MaxCompute Java モジュールを作成すると、UDF を開発することができます。
手順
- 作成した MaxCompute Java モジュールディレクトリを展開し、次の図に示すように、 の順に移動し、 [MaxCompute Java] をクリックします。
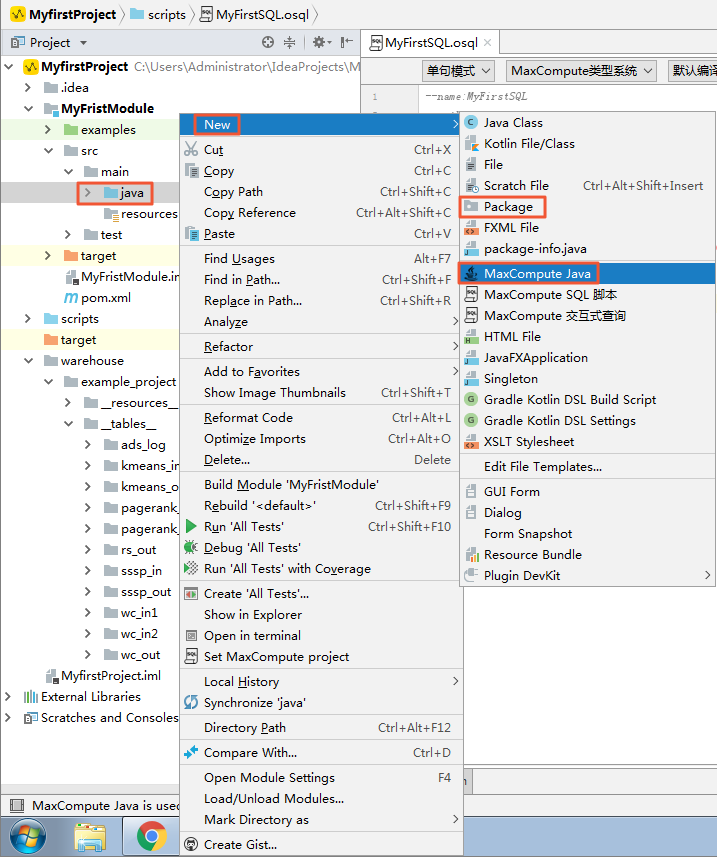
- 次の図に示すように、[Name] と [Kind] を設定して [OK] をクリックします。
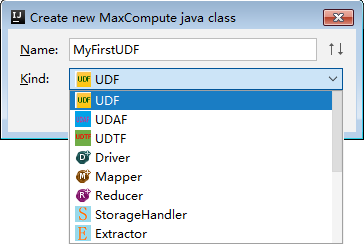
- Name: MaxCompute Java クラスの名前を指定します。 パッケージを作成していない場合は、"packagename.classname" と入力してパッケージを自動的に作成します。
- Kind: 種類を指定します。 サポートされている種類には、カスタマイズ関数 (UDF、UDAF、UDTF) 、MapReduce (Driver、Mapper、Reducer) 、および非構造開発 (StorageHandler、Extractor) が含まれます。
- 作成が成功すると、Java プログラムの開発、変更、およびテストが可能です。
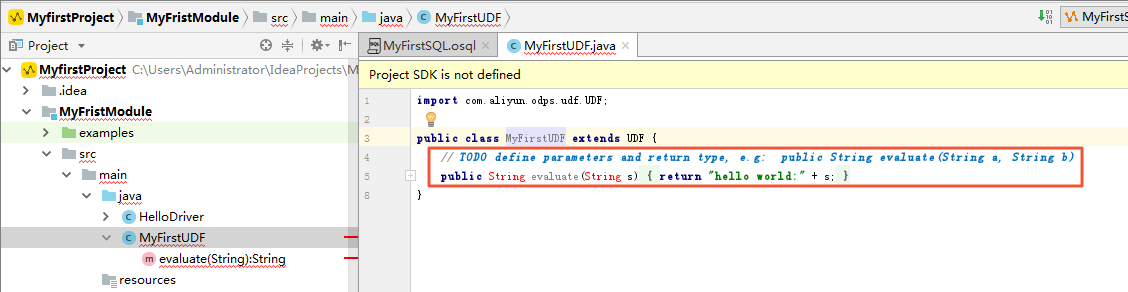 注 これは Intellij でカスタマイズ可能なコードテンプレートです。 でそれを定義します。 [Code] タブで、対応するテンプレートを探します。
注 これは Intellij でカスタマイズ可能なコードテンプレートです。 でそれを定義します。 [Code] タブで、対応するテンプレートを探します。



