Server Load Balancer は、ヘルスチェックを実行して、バックエンドサーバー (ECS インスタンス) のサービス可用性をチェックします。 ヘルスチェックは、フロントエンドサービスの全体的な可用性を向上させ、バックエンド ECS インスタンスの例外がサービス全体に影響を及ぼさないようにします。
ヘルスチェック機能を有効にすると、SLB は、異常と検出されたインスタンスへのリクエストの配信を停止し、正常であると確認された場合にのみインスタンスへのリクエストの転送を再開します。
トラフィック負荷の影響を受けやすい業務の場合、頻繁なヘルスチェックにより、正常なサービスに影響を与える可能性があります。 ヘルスチェックの頻度を減らす、ヘルスチェックの間隔を長くする、HTTP ヘルスチェックを TCP ヘルスチェックに変更するなどで、この影響を軽減することができます。 サービスの可用性を保証するため、すべてのヘルスチェックを無効にすることは推奨しません。
ヘルスチェックのプロセス
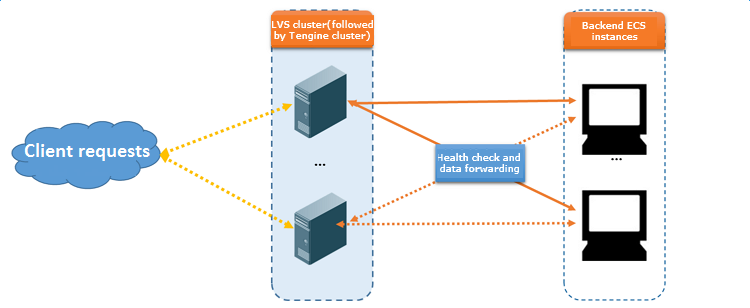
Server Load Balancer はクラスターにデプロイされています。 データ転送とヘルスチェックは、LVS クラスターと Tengine クラスターのノードサーバーで同時に処理されます。
クラスター内のノードサーバーは、ヘルスチェック設定に従い、独立してヘルスチェックを並列に実行します。 ノードサーバーは ECS インスタンスの異常を検出すると、ECS インスタンスへのリクエストの配信を停止します。 この動作は、すべてのノードサーバーで同期されます。
ヘルスチェックを実行するために使用される IP アドレスの範囲は、100.64.0.0/10 です。 バックエンドサーバーは、この CIDR ブロックをブロックすることができません。 この CIDR ブロックからのアクセスを許可するセキュリティグループルールを、追加で設定する必要はありません。 ただし、iptables などのセキュリティルールを設定している場合は、この CIDR ブロックからのアクセスを許可する必要があります (100.64.0.0/10 は Alibaba Cloud で予約されており、他のユーザーはこの CIDR ブロックの IP アドレスを使用できないため、 セキュリティ上のリスクはありません)。
HTTP/HTTPS リスナーにおけるヘルスチェック
レイヤー 7 (HTTP または HTTPS) リスナーの場合、SLB は、次の図に示すように、HTTP HEAD リクエストを送信することにより、バックエンドサーバーのステータスを検出します。
