 この環境変数は、以下の 2 つの値を含みます。
- 1 つ目の値は "$name" で、異なるシナリオで異なる意味を示すカスタマイズ文字列です。 このシナリオでは、"$name" は Elasticsearch へのログ収集時のインデックスを示します。
- もう 1 つは、"$path" です。これは、2 つの入力モード、コンテナー内のログファイルの stdout とパスで、それぞれログの標準出力およびコンテナー内のログファイルに対応しています。
- stdout はコンテナーからの標準出力ログの収集を示します。 この例では、Tomcat コンテナーログを収集するため、ラベル
aliyun.logs.catalina=stdoutを設定し、Tomcat の標準出力ログを収集します。 - コンテナー内のログファイルのパスはワイルドカードをサポートします。 Tomcat コンテナー内のログ収集のため、環境変数
aliyun_logs_access=/usr/local/tomcat/logs/*.logを設定します。 キーワード "aliyun" を使用しないようにするため、環境変数 "PILOT_LOG_PREFIX" を使用できます。これも、Log-pilot により提供され、お使いの宣言ログ設定のプレフィックスを指定します。 たとえば、PILOT_LOG_PREFIX: "aliyun,custom"のように使用します。
- stdout はコンテナーからの標準出力ログの収集を示します。 この例では、Tomcat コンテナーログを収集するため、ラベル
加えて、Log-pilot は複数のログ解析フォーマットをサポートしています。これには、none、JSON、CSV、Nginx、apache2 および regxp
が含まれます。 aliyun_logs_$name_format=<format> ラベルを使用して、ログ収集の際にログ解析のためにどのフォーマットを使用するか Log-pliot へ指示することができます。
Log-pilot はカスタマイズタグもサポートしています。 環境変数で、aliyun_logs_$name_tags="K1=V1,K2=V2" を設定した場合、ログ収集中に "K1=V1" および "K2=V2" がコンテナーのログ出力へ収集されます。 カスタマイズログは、簡便な統計、ルーティングおよびログのフィルタリングに関するログ生成環境へのタグ付けに有用です。
ログ収集モード
ここでは、それぞれのマシンで Log-pilot をデプロイし、マシンからの全ての Docker アプリケーションログを収集します。
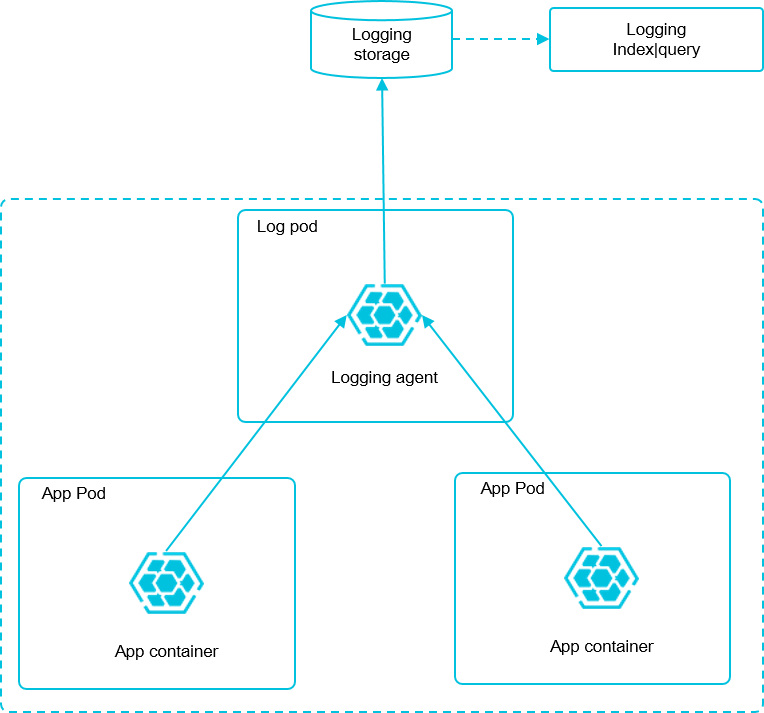
前提条件
Container Service を有効化および Kubernetes クラスターが作成されている必要があります。 このページの例では、杭州 (中国東部 1) に Kubernetes クラスターを作成します。
手順 1: Elasticsearch のデプロイ
- Kubernetes クラスターに接続します。 詳しくは、クラスターの作成またはSSH による Kubernetes クラスターへのアクセスをご参照ください。
- まず、Elasticsearch に関連するリソースオブジェクトをデプロイします。 それから、以下のオーケストレーションテンプレートを入力します。 オーケストレーションテンプレートには
elasticsearch-api サービス、elasticsearch-discovery サービスおよび Elasticsearch のステータセットが含まれます。
これらのオブジェクトの全てが名前空間 "kube-system" 上にデプロイされます。
kubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/elasticsearch.yml - デプロイの成功後、対応するオブジェクトは名前空間 "kube-system" 上にあります。 以下のコマンドを実行して、実行中のステータスを確認します。
