ここでは、Tunnel コマンド、MaxCompute Studio などを使用して MaxCompute にデータをインポートする方法について詳しく説明します。
MaxCompute では、次の方法でデータのインポートとエクスポートを実行できます。
- コンソール上で直接 Tunnel コマンドを実行。
- MaxCompute Studio での視覚的な方法。 詳細は、「データのインポートとエクスポート (Import and Export Data)」をご参照ください。
- Tunnel に実装されている SDK で作成した Java ツール。
- Flume プラグインと Fluentd プラグイン。
- DataWorks を介して、データのインポートとエクスポートを実行。 詳細は、「Data Integration 概要 (Data Integration Overview)」をご参照ください。
データのエクスポートについては、「Tunnelコマンド (Tunnel commands)」でダウンロードに関するコマンドをご参照ください。
Tunnel コマンド Tunnel コマンドを使用してデータをインポートするには、次の手順に従います。
- データを準備します。
この例では、ローカルファイル wc_example.txt が、ディレクトリ D:\odps\odps\ bin に保存されています。 コンテンツは以下のとおりです。
I LOVE CHINA! MY NAME IS MAGGIE. I LIVE IN HANGZHOU! I LIKE PLAYING BASKETBALL! - MaxCompute テーブルを作成します。
前ステップで作成したデータをインポートするには、MaxCompute テーブルを作成する必要があります。
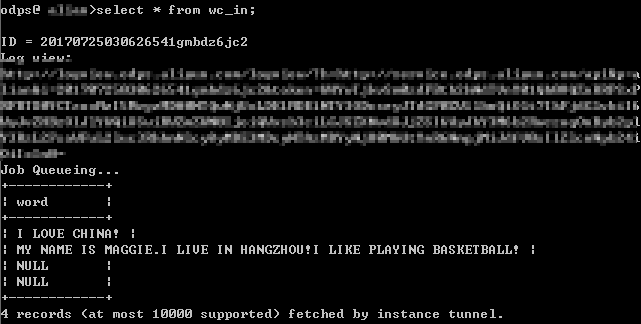
CREATE TABLE wc_in (word string); - Tunnel コマンドを実行します。
次のように Tunnel コマンドを実行し、MaxCompute コンソールにデータをインポートします。
tunnel upload D:\odps\odps\bin\wc_example.txt wc_in; - コマンドが正常に実行されたら、テーブル wc_in 内のレコードを確認します。
 注
注- パーティションテーブルへのデータのインポート方法を始めとした Tunnel コマンドの詳細は、「Tunnel 操作 (Tunnel Operation)」をご参照ください。
- テーブルに複数の列がある場合、-fd パラメーターを使用して、列の区切り文字を指定できます。

MaxCompute Studio によるデータインポート
MaxCompute Studio を使用してデータをインポートするには、次の手順に従います。 MaxCompute Studio の使用を開始する前に、MaxCompute Studio のインストールおよびプロジェクトスペース接続の設定が完了していることを確認してください。
- データを準備します。
この例では、ローカルファイル wc_example.txt が、ディレクトリ D:\odps\odps\bin に保存されています。 コンテンツは以下のとおりです。
I LOVE CHINA! MY NAME IS MAGGIE. I LIVE IN HANGZHOU! I LIKE PLAYING BASKETBALL! - MaxCompute テーブルを作成します。
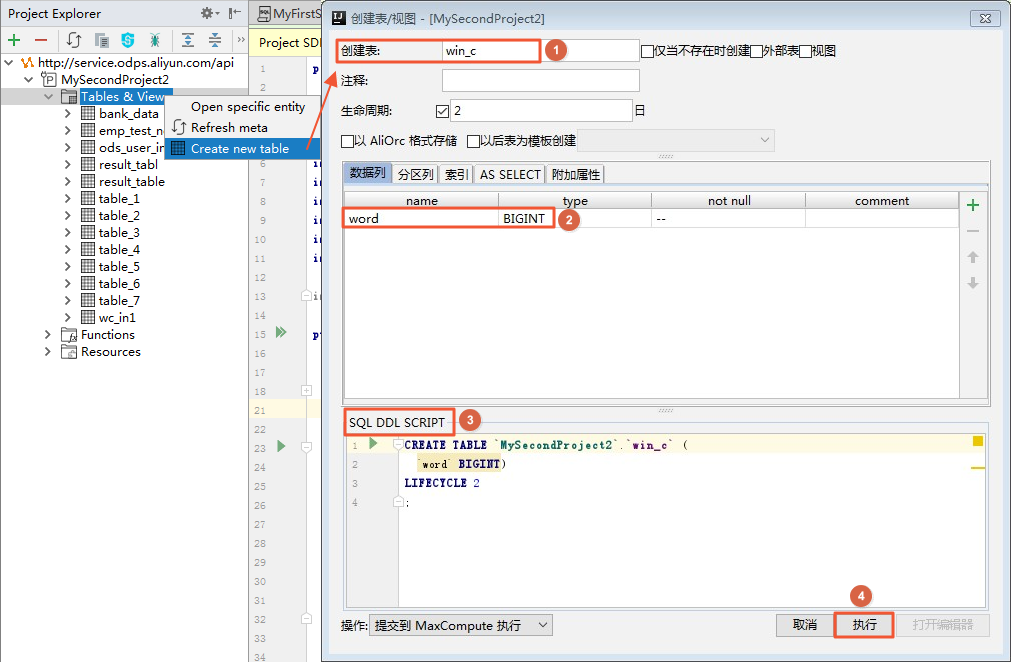
前ステップで作成したデータをインポートするには、最初に MaxCompute テーブルを作成する必要があります。 プロジェクトで [Tables&Views] を右クリックして、次のように操作します。文が正常に実行された場合、テーブルが作成されています。
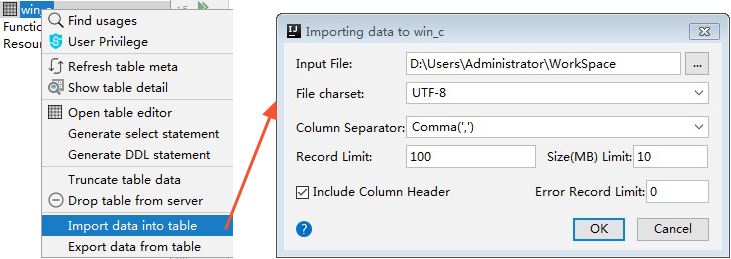
- データファイルをアップロードします。
[Tables&Views] 一覧で、新規に作成したテーブル wc_in を右クリックします。注 該当するテーブル名が一覧に表示されない場合は、 [refresh] ボタンをクリックします。


Tunnel SDK
以下は、Tunnel SDK を使用してデータをアップロードする方法を説明するためのシナリオ例です。
シナリオ
データを MaxCompute にアップロードします。プロジェクトは odps_public_dev、テーブル名は tunnel_sample_test、パーティションは pt=20150801、dt=Hangzhou です。
手順
- テーブルを作成し、該当するパーティションを追加します。