HTTPS リスナーの場合、証明書は SLB で管理されます。 SLB とバックエンド ECS インスタンス間のデータ交換 (ヘルスチェックデータとサービス連携データを含む) は、システムのパフォーマンス向上のために、HTTPS を介して送信されません。

レイヤー 7 リスナーのヘルスチェックプロセスは、次のとおりです。
- Tengine ノードサーバーは、ヘルスチェック設定に従って、ECS インスタンスの イントラネット IP + 【ヘルスチェックポート】 + 【ヘルスチェックパス】に HTTP HEAD リクエストを送信します。
- リクエストを受信後、バックエンドサーバーは、実行ステータスに基づいて HTTP ステータスコードを返します。
- Tengine ノードサーバーが、指定した【レスポンスタイムアウト】時間内にバックエンド ECS インスタンスからのレスポンスを受信しなかった場合、ECS インスタンスは異常とみなされます。
- Tengine ノードサーバーが、指定した【レスポンスタイムアウト】時間内にバックエンド ECS インスタンスからのレスポンスを受信した場合、返されたステータスコードが、リスナー設定で指定されたステータスコードと比較されます。 ステータスコードが同一の場合、バックエンドサーバーは正常とみなされます。 そうでない場合、バックエンドサーバーは異常とみなされます。
TCP リスナーにおけるヘルスチェック
TCP リスナーの場合、SLB は、次の図に示すように、TCP 検出を送信し、バックエンドサーバーのステータスを検出します。
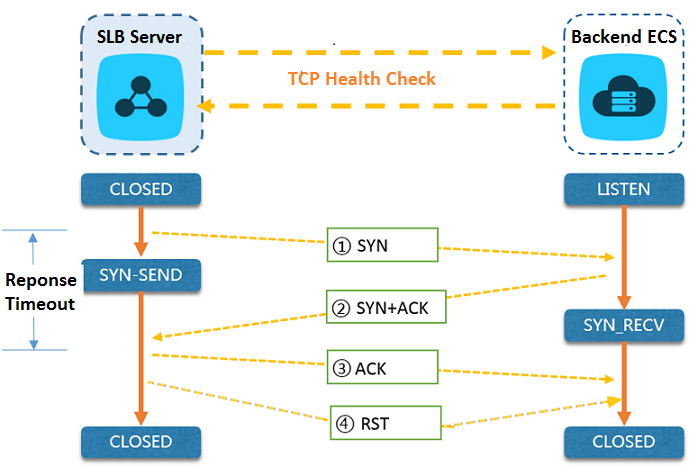
TCP リスナーのヘルスチェックプロセスは次のとおりです。
- LVS ノードサーバーは、バックエンド ECS インスタンスのイントラネット IP + 【ヘルスチェックポート】に TCP SYN パケットを送信します。
- リクエストを受信後、対応するポートが正常にリスニングしていた場合、バックエンドサーバーは TCP SYN と ACK パケットを返します。
- LVS ノードサーバーが、指定した【レスポンスタイムアウト】時間内にバックエンドサーバーから必要なデータパケットを受信しなかった場合、ECS インスタンスは異常とみなされます。 この場合、LVS ノードサーバーは、RST パケットをバックエンドサーバーに送信して、TCP 接続を終了します。
- LVS ノードサーバーが、指定した【レスポンスタイムアウト】時間内にバックエンド ECS インスタンスからデータパケットを受信した場合、ECS インスタンスは正常とみなされます。 この場合、LVS ノードサーバーは、RST パケットをバックエンドサーバーに送信して、TCP 接続を終了します。