$ kubectl get svc,StatefulSet -n=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch-api ClusterIP 172.21.5.134 <none> 9200/TCP 22h svc/elasticsearch-discovery ClusterIP 172.21.13.91 <none> 9300/TCP 22h ... NAME DESIRED CURRENT AGE statefulsets/elasticsearch 3 3 22h
手順 2: Log-pilot および Kibana サービスのデプロイ
- Log-pilot ログ収集ツールのデプロイ オーケストレーションテンプレートは以下のようになります。
kubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/log-pilot.yml - Kibana サービスのデプロイ サンプルオーケストレーションテンプレートはサービスおよびデプロイを含みます。
kubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/kibana.yml
手順 3: テストアプリケーション Tomcat のデプロイ
Elasticsearch、Log-pilot、Kibana のログツールのセットをデプロイ後、テストアプリケーション Tomcat をデプロイし、ログが正常に収集され、インデックスがつけられ、表示されるかどうかをテストします。
オーケストレーションテンプレートは以下のようになります。
apiVersion: v1
kind: Pod
metadata:
name: tomcat
namespace: default
labels:
name: tomcat
spec:
containers:
- image: tomcat
name: tomcat-test
volumeMounts:
- mountPath: /usr/local/tomcat/logs
name: accesslogs
env:
- name: aliyun_logs_catalina
value: "stdout" ## 標準出力ログの収集
- name: aliyun_logs_access
value: "/usr/local/tomcat/logs/catalina. *.log" ## コンテナー内のログファイルの収集
volumes:
- name: accesslogs
emptyDir: {}Tomcat イメージは、stdout およびファイルログの両方を使う Docker イメージです。前出のオーケストレーションにおいて、ポッドの環境変数の定義により、ログ収集設定ファイルは動的に収集されます。 以下の環境変数に関する説明をご参照ください。
aliyun_logs_catalina=stdoutはコンテナーからの stdout ログを収集することを示しています。aliyun_logs_access=/usr/local/tomcat/logs/catalina. *.logは catalina. *.log という名前に合致し、 ディレクトリ /usr/local/tomcat/logs/ にあるコンテナーからのログファイルの全てを収集します。
この解決法の Elasticsearch シナリオでは、環境変数にある $name がインデックスを示します。 この例では、$name は "catalina" および "access" です。
手順 4: Kibana サービスのインターネットへの公開
前のセクションでデプロイされた Kibana サービスは、デフォルトではインターネットからアクセスできない NodePort タイプです。 そのため、このドキュメントで Ingress を作成し、インターネットから Kibana サービスへアクセスし、ログが正常にインデックス付けされ表示されるかどうかをテストします。