詳細な開発手順については、「 JAVA UDF の開発」をご参照ください。
通常、JAVA UDF の開発は次の方法で行います。
- MaxCompute Studio を使用して JAVA UDF 開発の全プロセスを完了します。
- Eclipse プラグインを使用した JAVA UDF の開発およびデバッグを使用し、jar パッケージをエクスポートして、コマンドまたは DataWorks によって リソースを追加し、関数を登録します。
詳細な開発手順については「 JAVA UDF の開発」をご参照ください。
UDF プログラムのデバッグ
UDFプログラムを開発した後、単体テスト (UT) またはローカル実行を使用してそれをテストし、想定どおりか確認します。
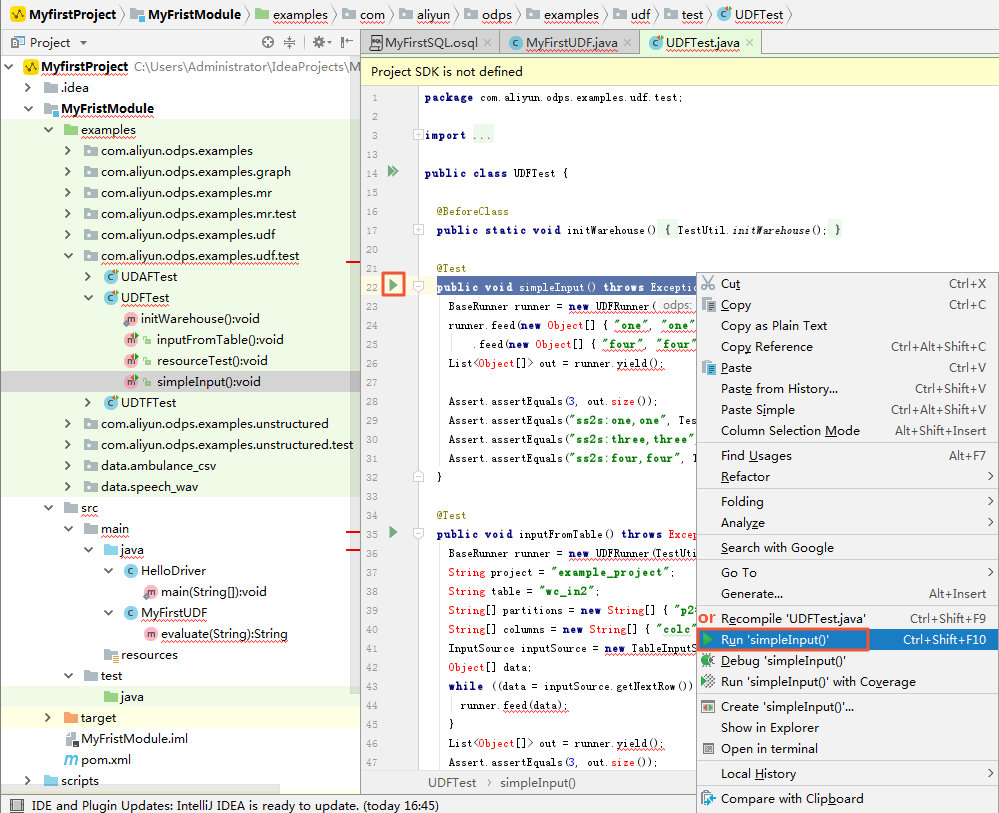
単体テスト"examples" ディレクトリにはさまざまな UT の例があり、それらを参照して UT をコンパイルします。
ローカル実行
UDF プログラムのローカル実行中に、実行中のデータソースを指定する必要があります。 テストデータソースを設定するには、次の 2 つの方法があります。
- MaxCompute Studio は、トンネルサービスを使用して、特定のプロジェクトのテーブルデータを "warehouse" ディレクトリに自動的にダウンロードします。
- モックプロジェクトとテーブルデータが提供されます。 "warehouse" 内の "example_project" を参照し、自身でそれを設定します。
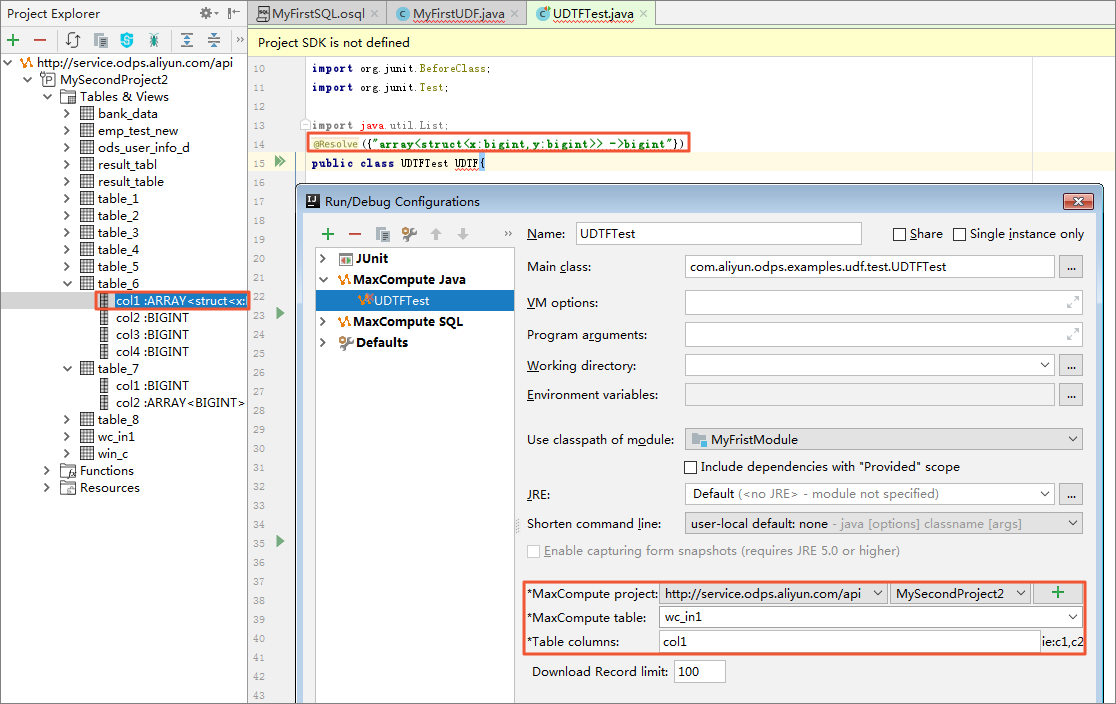
