クラウドサービスの最大の利点は、リソースを予約する必要がない、従量課金方法です。 したがって、すべてのクラウド製品には、測定と請求の需要があります。 本ページでは、『Log Service』に基づいて開発され、多くのクラウド製品で使用される測定および請求ソリューションについて説明します。 このソリューションを使用して、毎日数千億もの計測ログを処理することができます。
計測ログからの請求書の生成
計測ログは、請求項目を記録します。 バックエンドの請求モジュールは、請求項目とルールに基づいて費用を計算し、最終的な請求書を生成します。 たとえば、次の生アクセスログはプロジェクトの使用状況を記録します。
microtime:1457517269818107 Method:PostLogStoreLogs Status:200 Source:10.145.6.81 ClientIP:112.124.143.241 Latency:1968 InFlow:1409 NetFlow:474 OutFlow:0 UserId:44 AliUid:1264425845****** ProjectName:app-myapplication ProjectId:573 LogStore:perf UserAgent:ali-sls-logtail APIVersion:0.5.0 RequestId:56DFF2D58B3D939D691323C7
計測および請求プログラムは、生ログを読み取り、関連するルールに基づいてさまざまなディメンションから使用データを生成します。 次の図は、受信トラフィック、使用回数、送信トラフィックなど、生成された使用データを示しています。
計測ログを使用した請求の一般的なシナリオ
- 電力会社は 10 秒ごとにログを受け取ります。 ログには、10 秒以内の各ユーザー ID の消費電力、ピーク消費電力、および平均消費電力が記録されます。 このようなログに基づいて、会社は時間単位、日単位、または月単位でユーザーの請求書を生成します。
- 通信事業者は、10 秒ごとに基地局からログを受信します。 ログには、インターネットアクセス、音声通話、SMS メッセージ、Voice over Internet Protocol (VoIP) 通話など、携帯電話番号が 10 秒以内に使用したサービスが記録されます。 ログには、各サービスのデータ使用量または期間も記録されます。 このログに基づいて、バックエンド請求サービスは、この期間中に発生した費用を計算します。
- 天気予報 API サービスは、リクエストされた API 操作のタイプ、都市、クエリタイプ、およびクエリ結果のサイズに基づいて、ユーザーリクエストに請求します。
要件と課題
計測および請求ソリューションは、次の基本要件を満たしている必要があります。
- 精度と信頼性: 計算結果は正確でなければなりません。
- 柔軟性: データを補足することができます。 たとえば、一部のデータが時間内にプッシュされない場合は、データを補足および修正して費用を再計算することができます。
- 適時性: サービスは数秒で請求することができます。 アカウントに滞納がある場合は、サービスは直ちに停止されます。
その他の要件:
- 請求書の修正: リアルタイムの請求が失敗した場合は、請求書は計測ログから生成することができます。
- 詳細クエリ: ユーザーは消費の詳細を表示することができます。
実際の 2 つの課題:
- データサイズの増加: データサイズは、ユーザー数と通話数の増加に伴って増加し続けます。 1 つの課題は、アーキテクチャの自動スケーリングを維持することです。
