ここでは、オープンソースの MapReduce アプリケーションの背景と HadoopMR プラグインの基本的な使い方を説明します。
MaxCompute は、ネイティブの MapReduce プログラミングモデルとインターフェイスのセットを提供しています。 これらのインターフェイスの入出力は、MaxCompute テーブルであり、データはレコード形式で処理されるように編成されます。
ただし、MaxCompute API は Hadoop フレームワーク用の API とは大きく異なります。 以前は、Hadoop MapReduce ジョブを MaxCompute に移行するには、まず、MapReduce コードを書き換え、MaxCompute API を使用してコードをコンパイルおよびデバッグし、最終コードを JAR パッケージに圧縮し、最後にそのパッケージを MaxCompute プラットフォームにアップロードする必要がありました。 このプロセスは面倒であり、開発とテストに多くの時間を費やす必要があります。 元の Hadoop MapReduce コードを部分的に変更する必要がない場合は、MaxCompute コンソールで実行するのが最善の方法です。
現在、MaxCompute プラットフォームは、Hadoop MapReduce コードを MaxCompute MapReduce 仕様に適合させることを可能にするプラグインを提供します。 MaxCompute は、Hadoop MapReduce ジョブのバイナリレベルの互換性に関して、ある程度の柔軟性を備えています。 つまり、コードを変更せずに、元の Hadoop MapReduce Jar パッケージを MaxCompute 上で直接実行するように設定できます。使い始めるには、開発プラグインをダウンロードしてください。 このプラグインは現在テスト段階にあるため、カスタムコンパレータやキー入力には対応していません。
次の例では、WordCount プログラムを使用したプラグインの基本的な使い方を説明します。
HadoopMR プラグインのダウンロード
Jar パッケージの準備
package com.aliyun.odps.mapred.example.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(final String [] args)throws IOException{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
テストデータの準備
- 入力テーブルと出力テーブルを作成します。
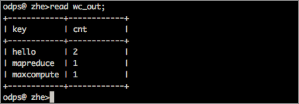
create table if not exists wc_in(line string); create table if not exists wc_out(key string, cnt bigint); - Tunnel コマンドを実行して、入力テーブルにデータをインポートします。
インポートする data.txt ファイル内のデータは、次のとおりです。
hello maxcompute hello mapreduceMaxCompute コンソールからTunnel コマンドを使用して data.txt から wc_in にデータをインポートします。tunnel upload data.txt wc_in;
テーブルと HDFS ファイルパスの間のマッピングの設定
{
"file:/foo": {
"resolver": {
"resolver": "com.aliyun.odps.mapred.hadoop2openmr.resolver.TextFileResolver",
"properties": {
"text.resolver.columns.combine.enable": "true",
"text.resolver.seperator": "\t"
}
},
"tableInfos": [
{
"tblName": "wc_in",
"partSpec": {},
"label": "__default__"
}
],
"matchMode": "exact"
},
"file:/bar": {
"resolver": {
"resolver": "com.aliyun.odps.mapred.hadoop2openmr.resolver.BinaryFileResolver",
"properties": {
"binary.resolver.input.key.class" : "org.apache.hadoop.io.Text",
"binary.resolver.input.value.class" : "org.apache.hadoop.io.LongWritable"
}
},
"tableInfos": [
{
"tblName": "wc_out",
"partSpec": {},
"label": "__default__"
}
],
"matchMode": "fuzzy"
}
}パラメーター
HDFS ファイルと MaxCompute テーブルの間のマッピング関係を記述する JSON ファイルで設定を行います。 通常、入力と出力の両方を設定する必要があります。 1 つの HDFS パスは、1 つのリゾルバ、テーブル情報、マッチモードに対応します。
- resolver: ファイルデータの処理メソッドを指定します。 現在、以下の 2 つのリゾルバから選択できます。com.aliyun.odps.mapred.hadoop2openmr.resolver.TextFileResolver
および com.aliyun.odps.mapred.hadoop2openmr.resolver.BinaryFileResolver リゾルバ名の他に、リゾルバのデータ解析に関する次のプロパティを設定します。
- TextFileResolver: データがプレーンテキストの場合、入力または出力をプレーンテキストとして設定します。 入力リゾルバを設定する際、 text.resolver.columns.combine.enable や text.resolver.seperator などのプロパティを設定します。 text.resolver.columns.combine.enable を true に設定すると、入力テーブルのすべての列は text.resolver.seperator で指定した区切り文字に基づいて、単一の文字列に結合されます。 それ以外の場合は、入力テーブルの最初の 2 列がキーと値として使用されます。
- BinaryFileResolver: バイナリデータを MaxCompute でサポートされている型 (Bigint、Boolean、Doubleなど) に変換します。 出力リゾルバを設定する際、プロパティ binary.resolver.input.key.class と binary.resolver.input.value.class で、中間結果のキーと値のデータ型をそれぞれ定義します。
- tableInfos: HDFS に対応する MaxCompute テーブルを指定します。 現在、tblName パラメーター (テーブル名) だけが設定可能です。 partSpec および label パラメーターは、この例のパラメーターに設定されている値と同じにする必要があります。
- matchMode: パスのマッチングモードを指定します。 完全一致モードは完全一致を示し、ファジーモードはファジーマッチを示します。 HDFS 入力パスと一致させるには、ファジーモードで正規表現を使用してください。
ジョブの送信
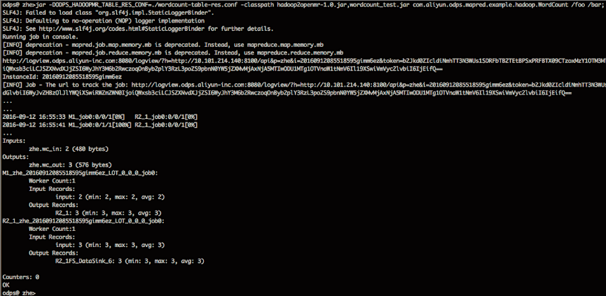
jar -DODPS_HADOOPMR_TABLE_RES_CONF=./wordcount-table-res.conf -classpath hadoop2openmr-1.0.jar,wordcount_test.jar com.aliyun.odps.mapred.example.hadoop.WordCount /foo/bar;- wordcount-table-res.conf は、/foo/bar が設定されたマップです。
- wordcount_test.jar は、Hadoop MapReduce の Jar パッケージです。
- com.aliyun.odps.mapred.example.hadoop.WordCount は、実行するジョブのクラス名です。
- /foo/bar は HDFS 上のパスを指し、JSON 構成ファイル内の wc_inとwc_out にマッピングされます。
- マッピング関係が設定されたら、DataX または DataWorks のデータ統合機能を使用して、MR 計算用に Hadoop HDFS 入力ファイルを wc_in に手動でインポートし、結果の wc_out を HDFS 出力ディレクトリ (/bar) に手動でエクスポートします。
- 上記の出力で、hadoop2openmr-1.0.jar、wordcount_test.jar、および wordcount-table-res.conf が、odpscmd の現在のディレクトリに格納されているとします。 エラーが発生した場合は、設定や -classpath を指定するときに、必要な変更を加えてください。