- [UDF Class] を右クリックし、[Run UDF class.main()] をクリックします。 [Run Configuration] ダイアログボックスが表示されます。 通常、UDF、UDAF、UDTF データは、SELECT サブ文のテーブルの列として使用されます。
MaxCompute プロジェクト、テーブル、および列を設定する必要があります (メタデータは、"project explorer" と "warehouse" 配下のモックプロジェクトに由来します)
。 次の図に示すように、複合型のデバッグもサポートされています。
-
[OK] をクリックします。
 注
注- 指定されたプロジェクト配下のテーブルデータが "glashourse" にダウンロードされていない場合は、まずデータをダウンロードする必要があります。デフォルトでは、100 エントリーをダウンロードします。 さらにデータが必要な場合は、コンソールのトンネルコマンドまたは Studio のテーブルダウンロード機能を使用します。
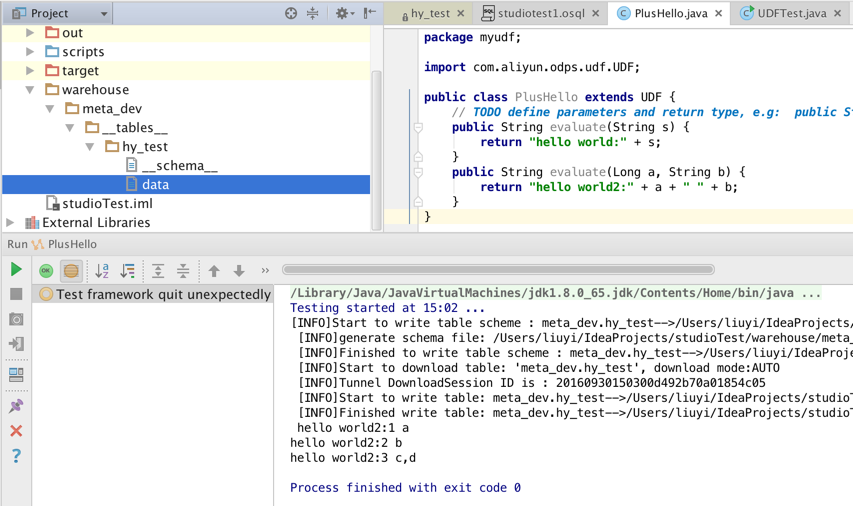
- モックプロジェクトを使用する、またはテーブルデータをダウンロードする場合は、プログラムを直接実行します。
- UDF ローカル実行フレームワークは、"warehouse" 内の特定の列のデータを UDF 入力として使用し、 UDF プログラムをローカルに実行します。 ログ出力と結果画面がコンソールに表示されます。


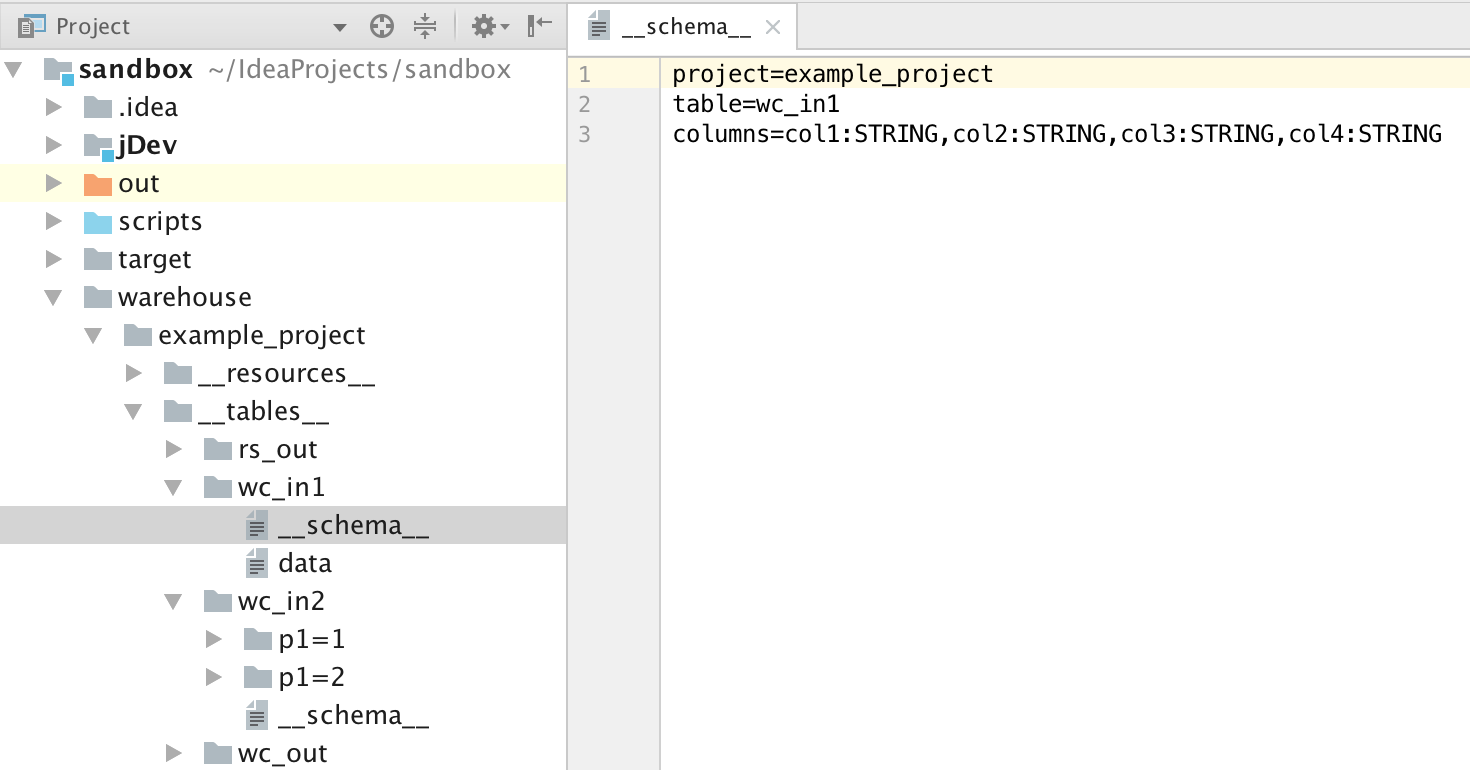