- フォールトトレランス: 請求プログラムにバグがある可能性があります。 もう 1 つの課題は、請求データから測定データを独立させることです。
本ページで説明する計測および請求ソリューションは、Log Service に基づいて Alibaba Cloud によって開発されました。 このソリューションは、何年もの間オンラインで安定しており、エラーや遅延は生じていません。
システムアーキテクチャ
計測および請求ソリューションのシステムアーキテクチャでは、Alibaba Cloud Log Service の LogHub は次のように機能します。
- 計測ログをリアルタイムで収集し、計測ログを計測プログラムに書き込みます。 LogHub は、30 以上の API 操作とアクセスメソッドをサポートしており、測定ログの収集と書き込みに役立ちます。
- 測定プログラムが一定の間隔でステップサイズの LogHub データを使用し、メモリ内の費用を計算して請求データを生成できるようにします。
- 詳細クエリの要件を満たすために、ログを測定するためのインデックスを作成します。
- オフラインストレージ用に、計測ログを Object Storage Service (OSS) にプッシュします。 アカウントをチェックし、T + 1ベースでデータの統計を取ることができます。
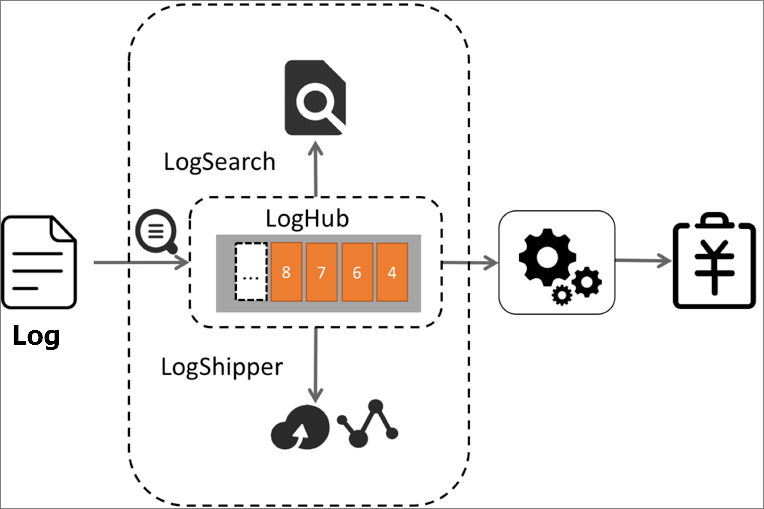
リアルタイム測定プログラムの内部ロジックは次のとおりです。
- GetCursor 操作を呼び出して、LogHub から指定された期間 (10:00 ~ 11:00 など) のログのカーソルを取得します。
- この期間のデータを消費するために、PullLogs 操作を呼び出します。
- データの統計を取り、メモリ内のデータを計算し、結果を取得して、請求データを生成します。
同様に、指定する期間は 1 分または 10 秒にすることができます。
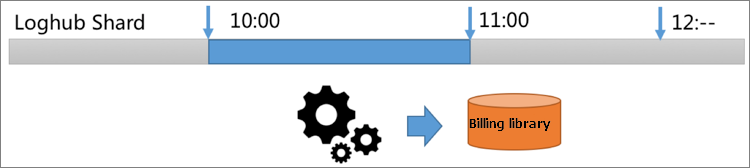
計測および請求ソリューションのパフォーマンスは、次のように分析されます。
- 毎日 10 億の計測ログが生成され、それぞれが 200 バイトであると想定します。 合計データサイズは 200 GB です。
- LogHub では、SDK またはエージェントはデフォルトでデータを圧縮することができます。 したがって、保存されたデータのサイズは、圧縮後 40 GB で、最大で元のサイズの 1/5 となります。 1 時間に生成されるデータのサイズは、40/24 = 1.6 GB と計算されます。
- LogHub では、毎回最大 1,000 個のロググループを読み取ることができます。 各ロググループの最大サイズは 5 MB です。 GE ネットワークでは、1 時間で生成されたすべてのデータを 2 秒以内に読み取ることができます。
- 測定プログラムがデータの統計を取り、メモリ内のデータを計算した後、1 時間で生成された計測ログは 5 秒以内に消費されます。
大きなデータサイズに対する解決策
通信事業者と Internet of Things (IoT) の一部の請求シナリオでは、たとえば、1 日あたり 2 PB のデータサイズの 10 兆のログなど、多数の計測ログが生成されます。 圧縮後、1 時間で生成されるデータのサイズは 16 TB です。 10 GE ネットワークでは、1 時間で生成されたすべてのデータを読み取るのに 1,600 秒かかります。これは、迅速な請求要件を満たすことができません。