このプロセスにより、バックエンドサーバーは TCP 接続でエラー (異常終了など) が発生したとみなして、Connection reset by peer などの対応するエラーメッセージを送信することがあります。
解決策:
- HTTP ヘルスチェックを使用します。
- 物理 IP の取得を有効にした場合は、SLB の IP アドレスのアクセスによって発生した接続エラーは無視してください。
UDP リスナーにおけるヘルスチェック
UDP リスナーの場合、SLB は、次の図に示すように、UDP パケット検出を通してバックエンドサーバーのステータスを検出します。
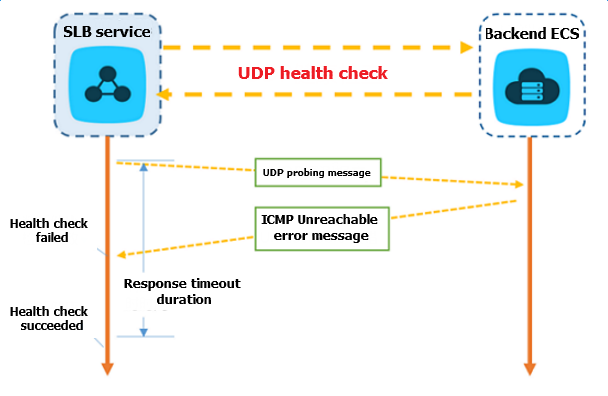
UDP リスナーにおけるヘルスチェックのプロセスは次のとおりです。
- LVS ノードサーバーは、ヘルスチェック設定に従って、ECS インスタンスの イントラネット IP +【ヘルスチェックポート】に UDP パケットを送信します。
- ECS インスタンスの対応するポートが正常にリスニングしていない場合、
port XX unreachableなどの ICMP エラーメッセージが返されます。 そうでない場合は、メッセージは送信されません。 - LVS ノードサーバーが、指定した【レスポンスタイムアウト】時間内に ICMP エラーメッセージを受信した場合、ECS インスタンスは異常とみなされます。
- LVS ノードサーバーが、指定した【レスポンスタイムアウト】時間内にメッセージを受信しなかった場合、ECS インスタンスは正常とみなされます。
ECS インスタンスが Linux オペレーティングシステムを使用する場合、Linux での ICMP 攻撃防御のため、並行性の高いシナリオで ICMP メッセージを送信する速度が制限されます。
この場合、たとえ ECS インスタンスで例外が発生したとしても、エラーメッセージ port XX unreachable が返されないため、SLB はバックエンドサーバーが正常とみなすことがあります。 その結果、実際のサービス状況はヘルスチェックの結果と一致しなくなります。
解決策:
UDP ヘルスチェックのカスタムリクエスト/レスポンスのセットを設定します。 カスタムレスポンスが返された場合、ECS インスタンスは正常とみなされます。 そうでない場合は、ECS インスタンスは異常とみなされます。 これを実現するには、クライアントに対応する設定情報を追加する必要があります。