ローカル "warehouse" ディレクトリは、ローカル UDF または MR 実行用のテーブル (メタおよびデータを含む) またはリソースを格納するために使用されます。 次の図は、"warehouse" ディレクトリを示しています。
注
- プロジェクト名、テーブル、テーブル名、テーブルスキーム、およびサンプルデータが、順に "warehouse" ディレクトリ配下にあります。
- スキーマファイルは、(コロンで区切って) プロジェクト名、テーブル名、列名および型の順に設定されています。 パーティションテーブルの場合は、パーティション列も設定する必要があります。 (非パーティションテーブルについては、wc_in1 を参照します。 パーティションテーブルについては、wc_in2 を参照します) 。
- データファイルは、標準の CSV 形式を使用して、テーブルのサンプルデータを格納します。
- 特殊文字には、コンマ、二重引用符、および改行 (\n または \r\n) が含まれます。
- 列区切り文字はコンマ、行区切り文字は \n または \r\n です。
- 列の内容に特殊文字が含まれる場合は、列の内容の前後に二重引用符 (") を追加する必要があります。 たとえば、列の内容が 3,No ならば、“3, No” に変更されます。
- 列の内容に二重引用符が含まれる場合は、二重引用符はそれぞれ 2 つの二重引用符に変換されます。 たとえば、列の内容が a”b”c なら、“a””b””c” に変更されます。
- \N は、列が Null 値であることを示します。 列の内容 (文字列型) が \N の場合は、 """\N"""に変換する必要があります。
- ファイルの文字コードは UTF-8 です。