1. 生成される請求データのサイズの制御
Nginx などの計測ログを生成するプログラムを変更して、最初にメモリ内の計測ログを集計し、集計された計測ログを 1 分ごとにダンプします。 このようにして、データサイズはユーザーの総数に関連付けられます。 Nginx が 1 分あたり 1,000 ユーザーのデータを処理すると想定します。 1 時間に生成される計測ログのサイズは、1,000 x 200 x 60 = 12 GB と計算されます。 圧縮後のデータサイズはわずか 240 MB です。
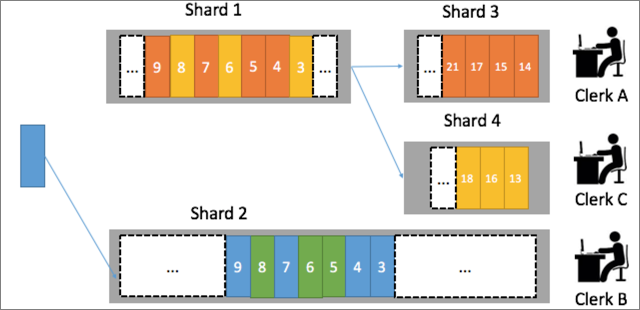
2. 計測ログ処理の並列化
LogHub では、各ログストア が複数のシャードを含むことができます。 たとえば、ログストアには 3 つのシャードが含まれ、3 つの測定プログラムが利用可能です。 ユーザーの測定データが常に同じ測定プログラムによって処理されるようにするには、ハッシュ関数を使用して、ユーザーをユーザー ID によってシャードにマップします。 同じユーザーの計測データを固定シャードに割り当てることができます。 たとえば、杭州の西湖地区のユーザーの測定データはシャード 1 に書き込まれ、杭州の上城地区のユーザーの測定データはシャード 2 に書き込まれます。 この場合、バックエンド測定プログラムは、2 つのシャードの測定データを並行して処理することができます。
よくある質問
- データを補足するにはどうすればよいですか。
LogHub では、各ログストアのライフサイクルを 1 ~ 365 日の範囲で設定することができます。 請求プログラムがデータを再度消費する必要がある場合は、ログストアのライフサイクルの期間ごとにデータを計算することができます。
- 計測ログが多くのフロントエンドサーバーに散在している場合はどうすればよいですか。
- Logtail エージェントを使用して、各サーバーからリアルタイムでログを収集します。
- サーバーのマシン ID を使用して、自動スケーリングの動的マシングループを定義します。
- 詳細をクエリするにはどうすればよいですか。
LogHub データのインデックスを作成して、リアルタイムのクエリと統計分析をサポートすることができます。 たとえば、データサイズが大きい測定ログをクエリする場合は、次のクエリステートメントを使用することができます。
Inflow>300000 and Method=Post* and Status in [200 300]LogHub データのインデックス作成機能を有効にした後、リアルタイムでデータをクエリおよび分析することができます。
次のように、クエリステートメントの最後に統計分析ステートメントを追加することもできます。
Inflow>300000 and Method=Post* and Status in [200 300] | select max(Inflow) as s, ProjectName group by ProjectName order by s desc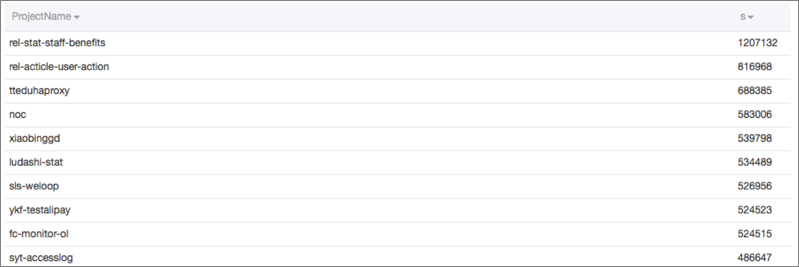
- T + 1 ベースでログを保存してアカウントを確認するにはどうすればよいですか。
Log Service は、LogHub データを他のシステムに送信することができます。 シャードとストレージフォーマットをカスタマイズして、OSS にログを保存することができます。 E-MapReduce 、HybridDB、Hadoop、Hive、Presto、および Spark を使用してログデータを計算します。
