背景
従来の Hadoop の使用では、ストレージとコンピューティングは切り離すことができません。 そのため、ビジネスが成長するにつれて、クラスターサイズがビジネスの拡張に対するニーズを満たせなくなることがよくあります。 たとえば、データの規模がクラスターのストレージ容量を超えると、ビジネスのデータ生産サイクルから生じる新しい要件が、コンピューティング性能の限界を上回る可能性があります。 この場合、不十分なクラスターストレージスペース、コンピューティング性能の問題に対処するよう常に備えている必要があります。
コンピューティングとストレージをハイブリッド方式でデプロイすることを選んだ場合、ストレージの拡張は大抵、過剰なコンピューティング性能につながる可能性があります。 これは資源の浪費につながります。 同様に、コンピューティング性能の向上は記憶資源の浪費を引き起こします。
オフラインコンピューティングのため、コンピューティングとストレージを分離することで、不十分なコンピューティングまたはストレージリソースに対処することがより容易になります。 このソリューションでは、すべてのデータを OSS に保存し、ステートレスの E-MapReduce を使用してデータを分析することができます。 そのため、E-MapReduce は計算のみ担い、ストレージリソースはビジネスにおけるコンピューティングリソースに結び付けられません。 このアプローチは最高の柔軟性を提供します。
アーキテクチャ
次の図に示すように、ストレージとコンピューティングを分離したオフラインコンピューティングのアーキテクチャはシンプルです。 OSS は既定のストレージユニットとして機能し、Hadoop または Spark は OSS に保存されているデータを直接分析するコンピューティングエンジンとして機能します。

利点
| 要素 | 統合コンピューティングとストレージ | コンピューティングとストレージの分離 |
| 柔軟性 | 柔軟さに欠ける | コンピューティングとストレージが分離されると、クラスタールールはシンプルかつ柔軟になります。 必要なリソースを使用する以外に、将来の事業規模を見積もる必要はほとんどありません。 |
| コスト | 高い | Ultra クラウドディスクは、自己構築の ECS システムで使用されます。 ストレージとコンピューティングを分離させると、クラスター構成が 8 コア 32 GB CPU を持つ 1 つのマスターノードで、8 コア 32 GB CPU を持つ 6 つのスレーブノード、および 10 TB のデータである場合、コストは約半分になります。 |
| パフォーマンス | 比較的高い | 最大でパフォーマンスは 10 % 低下します。 |
テスト ケース
- テスト条件
詳細なテストコードについては『GitHub』をご参照ください。
クラスター規模: 4 コアの 16 GB CPU を搭載した 1 つのマスターノード、4 コアの 16 GB CPU を搭載した 8 つのスレーブノード、各スレーブノードに 4 つの 250 GB の Ultra クラウドディスクがあります。
Spark テストスクリプトについては、以下の通りです。
/opt/apps/spark-1.6.1-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode cluster --executor-memory 3G --num-executors 30 --conf spark.default.parallelism=800 --class com.github.ehiggs.spark.terasort.TeraSort spark-terasort-1.0-jar-with-dependencies.jar /data/teragen_100g /data/terasort_out_100g - テスト結果
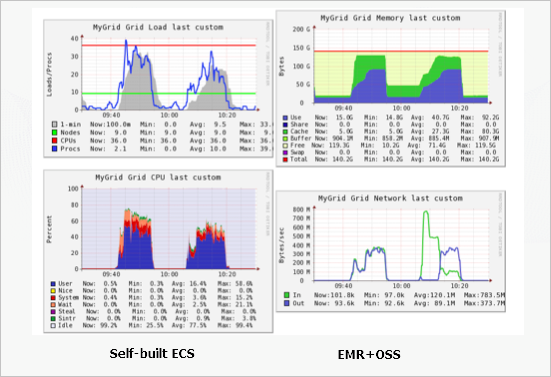
- パフォーマンス
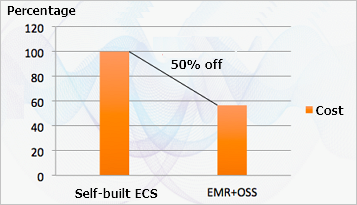
- コスト
- 時間

- パフォーマンス
- 結果分析
パフォーマンスチャートから、EMR + OSSと自己構築 Hadoop と ECS システムのそれぞれの利点を比較します。
-
全体の負荷は比較的低い
-
メモリ使用率は基本的に同一
-
CPU 使用率は低くなります。その場合、iowait と sys の使用率レベルははるかに低くなります。 自己構築の ECS システムのデータノードとディスク操作はリソースを占有するため、CPU のオーバーヘッドを増大させます。
-
ネットワーク使用量に関しては、sortbenchmark は 2 つのデータ読み取り操作 (サンプリング用と実際のデータ読み取り用) を実行するため、ネットワーク使用率は最初から高く、シャッフル + 結果出力ステージでは、ECS システムを備えた自己構築 Hadoop に比べ約半分に低下します。 そのため、ネットワークの観点からは、全体的な使用率は基本的に横ばいです。
つまり、EMR + OSS では、コストは半分になりますが、パフォーマンスの低下はごくわずかです。 さらに、EMR + OSS ソリューションの同時実行性の向上は、ECS システムを備えた自己構築 Hadoop と比較して、より高い時間的優位性を意味します。
-
EMR + OSS の使用が向かないシナリオ
以下のシナリオでは、EMR + OSS を使用しないことを推奨します。
-
多数の小さなファイルがあるシナリオ
この場合、10 MB より小さいファイルをマージしてください。 EMR + OSS ソリューションは、データ量が 128 MB を超える場合に最高のパフォーマンスを発揮します。
-
頻繁な OSS メタデータ操作を伴うシナリオ