- Join 文の Where 条件2 つのテーブルを結合するときに、1 番目のテーブルの Where 条件は文の最後に記述しますが、2 番目のテーブルのパーティションの制限条件は Where 条件に記述しません。 ON 条件またはサブクエリに記述することを推奨します。 1 番目のテーブルのパーティション制限は Where 条件 (先にサブクエリでフィルタする方がよいです) に記載します。 以下にいくつかの SQL の例を示します。
select * from A join (select * from B where dt=20150301)B on B.id=A.id where A.dt=20150301; select * from A join B on B.id=A.id where B.dt=20150301; --Not allowed. select * from (select * from A where dt=20150301)A join (select * from B where dt=20150301)B on B.id=A.id;2 番目の SQL 文では Join 操作が最初に実行され、データ量が大きくなるため、パフォーマンスが低下する可能性があります。 そのため、2 番目の SQL 文は避けるべきです。
- データスキュー
データスキューの根本的な原因は、一部の Worker で処理されるデータ量が他の Worker のデータ量よりはるかに多いことです。 これは、一部の Worker の実行時間が平均よりも長いということなので、ジョブの遅延につながります。
.
- Join によって発生するデータスキューJoin キーの分散が不均等な場合は、Join 操作によってデータスキューが発生することがあります。 前述の例では、サイズが大きなテーブル A とサイズが小さなテーブル B を結合するために以下の文を実行します。
select * from A join B on A.value= B.value;logview リンクをコピーして Web コンソールページに移動し、Fuxi ジョブをダブルクリックして、Join 操作を実行します。 以下の図に示すように、[Long-Tails] タブでロングテールが表示され、これはデータスキューが発生していることを示します。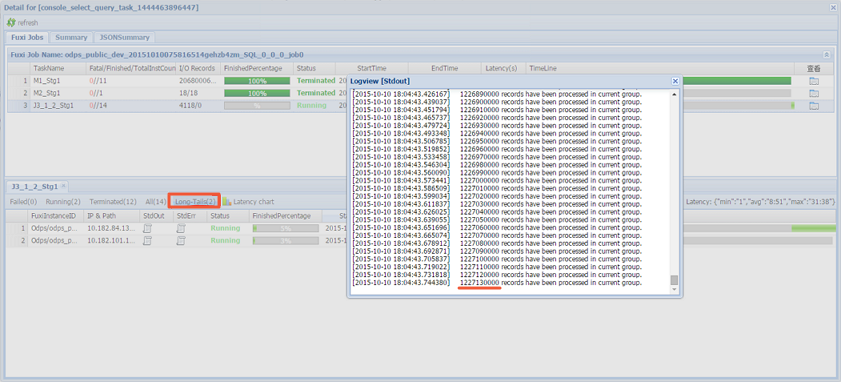 以下の方法で SQL 文を最適化します。
以下の方法で SQL 文を最適化します。- テーブル B はサイズが 512 MB 未満の小さなテーブルのため、mapjoin 文で前述の SQL 文を最適化できます。
select /*+ MAPJOIN(B) */ * from A join B on A.value= B.value; - スキューが発生したキーを別のロジックで処理します。 たとえば、両方のテーブルに多数の null キー値がある場合、たいていはデータスキューが発生します。null データをフィルタして除外するか、以下の例のように、Join
操作の前に乱数を追加する必要があります。
select * from A join B on case when A.value is null then concat('value',rand() ) else A.value end = B.value;
- テーブル B はサイズが 512 MB 未満の小さなテーブルのため、mapjoin 文で前述の SQL 文を最適化できます。
データスキューが発生したことを認識していても、原因がわからない場合は、一般的なソリューションを使用してデータスキューをテストできます。 以下の例をご参照ください。select * from a join b on a.key=b.key; --This Leads to data skew. Now you can run the following statements: ```sql select left.key, left.cnt * right.cnt from (select key, count(*) as cnt from a group by key) left join (select key, count(*) as cnt from b group by key) right on left.key=right.key;A と B を結合するときにデータスキューが発生しているかどうかを確認するには、キーの分散を確認します。
- Join によって発生するデータスキュー
- Group by によって発生するデータスキュー
group by キーの分散が不均等な場合は、Group by によってデータスキューが発生することがあります。
テーブル A には、key と value の 2 つのフィールドがあるとします。 テーブルのデータ量は大きく、キーの分散は不均等です。 以下の SQL 文を実行します。select key,count(value) from A group by key;Web コンソールページでロングテールを確認します。 この問題を解決するためには、SQL 文を実行する前にスキュー対策のパラメータを設定する必要があります。
set odps.sql.groupby.skewindata=trueを SQL 文に追加する必要があります。 - 動的パーティションの誤った使用によるデータスキューMaxCompute の SQL の動的パーティションでは、デフォルトで Reduce 関数が追加されます。Reduce 関数は同じパーティションデータをマージするために使用されます。 利点は以下のとおりです。
- MaxCompute によって生成される小さなファイルが減り、処理効率が良くなります。
- Worker が多数のファイルを出力するときに、メモリの占有領域が減少します。
パーティションデータのスキューが発生する場合、Reduce 関数はロングテールが発生する原因となります。 同じデータを処理できる Worker は最大 10 なので、大量のデータはロングテールの原因となります。以下に例を示します。insert overwrite table A2 partition(dt) select split_part(value,'\t',1) as field1, split_part(value,'\t',2) as field2, dt from A where dt='20151010';この場合、動的パーティションを使用せず、以下の方法で SQL 文を変更することを推奨します。insert overwrite table A2 partition(dt='20151010') select split_part(value,'\t',1) as field1, split_part(value,'\t',2) as field2 from A where dt='20151010'; - Window 関数の最適化SQL 文で Window 関数を使用する場合、通常、Window 関数では Reduce ジョブを作成します。 Window 関数が多すぎる場合は、リソースが消費されます。 特定のシナリオでは、Window 関数を最適化します。
- グループ化条件およびソート条件と同じように、over キーワードの後ろの内容は同じにする必要があります。
- 複数の Window 関数は同じ SQL レイヤーで実行される必要があります。
これら 2 つの条件を満たす Window 関数を Reduce の実装にマージします。 SQL の例は以下のとおりです。select rank()over(partition by A order by B desc) as rank, row_number()over(partition by A order by B desc) as row_num from MyTable; - サブクエリの Join への変換サブクエリは以下のとおりです。
SELECT * FROM table_a a WHERE a.col1 IN (SELECT col1 FROM table_b b WHERE xxx);この SQL 文の table_b サブクエリによって返された col1 の数が 1,000 を超える場合は、システムでは以下のエラーが表示されます。rrecords returned from subquery exceeded limit of 1,000この場合は、代わりに Join 文を使用します。SELECT a. * FROM table_a a JOIN (SELECT DISTINCT col1 FROM table_b b WHERE xxx) c ON (a.col1 = c.col1)注- SQL 文に Distinct キーワードがなく、サブクエリ c の結果が同じ col1 の値を返す場合は、table_a の結果の数が多くなる可能性があります。
- Distinct サブクエリでは、クエリ全体が 1 Worker に割り当てられる可能性があります。 サブクエリのデータが大きい場合は、クエリ全体の速度が低下する原因になる可能性があります。たとえば、プライマリーキーフィールドを照会することで、サブクエリの col1 の値が重複しないことが明らかな場合は、Distinct キーワードを削除することだけが、パフォーマンスを改善する可能性があります。
- たとえば、プライマリーキーフィールドを照会することによって、サブクエリの col1 の値が重複しないことをすでに確認している場合は、パフォーマンスを改善するために、Distinct キーワードを削除します。