CREATE TABLE IF NOT EXISTS tunnel_sample_test( id STRING, name STRING) PARTITIONED BY (pt STRING, dt STRING); --Create a table. ALTER TABLE tunnel_sample_test ADD IF NOT EXISTS PARTITION (pt='20150801',dt='hangzhou'); --Add the partitions. - UploadSample プログラムのディレクトリ構造を以下のように作成します。
|---pom.xml |---src |---main |---java |---com |---aliyun |---odps |---tunnel |---example |---UploadSample.javaディレクトリの説明:- pom.xml: maven プログラムファイル。
- UploadSample: Tunnel ソースファイル。
- UploadSample プログラムを次のように作成します。
package com.aliyun.odps.tunnel.example; import java.io.IOException; import java.util.Date; import com.aliyun.odps.Column; mport com.aliyun.odps.Odps; import com.aliyun.odps.PartitionSpec; import com.aliyun.odps.TableSchema; import com.aliyun.odps.account.Account; import com.aliyun.odps.account.AliyunAccount; Import com. aliyun. ODPS. Data. record; import com.aliyun.odps.data.RecordWriter; import com.aliyun.odps.tunnel.TableTunnel; import com.aliyun.odps.tunnel.TunnelException; import com.aliyun.odps.tunnel.TableTunnel.UploadSession; public class UploadSample { private static String accessId = "####"; private static String accessKey = "####"; private static String tunnelUrl = "http://dt.odps.aliyun.com"; private static String odpsUrl = "http://service.odps.aliyun.com/api"; private static String project = "odps_public_dev"; private static String table = "tunnel_sample_test"; private static String partition = "pt=20150801,dt=hangzhou"; public static void main(String args[]) { Account account = new AliyunAccount(accessId, accessKey); Odps odps = new Odps(account); odps.setEndpoint(odpsUrl); odps.setDefaultProject(project); try { Tabletunnel tunnel = new tabletunnel (ODPS ); tunnel.setEndpoint(tunnelUrl); PartitionSpec partitionSpec = new PartitionSpec(partition); UploadSession uploadSession = tunnel.createUploadSession(project, table, partitionSpec); System.out.println("Session Status is : " + uploadSession.getStatus().toString()); TableSchema schema = uploadSession.getSchema(); RecordWriter recordWriter = uploadSession.openRecordWriter(0); Record record = uploadSession.newRecord(); for (int i = 0; i < schema.getColumns().size(); i++) { Column column = schema.getColumn(i); switch (column.getType()) { case BIGINT: record.setBigint(i, 1L); break; case BOOLEAN: record.setBoolean(i, true); Break; case DATETIME: record.setDatetime(i, new Date()); break; case DOUBLE: record.setDouble(i, 0.0); break; case STRING: record.setString(i, "sample"); break; default: throw new RuntimeException("Unknown column type: " + column.getType()); } } for (int i = 0; i < 10; i++) { recordWriter.write(record); } recordWriter.close(); UPR session. Commit (New long [] {0l }); System.out.println("upload success!") ; } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }注 ここでは、accesskeyid と accesskeysecret の設定は省略しています。 実際にアップロードを実行する際には、ご自身の情報に変更してください。 - pom.xml の設定は、次のようになります。
<? xml version="1.0" encoding="UTF-8"? > <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.aliyun.odps.tunnel.example</groupId> <artifactId>UploadSample</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-core</artifactId> <version>0.20.7-public</version> </dependency> </dependencies> <repositories> <repository> <id>alibaba</id> <name>alibaba Repository</name> <url>http://mvnrepo.alibaba-inc.com/nexus/content/groups/public/</url> </repository> </repositories> </project> - プログラムをコンパイルして実行します。
UploadSample プログラムをコンパイルします。
UploadSample プログラムを実行します。 ここでは、Eclipse を使用して Maven プロジェクトをインポートします。mvn package- Java プログラムを右クリックして、設定内容が、次のように表示されます。
- [UploadSample.java] を右クリックし、(下図)。
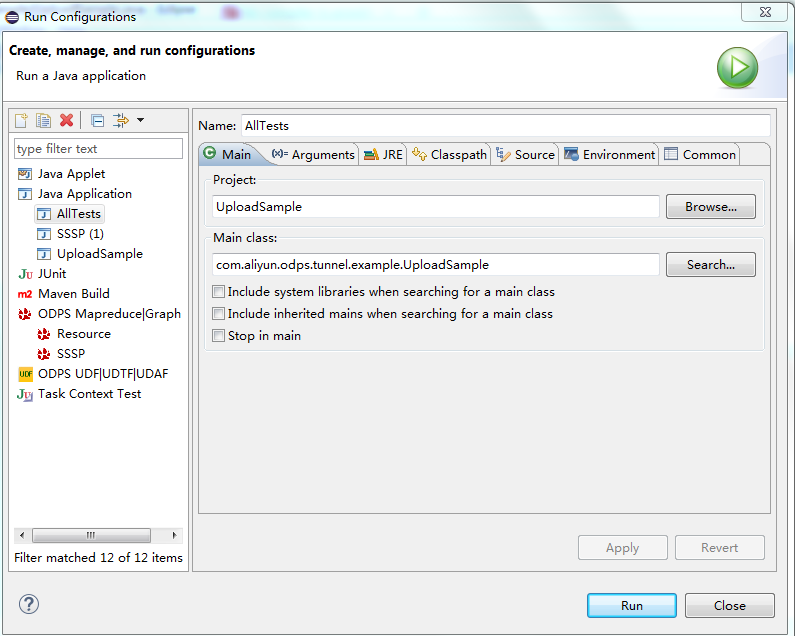
- [Run] をクリックします。
正常に実行されると、コンソールに次のようなメッセージが表示されます。
Session Status is : NORMAL upload success!
- Java プログラムを右クリックして、設定内容が、次のように表示されます。
- 実行結果を確認します。
コンソールに次の文を入力します。
select * from tunnel_sample_test;次のように実行結果が表示されます。+----+------+----+----+ | id | name | pt | dt | +----+------+----+----+ | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | | sample | sample | 20150801 | hangzhou | +----+------+----+----+注- MaxCompute の独立したサービスとして、Tunnel にはユーザー専用のアクセスポートがあります。 MaxCompute Tunnel サービスを使用し、Alibaba Cloud イントラネットを介してデータをダウンロードする場合は、ダウンロード操作により発生したトラフィックに対して、課金は発生しません。 イントラネットアドレスは、上海リージョン内のクラウドプロダクトに限り有効です。
- MaxCompute Alibaba イントラネット、およびパブリックネットワークのアクセスアドレスに関する詳細は、「ドメインとデータセンターへのアクセス (Access domains and data centers)」をご参照ください。


他のインポート方法
MaxCompute コンソールと Tunnel Java SDK に加え、Alibaba Cloud DTplus プロダクトの Sqoop、Fluentd、Flume、LogStash などのツールを使用してデータをインポートできます。