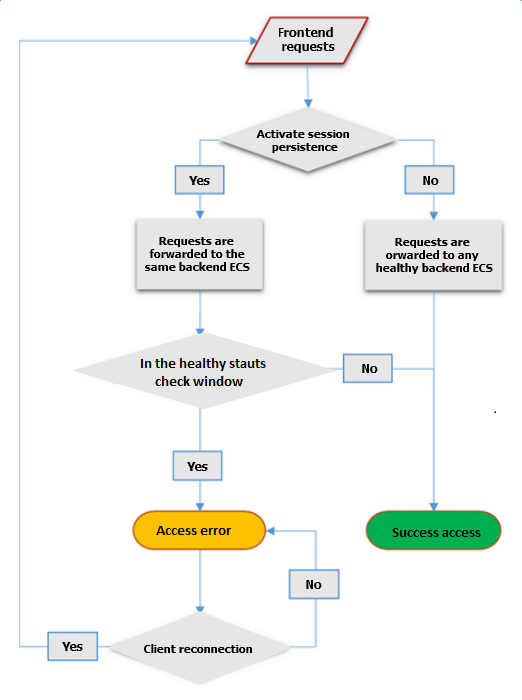
ヘルスチェックタイムウィンドウ
ヘルスチェック機能により、ビジネスサービスの可用性は効果的に向上しました。 ただし、ヘルスチェックの失敗のために、システムの切り替えが頻繁に引き起こされ、それによって引き起こされるシステムの可用性に対する影響を軽減するため、SLB は指定した期間内に成功または失敗が連続した後でのみ、ECS インスタンスが正常または異常であることを報告します。 ヘルスチェックタイムウィンドウは、次の 3 つの要件により決まります。
- ヘルスチェックの間隔 (ヘルスチェックを実行する頻度)
- レスポンスタイムアウト時間 (レスポンスを待つ時間)
- ヘルスチェックのしきい値 (連続成功/連続失敗したヘルスチェックの回数)。
ヘルスチェックタイムウィンドウの計算方法は、次のようになります。
- ヘルスチェック失敗タイムウィンドウ = レスポンスタイムアウト × 異常しきい値 + ヘルスチェック間隔 × (異常しきい値)-1)
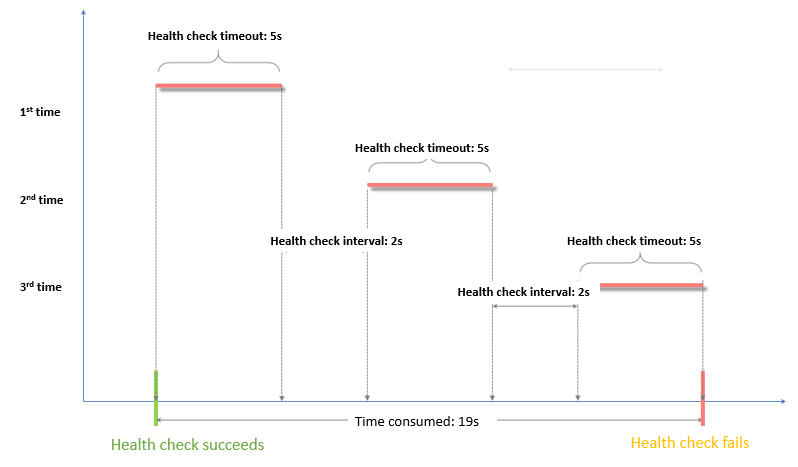
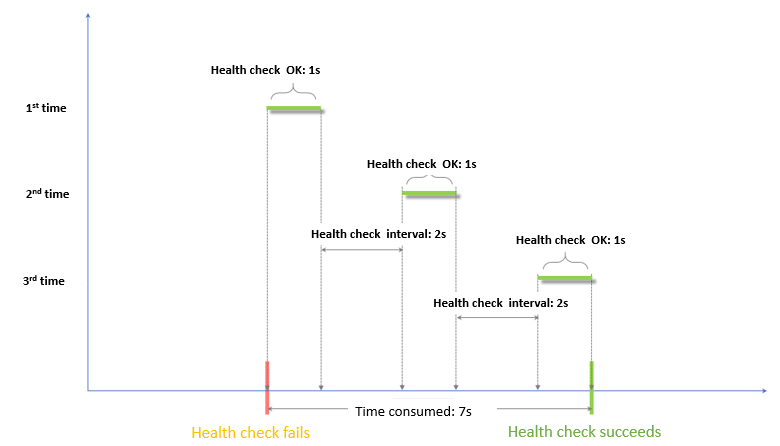
- ヘルスチェック成功タイムウィンドウ = (正常ヘルスチェックのレスポンス時間 x ヘルスチェックしきい値) + ヘルスチェック間隔 x (ヘルスチェックしきい値 -1)
注 ヘルスチェックの成功レスポンス時間は、ヘルスチェックリクエストが送信されてからレスポンスが受信されるまでの時間です。 TCP ヘルスチェックの場合、ポートが生きているか否かを検出するだけなので、非常に短い時間です。 HTTP ヘルスチェックの場合、時間はアプリケーションサーバーのパフォーマンスと負荷によって異なりますが、通常は数秒以内です。


ヘルスチェックの結果は、リクエスト転送に対して次のような影響を及ぼします。
- 対象 ECS インスタンスのヘルスチェックが失敗した場合、新規リクエストはその ECS インスタンスに配信されません。 したがって、クライアントアクセスには影響を与えません。
- 対象 ECS インスタンスのヘルスチェックが成功した場合、新規リクエストは ECS インスタンスに配信されます。 クライアントアクセスは正常です。
- ヘルスチェック失敗タイムウィンドウの最中にリクエストが到達した場合、ECS インスタンスはチェック中で、まだ異常が検出されていないため、そのリクエストは今までどおりに ECS インスタンスへ送信されます。 その結果、クライアントアクセスは失敗します。