- インターネットから Kibana サービスへアクセスする Ingress の作成 この例では、シンプルルーティングサービスを使って Ingress を作成します。
詳しくは、Ingress のサポートをご参照ください。 Ingress のオーケストレーションテンプレートは以下のようになります。
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kibana-ingress namespace: kube-system # 名前空間が Kibana サービスの名前空間と同一であることを確認します。 spec: rules: - http: paths: - path: / backend: serviceName: kibana #Enter the name of the Kibana service. servicePort: 80 #Enter the port exposed by the Kibana service. - Ingress が正常に作成された後、以下のコマンドを実行し、Ingress のアクセスアドレスを取得します。
$ kubectl get ingress -n=kube-system NAME HOSTS ADDRESS PORTS AGE shared-dns * 120.55.150.30 80 5m - 以下のように、ブラウザからアドレスにアクセスします。
- 左側のナビゲーションウィンドウから [管理] をクリックします。 さらに、 をクリックします。 詳細なインデックス名は、日時文字列をサフィックスとする
$name変数です。 ワイルドカード*を使ってインデックスパターンを作成できます。このページの例では、$name*を使いインデックスパターンを作成します。以下のコマンドを実行し、対応する Elasticsearch のポッドを入力し、Elasticsearch の全インデックスを表示することができます。
$ kubectl get pods -n=kube-system #Find the corresponding pod of Elasticsearch. ... $ kubectl exec -it elasticsearch-1 bash #Enter a pod of Elasticsearch. ... $ curl 'localhost:9200/_cat/indices? v' ## List all the indexes. health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .kibana x06jj19PS4Cim6Ajo51PWg 1 1 4 0 53.6kb 26.8kb green open access-2018.03.19 txd3tG-NR6-guqmMEKKzEw 5 1 143 0 823.5kb 411.7kb green open catalina-2018.03.19 ZgtWd16FQ7qqJNNWXxFPcQ 5 1 143 0 915.5kb 457.5kb - インデックスが正常に作成された後、左側のナビゲーションウィンドウから [検出] をクリックし、作成されたインデックスおよび対応する時間範囲を選択し、検索ボックスに関連するフィールドを入力しログを照会します。
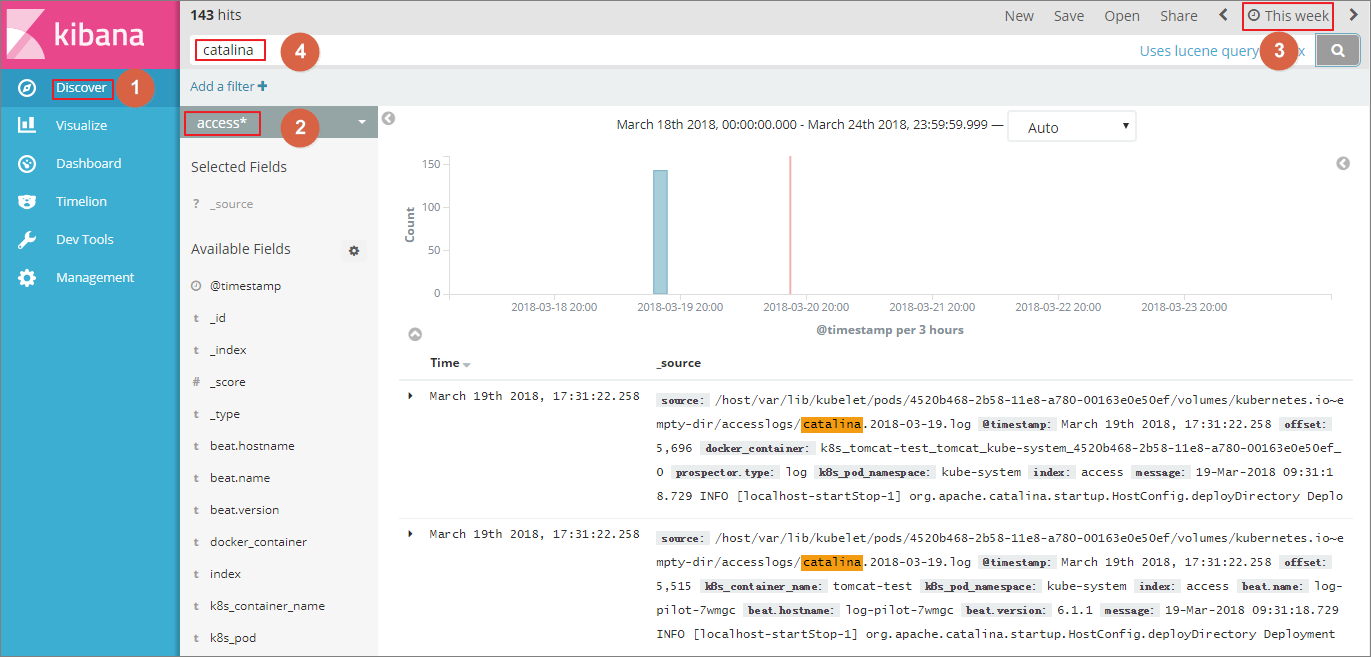


これで、Log-pilot、Elasticsearch および Kibana を基にした Alibaba Cloud Kubernetes クラスターのログ収集の問題解決法のテストが正常に行われました。 この解決法を利用することで、分散 Kubernetes クラスターのログに関する要件を効果的に扱うことができ、運用と管理、および操作効率が向上し、システムの一貫性および安定した実行が保証されます。